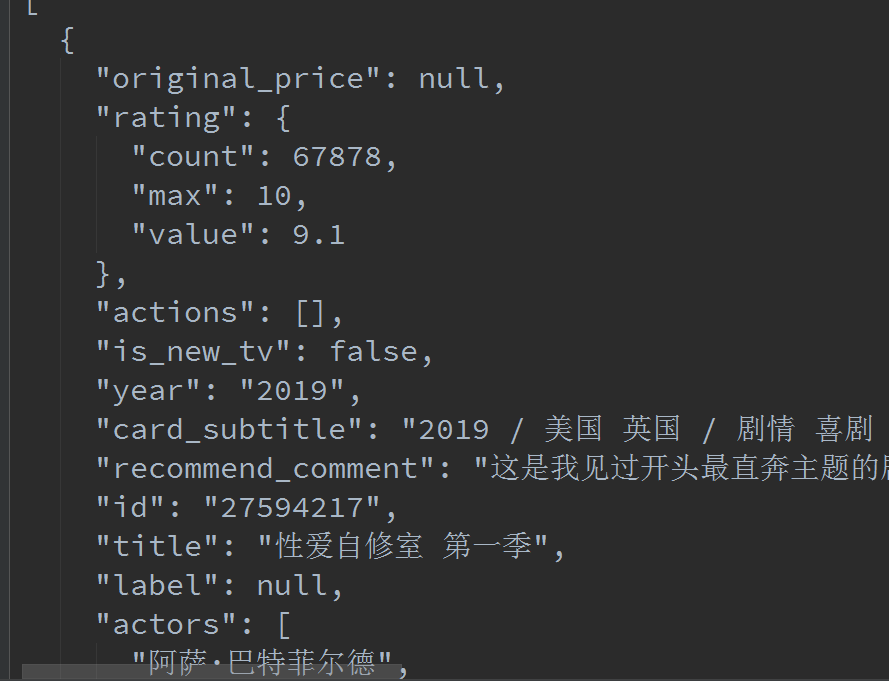
pc版大概有500条记录,mobile大概是50部,只有热门的,所以少一点
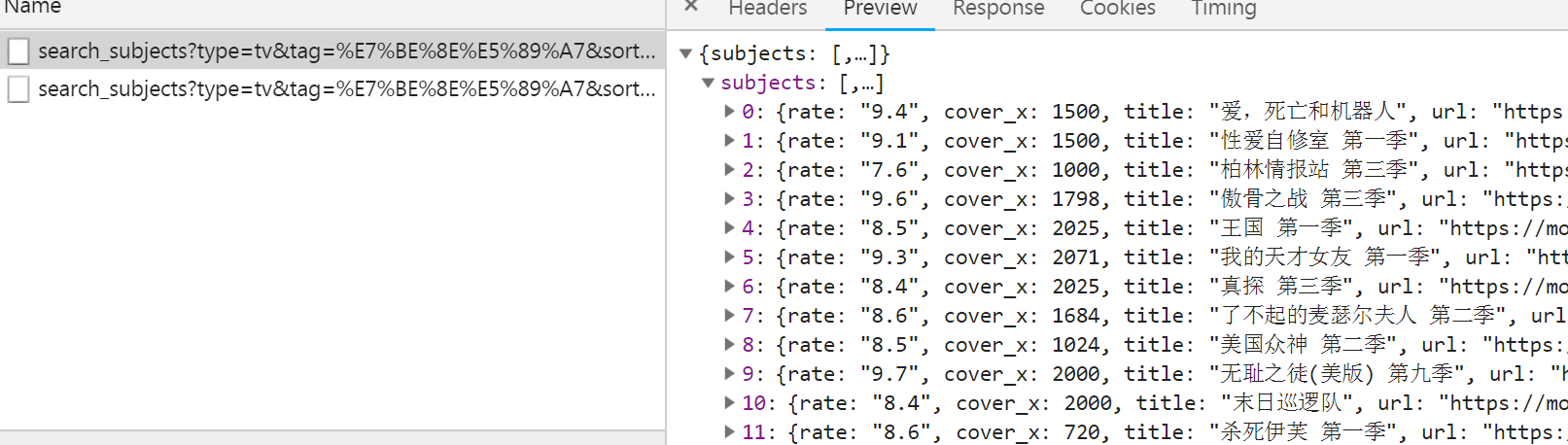

url构造很简单,主要参数就是page_limit与page_start,每翻一页,start+=20即可,tag是"美剧"编码后的结果,直接带着也可以,用unquote解码也可以,注意headers中一定要带上refer
1 import json
2 import requests
3 import math
4 import os
5 import shutil
6 from pprint import pprint
7 from urllib import parse
8
9
10 class DoubanSpliderPC:
11 def __init__(self):
12 self.url = parse.unquote(
13 "https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}")
14
15 self.headers = {
16 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
17 "Referer": "https://movie.douban.com/tv/"
18 }
19 self.file_dir = "./douban_american_pc.txt"
20
21
22 def parse_url(self):
23 number = 0
24 while True:
25 url = self.url.format(number)
26 print(url)
27 response = requests.get(url, headers=self.headers)
28 response_dict = json.loads(response.content.decode())
29 subjects_list = response_dict["subjects"]
30 with open(self.file_dir, "a", encoding="utf-8") as file:
31 for subject in subjects_list:
32 file.write(json.dumps(subject, ensure_ascii=False))
33 file.write("
")
34 if len(subjects_list) < 20:
35 break
36 number += 20
37
38 def run(self):
39 # 删除之前保存的数据
40 if os.path.exists(self.file_dir):
41 os.remove(self.file_dir)
42 print("文件已清空")
43 self.parse_url()
44
45
46 def main():
47 splider = DoubanSpliderPC()
48 splider.run()
49
50 if __name__ == '__main__':
51 main()
moblie类似,不过抓包的时候找那个Item就可以了
1 import json
2 import requests
3 import math
4 import os
5 import shutil
6 from pprint import pprint
7
8
9 # 爬取豆瓣的美剧页面(手机版只有50条)
10 class DouBanSpliderMobile:
11 pageCount = 18
12 total = None
13
14 def __init__(self):
15 self.first_url = "https://m.douban.com/rexxar/api/v2/subject_collection/tv_american/items?os=ios&for_mobile=1&start={}&count=18&loc_id=108288&_=1552995446961"
16 self.headers = {
17 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
18 "Referer": "https://m.douban.com/tv/american"
19 }
20 self.file_dir = "./douban_american_mobile.txt"
21
22 def get_url_list(self):
23 url_list = []
24 for i in range(math.ceil(DouBanSpliderMobile.total / DouBanSpliderMobile.pageCount)):
25 url = self.first_url.format(i * 18)
26 url_list.append(url)
27 return url_list
28
29 def parse_url(self, url):
30 response = requests.get(url, headers=self.headers)
31 response_dict = json.loads(response.content.decode())
32 DouBanSpliderMobile.total = int(response_dict["total"])
33 with open(self.file_dir, "a", encoding="utf-8") as file:
34 json.dump(response_dict["subject_collection_items"], file, ensure_ascii=False, indent=2)
35
36 def run(self):
37 # 解析第一个url,获取total
38 self.parse_url(self.first_url.format(0))
39 url_list = self.get_url_list()
40
41 # 删除之前保存的文件
42 if os.path.exists(self.file_dir):
43 os.remove(self.file_dir)
44
45 for url in url_list:
46 self.parse_url(url)
47
48 def main():
49 douban_splider = DouBanSpliderMobile()
50 douban_splider.run()
51
52
53 if __name__ == '__main__':
54 main()