无监督学习研究的是在不知道目标类别的情况下如何进行数据挖掘的问题,它偏于探索,发现隐藏在数据中的信息。
kmeans算法就是典型的无监督学习算法。
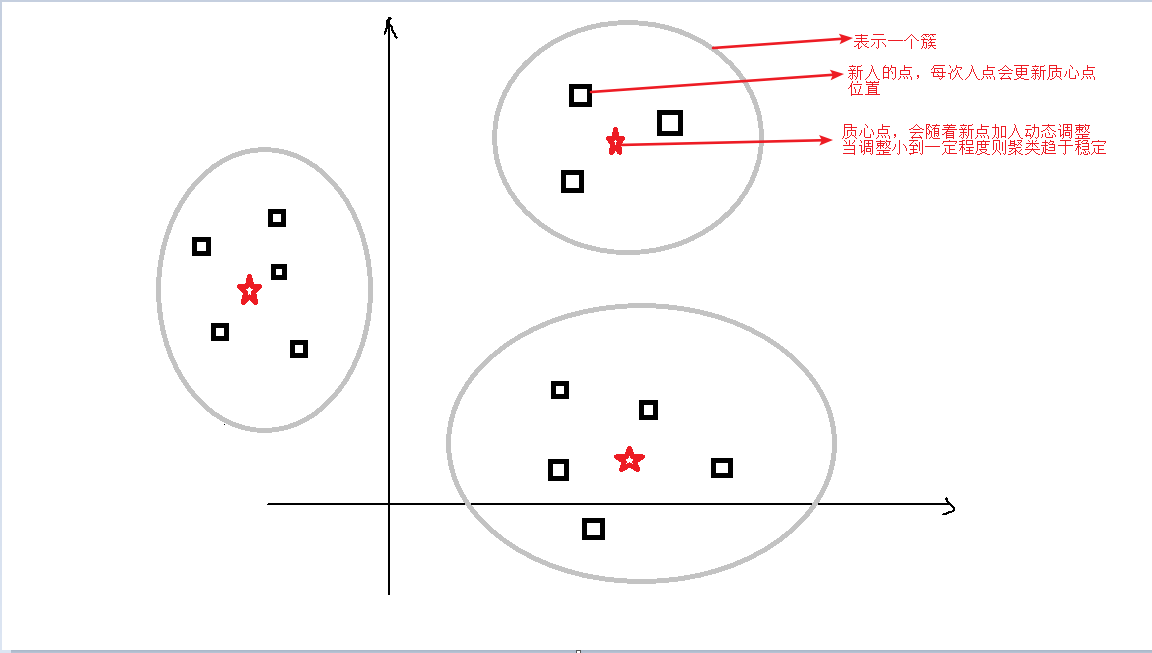
它的操作过程如下:
1)最初随机选取k个质心点
2)通过计算新的点与质心点的距离,找到距离最近的那个簇,将新的点分配到最近的那个簇
3)调整更新各簇的质心点
4)重复2)3)当迭代到一定次数,质心点移动量很小,簇就趋于稳定,则停止
python的sklearn库实现了kmeans算法,我也写个例子吧!
用的是某app群组消息数据,首先获取数据并清洗。因为后面会用到TfidfVectorizer特征提取工具,而TfidfVectorizer在做中文提取词语时,是以空格隔开的,因此,在数据清洗时我就已经使用jieba库做好了分词,并传入TfidfVectorizer喜欢的带有空格的文本格式,代码如下:
import re
import json
import math
import jieba
from elasticsearch5 import Elasticsearch
# 一、找群
# 1. 必须至少1万条消息
es = Elasticsearch(['172.16.100.6', '172.16.100.7', '172.16.100.8'])
ret = es.search(index="group_channel_entity", body={"query": {"bool": {"must": [{"range": {"msg_cnt": {"gt": 10000}}}]}}}, params={"_source": "uid"}, size=1500)
id_lis = []
for i in ret['hits']['hits']:
id_lis.append(i["_source"]["uid"])
# 二、构建大列表,列表存放不同群的消息文本
# 1.存100条消息
# 2.消息是中文文本
# 3.消息不重复
mdic = {}
msg_lis = []
for uid in id_lis:
if len(mdic) >= 500: # 找满500个群组
break
msgs = set()
ret = es.search(index="app_chatinfo_01,app_chatinfo_02",
body={"query": {"bool": {"must": [{"term": {"to": uid}}, {"term": {"msgtype": "text"}}]}}},
params={"_source": "msg"}, size=1000,
scroll="5m", request_timeout=120)
result = ret["hits"]["hits"]
for rec in result:
if len(msgs) >= 100:
is_full = True
break
msg = rec["_source"]["msg"]
if any(["http" in msg, ".com" in msg, ".cn" in msg]):
continue
if len(msg) < 5:
continue
msgs.add(msg)
pages = math.ceil(ret["hits"]["total"] / 1000) - 1
scroll_id = ret["_scroll_id"]
for page in range(pages):
if len(msgs) >= 100:
break
ret = es.scroll(scroll_id=scroll_id, scroll='5m', request_timeout=120)
for rec in ret["hits"]["hits"]:
if len(msgs) >= 100:
is_full = True
break
msg = rec["_source"]["msg"]
if any(["http" in msg, ".com" in msg, ".cn" in msg]):
continue
if len(msg) < 5:
continue
msgs.add(msg)
if len(msgs) < 80:
continue
msgs = list(msgs)
# 若非中文比例超过40%,则跳过
mtxt = ''.join(msgs)
if len(re.findall('(?![u4e00-u9fa5]).', mtxt)) / len(mtxt) > 0.40:
continue
mdic[uid] = msgs
print(uid, len(msgs))
msg_lis.append(' '.join(msgs))
json.dump(mdic, open("group_msg.json", "w", encoding="utf-8"), ensure_ascii=False)
print(len(mdic))
# 三、将中文文本分词,空格隔开,转成TfidfVectorizer可识别格式
sw = json.load(open("stopword.json", "r", encoding="utf-8"))
data = json.load(open("group_msg.json", "r", encoding="utf-8"))
lis = [' '.join(data[i]) for i in data]
msg_words = []
group_id_lis = []
count = 0
for i in data:
tl = []
msgs = data[i]
for j in msgs:
d = jieba.cut(j)
for k in d:
if k in sw:
continue
tl.append(k)
count += 1
group_id_lis.append(i)
msg_words.append(' '.join(tl))
print(' '.join(tl))
print(len(msg_words))
json.dump(group_id_lis, open("group_id.json", "w", encoding="utf-8"), ensure_ascii=False)
json.dump(msg_words, open("msg_words.json", "w", encoding="utf-8"), ensure_ascii=False)
接下来就可以进行数据挖掘工作了。
每个点到质心点的距离是算法的惯性权重(inertia),随着簇不断增加,虽然惯性权重低了,但是类别太多,算法也就失去聚类意义,因此,要找到合适的簇数量。因为群消息非常杂,各方面都有,所以我最低限定6个簇,接下来,我给一个簇的范围,设定不同的簇数量训练模型,得到inertia值,通过可视化,直观的看到inertia的变化趋势,代码如下:
import json
from sklearn import pipeline
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import TfidfVectorizer
from collections import Counter
train_data = json.load(open("msg_words.json", "r", encoding="utf-8"))
inertia_scores = []
n_cluster_values = list(range(6, 30))
for n_cluster in n_cluster_values:
X = TfidfVectorizer(max_df=0.4).fit_transform(train_data)
km = KMeans(n_clusters=n_cluster).fit(X)
print(km.inertia_)
inertia_scores.append(km.inertia_)
import matplotlib.pyplot as plt
plt.plot(list(range(6, 30)), inertia_scores)
plt.show()
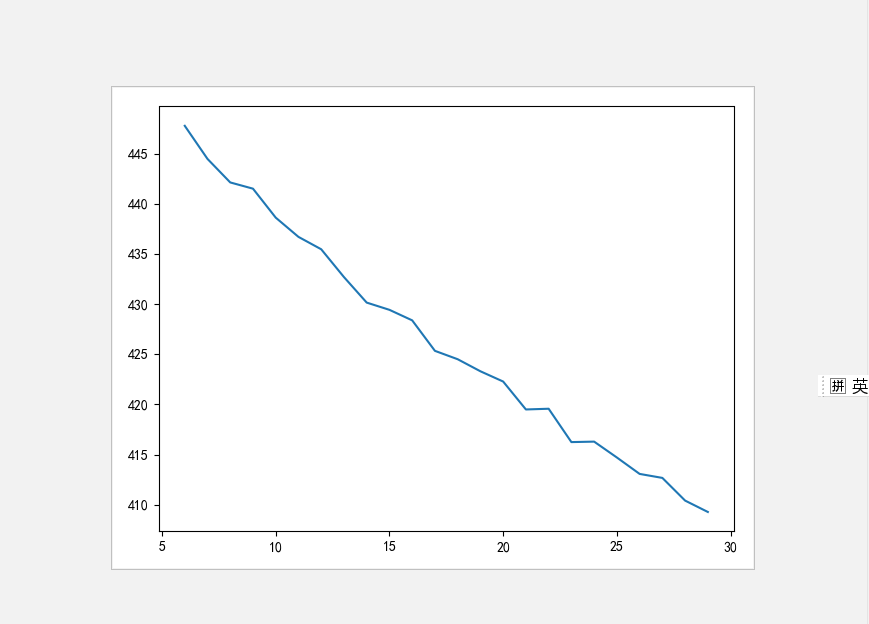
通过观察图,发现,最后一次大调整发生在簇为16的时候,因此认为簇数16是是比较稳定的。
将簇值设置为16,再次训练模型,并查看分组结果,代码如下:
import json
from sklearn import pipeline
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import TfidfVectorizer
from collections import Counter
train_data = json.load(open("msg_words.json", "r", encoding="utf-8"))
pipeline = pipeline.Pipeline([
("fe", TfidfVectorizer(max_df=0.4)),
("cluster", KMeans(n_clusters=16))
])
pipeline.fit(train_data)
labels = pipeline.predict(train_data)
terms = pipeline.named_steps["fe"].get_feature_names()
c = Counter(labels)
for n in range(16):
print(f'cluster {n} contains {c[n]} samples')
print("### Most Important Terms ###")
centroid = pipeline.named_steps["cluster"].cluster_centers_[n]
most_import = centroid.argsort()
for i in range(5):
term_index = most_import[-(i+1)]
print(f'{i+1} {terms[term_index]} (score: %.2f)' % centroid[term_index])
部分打印如下:
### Most Important Terms ### 1 老婆 (score: 0.04) 2 喜欢 (score: 0.04) 3 我要 (score: 0.03) 4 兄弟 (score: 0.03) 5 感觉 (score: 0.03) cluster 1 contains 23 samples ### Most Important Terms ### 1 usdt (score: 0.11) 2 资金 (score: 0.10) 3 代收 (score: 0.07) 4 现金 (score: 0.07) 5 同台 (score: 0.07) cluster 2 contains 20 samples ### Most Important Terms ### 1 eth (score: 0.17) 2 ht (score: 0.11) 3 套利 (score: 0.09) 4 合约 (score: 0.08) 5 置换 (score: 0.08) cluster 3 contains 65 samples ### Most Important Terms ### 1 精准 (score: 0.06) 2 棋牌 (score: 0.06) 3 实名 (score: 0.06) 4 短信 (score: 0.05) 5 tg (score: 0.05) cluster 4 contains 17 samples ### Most Important Terms ### 1 群群 (score: 0.14) 2 美刀 (score: 0.09) 3 橡木 (score: 0.08) 4 项目 (score: 0.06) 5 接单 (score: 0.05)
这个是无监督聚类的结果,已经不错了。
由于某些原因,上传BD失败,因此就上传到天翼云,含代码和数据文件:https://cloud.189.cn/t/qiuQfu2yYfm2
PS:我想用监督学习的方式,手动打标签,然后训练模型,这样训练出来类别更加精准,问题是每个群标签可能不止一个,所以大家有什么好的方案呢?