对于thrift的几种server模型在不同场景下的性能表现做了一个压测,结果仅供参考。
(一)环境
服务端机器:
24核CPU,E5-2430,2.5GHz,96GB内存
客户端机器:
24核CPU,E5-2430,2.5GHz,64GB内存
网络环境:
千兆网
thrift版本:
0.9.1
语言:
C++
服务端处理:
sleep 0.5ms,打印一条日志
(二)不同server特点
- 多线程-threaded
每新到一个连接就新建一个线程处理,直到连接关闭线程销毁
线程数=当前连接数,线程数无限制
新建线程&销毁线程耗资源
- 线程池-threadpool
主线程将新连接放入任务队列,工作线程从任务队列区连接处理,直到连接关闭线程再从任务队列取连接
线程数=线程池size
如果线程池设置的不够,可能导致上游等待
- 非阻塞-nonblocking
使用libevent
(三)压测结果
对每种情况并发执行500000个请求
threadpool的size:2048
nonblocking中,work线程池size:256,IO线程个数:256
| qps | 线程池+长连接 | 线程池+短连接 | 多线程+长连接 | 多线程+短连接 | 非阻塞+长连接 | 非阻塞+短连接 |
| 4 | 5102 | 3571 | 5102 | 3521 | 5319 | 4032 |
| 8 | 10416 | 7352 | 10416 | 6944 | 10416 | 7352 |
| 16 | 20833 | 13157 | 20833 | 12500 | 19230 | 12500 |
| 32 | 35714 | 17857 | 35714 | 15625 | 31250 | 19230 |
| 64 | 35714 | 19230 | 35714 | 20833 | 35714 | 22727 |
| 128 | 33333 | 19230 | 35714 | 20833 | 35714 | 19230 |
| 256 | 27777 | 19230 | 35714 | 19230 | 41666 | 20833 |
| 512 | 27777 | 17857 | 27777 | 16129 | 41666 | 19230 |
| 1024 | 27777 | 17857 | 27777 | 16666 | 41666 | 19230 |
| 2048 | 27777 | 13888 | 27777 | 12820 | 50000 |
对比图如下所示:
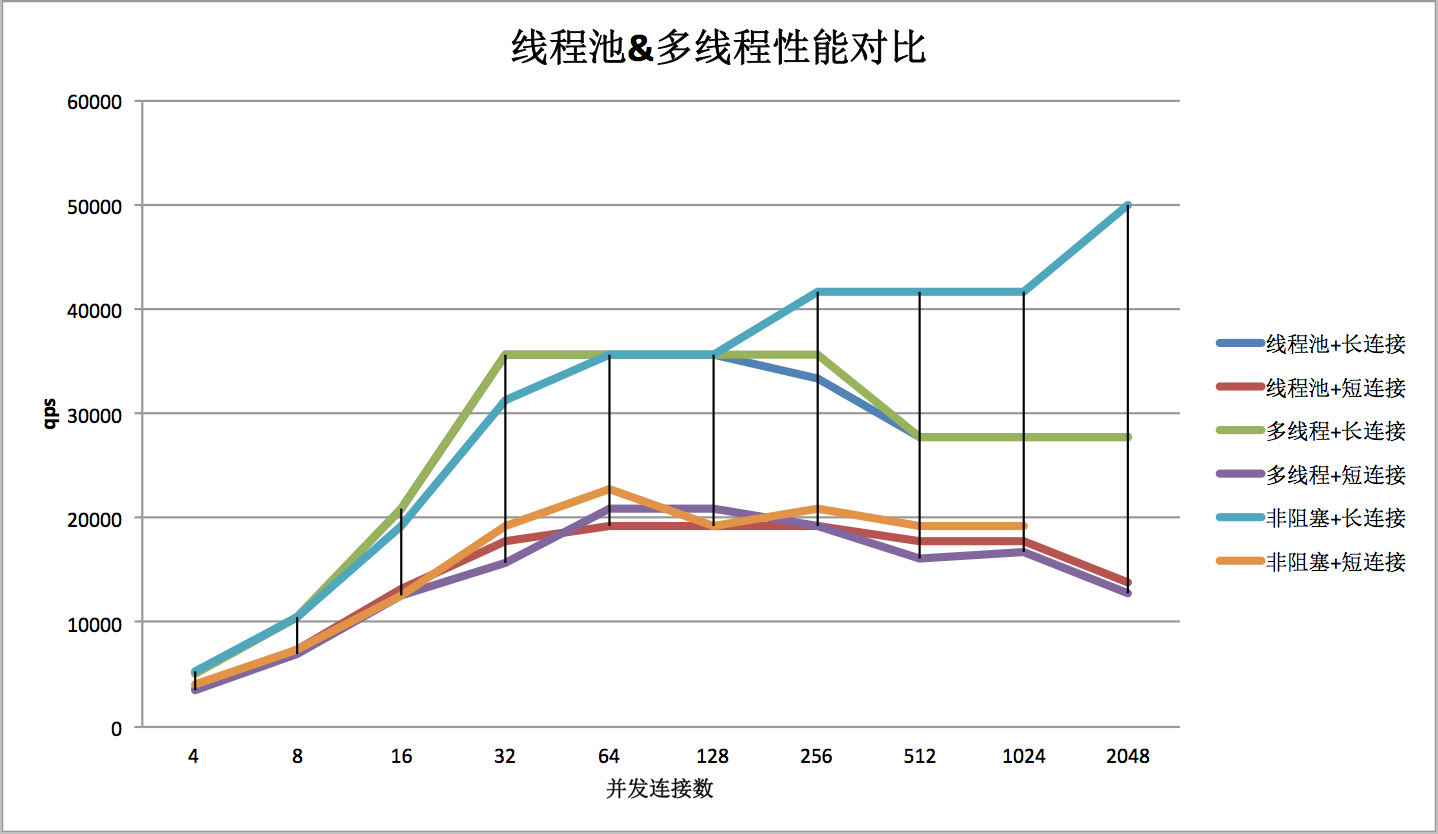
(四)结论
1)线程池threadpool和多线程threaded性能差别不大
2)在所有模型中,长连接比短连接性能高30%~50%,且性能最优时均在并发连接为32~256时
3)在并发达到512后,只用非阻塞+长连接的性能逐步提升,其他case的性能都会随着并发的增大而降低
综上,长连接时使用非阻塞方式性能最优;短连接时,各种模型差异不大。