原文链接:http://tecdat.cn/?p=6236
ROC 曲线可能是评估评分分类器的预测性能的最常用的度量。
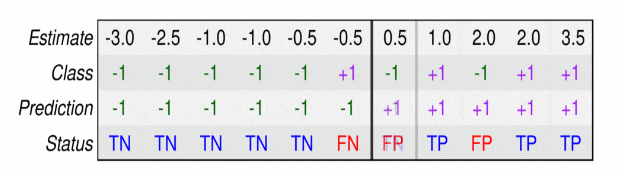
预测正类(+1)和负类(-1)的分类器的混淆矩阵具有以下结构:
| 预测/参考类 | +1 | -1 |
|---|---|---|
| +1 | TP | FP |
| -1 | FN | TN |
这里,TP表示真阳性的数量(模型正确预测正类),FP表示误报的数量(模型错误地预测正类),FN表示假阴性的数量(模型错误地预测阴性类),TN表示真阴性的数量(模型正确预测阴性类)。
ROC曲线
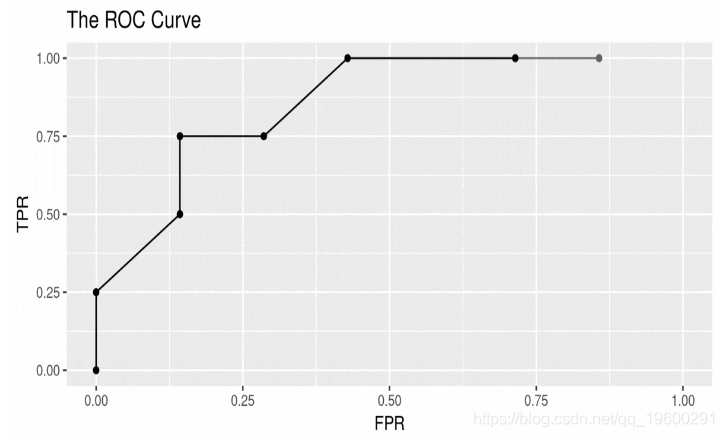
![]()
![]()
plot.scores.AUC <- function (y, y.hat, measure = "tpr" , x.measure = "fpr" ) {
par(mfrow=c( 1 , 2 ))
hist(y.hat[y == 0 ], col=rgb( 1 , 0 , 0 , 0.5 ),
main = "Score Distribution" ,
breaks=seq(min(y.hat),max(y.hat)+ 1 , 1 ), xlab = "Prediction" )
hist(y.hat[y == 1 ], col = rgb( 0 ,<span style="color:#880000">0</span>,<span style="color:#880000">1</span>,<span style="color:#880000">0.5</span>), add=<span style="color:#78a960">T</span>,
breaks=seq(min(y.hat),max(y.hat) + <span
# plot ROC curve</span>
pr <- prediction(y.hat, y)
prf <- performance(pr, measure = measure, x.measure = x.measure)
auc <- performance(pr, measure = <span style="color:#880000">"auc"</span>)@y.values[
plot(prf, main = "Curve (AUC: " AUC是完美的分类器
理想的分类器不会产生任何预测错误。这意味着分类器可以完美地分离这两个类,使得模型在产生任何误报之前实现100%的真正正率。因此,这种分类器的AUC是1,例如:
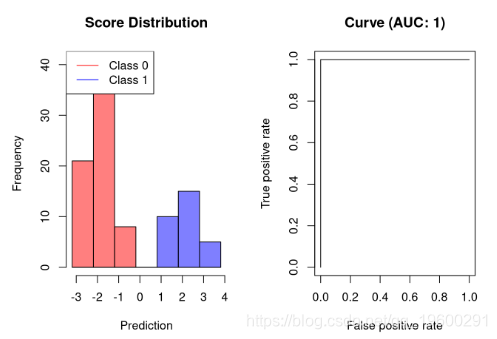
![]()
AUC是一个很好的分类器
将两个类分开但不完美的分类器看起来像这样:
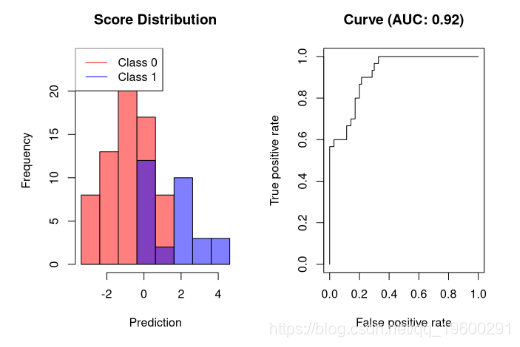
![]()
可视化分类器能够在非常低的FPR下获得60%的灵敏度。
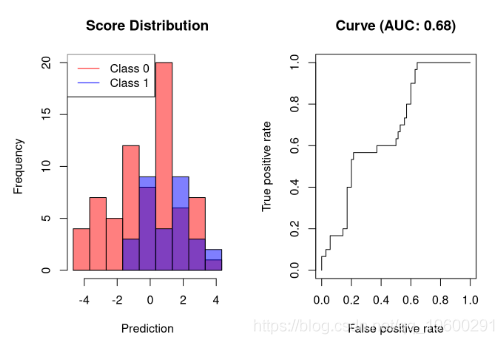
坏分类器的AUC
错误的分类器将输出其值仅与结果稍微相关的分数。这样的分类器将仅以高FPR为代价达到高TPR。
![]()
只有在大约40%的FPR下,可视化分类器才能达到60%的灵敏度,这对于应该具有实际应用的分类器来说太高了。
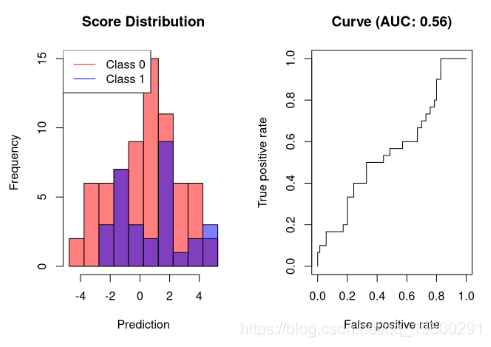
随机分类器的AUC
随机分类器的AUC接近0.5。这很容易理解:对于每个正确的预测,下一个预测都是不正确的。
![]()
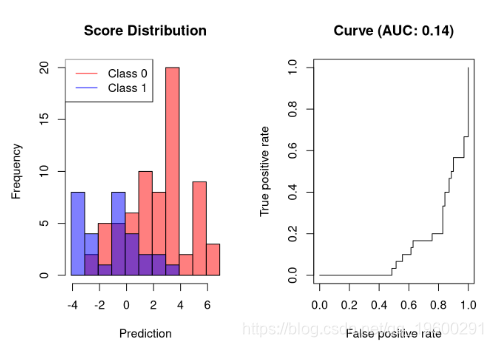
分类器的AUC表现比随机分类器差
[0.5,1][0.5,1]
![]()
可视化分类器在达到20%以上的灵敏度之前产生80%的FPR。
AUC-PR曲线
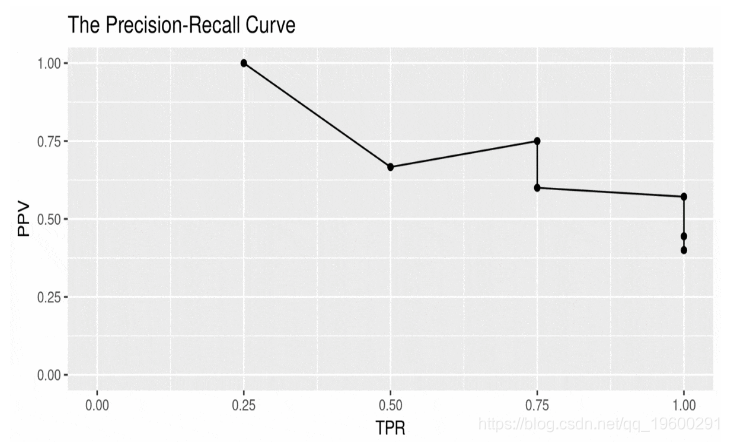
精确回忆曲线绘制阳性预测值(PPV,y轴)与真阳性率(TPR,x轴)。这些数量定义如下:
precisionrecall=PPV=TPTP+FP=TPR=TPTP+FNprecision=PPV=TPTP+FPrecall=TPR=TPTP+FN
例如,请考虑以下数据集:
![]()

![]()
在下文中,我将演示 AUC-PR 下的面积如何受预测性能的影响。
AUC-PR是完美的分类器
理想的分类器不会产生任何预测错误。因此,它将获得1的AUC-PR:
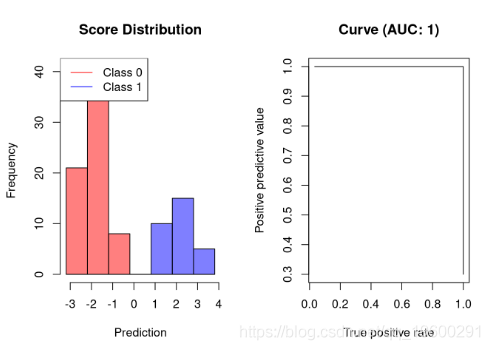
![]()
AUC-PR是一个好的分类器
将两个类分开但不完美的分类器将具有以下精确回忆曲线: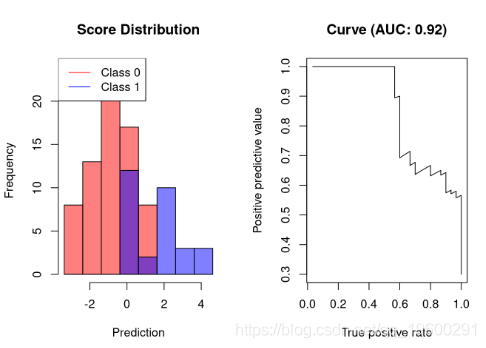
![]()
可视化分类器在没有任何错误的正面预测的情况下达到约50%的召回率。
坏分类器的AUC-PR
错误的分类器将输出其值仅与结果稍微相关的分数。这样的分类器只能以低精度达到高召回率: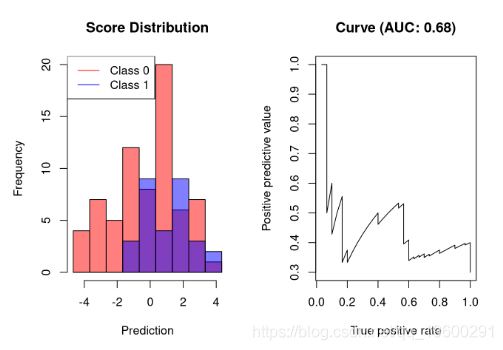
![]()
召回率仅为20%时,分级机的精度仅为60%。
随机分类器的AUC-PR
随机分类器的AUC-PR接近0.5。这很容易理解:对于每个正确的预测,下一个预测都是不正确的。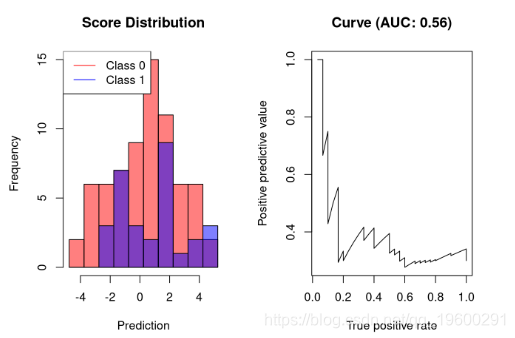
![]()
AUC-PR的分类器比随机分类器表现更差