原文链接:http://tecdat.cn/?p=4698
介绍
顾名思义,排队论是对用于预测队列长度和等待时间的长等待线的研究。这是一种流行的理论,主要用于运营,零售分析领域。
到目前为止,我们已经解决了传入呼叫量和呼叫持续时间事先已知的情况。在现实世界中,情况并非如此。在现实世界中,我们需要假设到达率和服务率的分布并相应地采取行动。
到货率仅仅是客户需求的结果,公司无法控制这些需求。另一方面,服务费率在很大程度上取决于有多少来电者代表可以服务,他们的表现如何以及他们的日程安排如何优化。
在本文中,我将使用排队理论让您更接近实际操作分析。我们还将解决几个问题,我们在之前的文章中以简单的方式回答了这些问题。

![]()
目录
- 什么是排队论?
- 排队论中使用的概念
- 肯德尔的记谱法
- 感兴趣的重要参数
- 小定理
- 案例研究1使用R
- 案例研究2使用R.
什么是排队论?
如上所述,排队理论是对用于估计队列长度和等待时间的长等待线的研究。它使用概率方法进行运筹学,计算机科学,电信,交通工程等领域的预测。
排队论最早是在20世纪初实施的,用于解决电话呼叫拥堵问题。因此,它不是任何新发现的概念。如今,沃达丰,Airtel,沃尔玛,AT&T,Verizon等公司正大量使用这一概念,以便为未来的流量做好准备。
让我们现在深入研究这个理论。我们现在将理解一个称为肯德尔符号和小定理的排队理论的重要概念。
感兴趣的参数
排队模型使用多个参数。这些参数有助于我们分析排队模型的性能。想想我们可以感兴趣的所有因素是什么?以下是我们对任何排队模型感兴趣的一些参数:
- 系统中没有客户的概率
- 系统中没有队列的概率
- 新客户进入系统后直接获得服务器的可能性
- 系统中不允许新客户的概率
- 队列的平均长度
- 系统中的平均人口
- 平均等待时间
- 系统中客户的平均时间
小定理
这是一个有趣的定理。让我们用一个例子来理解它。
考虑具有 实际进入系统的平均到达率λ的过程的队列 。设 N 是系统中作业(客户)的平均数(等待和服务), W 是系统中作业(等待和服务)所花费的平均时间。
然后,Little的结果表明这些数量将彼此相关:
N = λ w ^
这个定理非常方便地得出给定系统队列长度的等待时间。
4个最简单系列的参数:
1. M / M / 1 /∞/∞
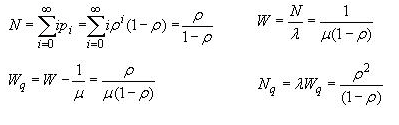
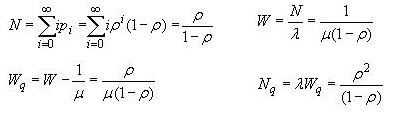
![]()
这里,N和Nq分别是系统和队列中的人数。W和Wq分别是系统和队列中的等待时间。Rho是到达率与服务率的比率。概率也可以如下:
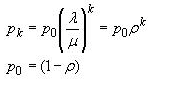
![]()
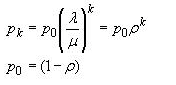
其中,p0是系统中零人的概率,pk是系统中k人的概率。
2. M / M / 1 /∞/∞排队 :
这是常见的分布之一,因为如果队列长度增加,到达率会下降。想象一下,你去了必胜客在美食广场举办比萨派对。但队列太长了。你可能会因为期待很长的等待时间而吃其他东西。
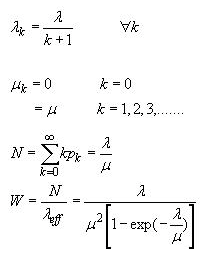
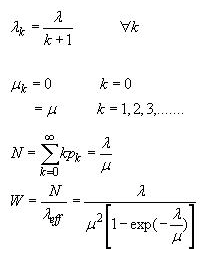
![]()

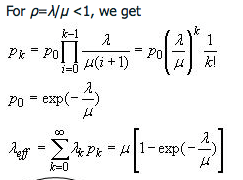
![]()
如您所见,到达率随着k的增加而减少。
3. M / M / c /∞/∞
使用c服务器,方程变得更加复杂。以下是到达和服务时这种马尔可夫分布的表达式。
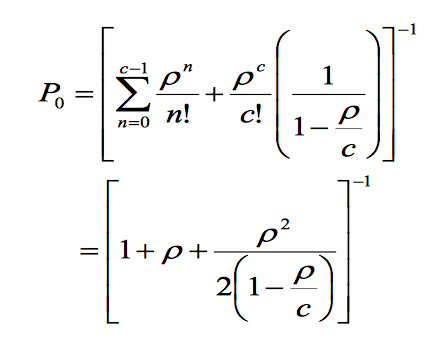
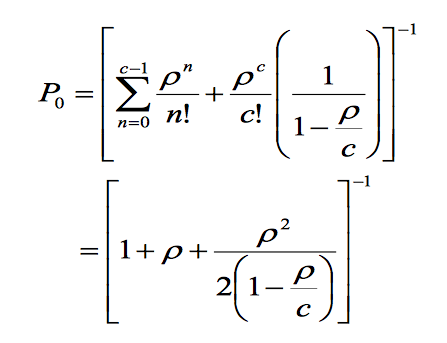
![]()
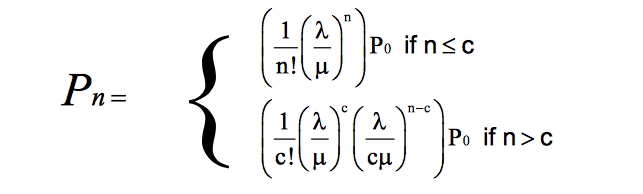
![]()
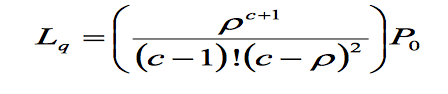
![]()
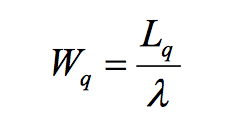
![]()
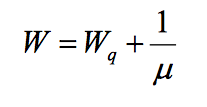
![]()
案例研究1
想象一下,你在一家多国家银行工作。您有责任设置整个呼叫中心流程。您需要与呼叫中心联系并告诉他们您需要的服务器数量。
您正在为客户的特定功能查询设置此呼叫中心,该客户在一小时内有大约20个查询。每个查询大约需要15分钟才能解决。找出所需的服务器/代表数量,将平均等待时间缩短至不到30秒。
解
给定的问题是具有以下参数的M / M / c类型查询。
Lambda = 20
Mue = 4
这是一个R代码,可以找出每个服务器/代表数量值的等待时间。
> Lambda < - 20
> Mue < - 4
> Rho < - Lambda / Mue#
创建一个空矩阵
#创建一个函数而不是可以找到等待时间
> calculatewq < - {
P0inv < - Rho ^ c /(factorial(c)*(1-(Rho / c)))
P0inv = P0inv +(Rho ^ i)/ factorial(i)
}
Wq = 60 * Lq / Lambda
Ls < - Lq + Rho
Ws < - 60 * Ls / Lambda
a < - cbind(Lq, Wq,Ls,Ws)
}
#Now用等待时间的每个值填充矩阵
> for(i in 1:10){
matrix [i,2] < - calculatewq(i)[2]
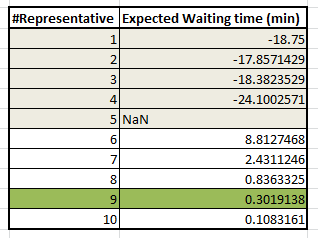
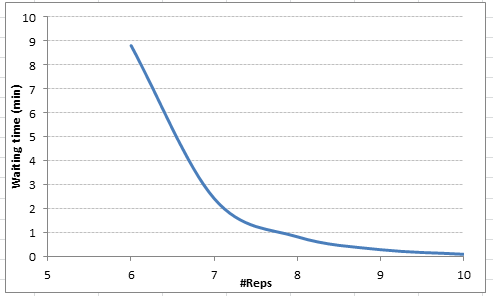
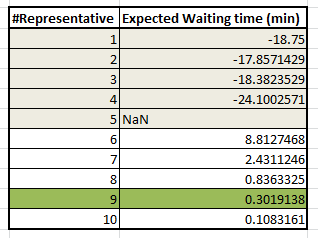
}以下是我们等待时间的值:
![]()
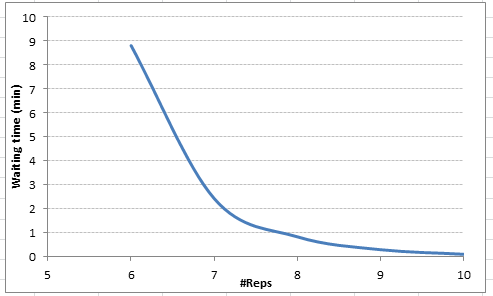
![]()
等待时间的负值意味着参数的值不可行,并且我们有一个不稳定的系统。很明显,9 Reps,我们的平均等待时间降至0.3分钟。
案例研究2
让我们来看一个更复杂的例子。
想象一下,您是银行分行的运营官。您的分支机构最多可容纳50名客户。如果客户以100客户/小时的速度进入并且出纳员在3分钟内解决查询,您需要多少柜员?
您需要确保能够容纳超过99.999%的客户。这意味着只有不到0.001%的客户应该在没有进入分支机构的情况下返回,因为brach已经有50个客户。还要确保等待时间少于30秒。
解
这是一种“M / M / c / N = 50 /∞”类型的队列系统。不要担心这种复杂系统的队列长度公式(直接使用此代码中给出的那个)。只关注我们如何能够在这种有限队列长度系统中找到没有解决方案的客户离开的概率。
这是R代码
> Lambda < - 100
> Mue < - 20
> Rho < - Lambda / Mue
> N < - 50
> calculatewq(6)
> calculatewq < - (c){
for(i in 1:c-1){
P0inv = P0inv +(Rho ^ i)/ factorial(i)
}
P0 = 1 / P0inv
Wq = 60 * Lq / Lambda
Ls < - Lq + Rho
Ws < - 60 * Ls / Lambda
a < - cbind(Lq,Wq,Ls,Ws,customer_serviced)
return(a)
}
> for(i in 1:100){
matrix [i,2] < - calculatewq(i)[2]
}
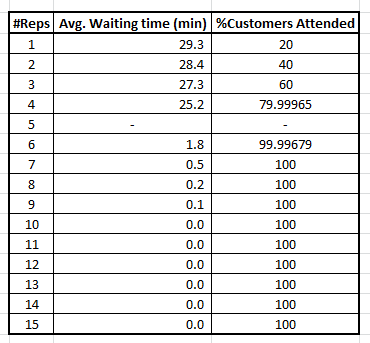
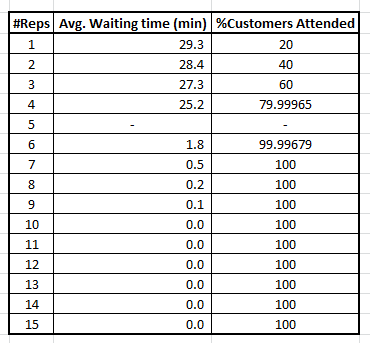
![]()
显然,您需要更多7个代表来满足客户离开时出现的问题