学习过程知识粗略记录,用于个人理解和日后查看
包导入
import torch
from torch import nn
MSELoss-均方差损失
- 常用于回归问题中
- 对于每一个输入实例都只有一个输出值,把所有输入实例的预测值和真实值见的误差求平方,然后取平均
- 定义:
class torch.nn.MSELoss(size_average=True,reduce=True)
参数含义
size_average:默认为True,此时损失为每个minibatch的平均;False时,损失为每个minibatch的求和。这个属性只有在reduce设置为True时才生效reduce:默认为True,损失根据size_average的值计算;False时,忽略size_average值,返回每个元素的损失
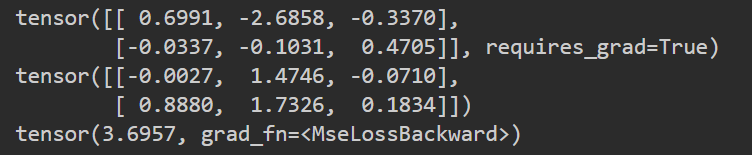
loss=nn.MSELoss()
input = torch.randn(2, 3, requires_grad=True)
target = torch.randn(2,3)
print(input)
print(target)
output = loss(input, target)
output.backward()
print(output)
L1Loss-MAE平均绝对误差
- 常用于回归问题中
- 返回数据集上所有误差绝对值的平均数
- 定义:
class torch.nn.L1Loss(size_average=True,reduce=True),参数与MSE相同
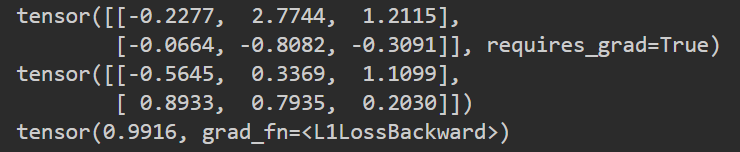
loss=nn.L1Loss()
input = torch.randn(2, 3, requires_grad=True)
target = torch.randn(2,3)
print(input)
print(target)
output = loss(input, target)
output.backward()
print(output)
BCELoss
- 常用于二分类问题中
- 定义:
class torch.nn.BCELoss(weight=None, size_average=True, reduce=True)
参数定义:
weight:指定batch中的每个元素的Loss权重,必须是一个长度和batch相等的Tensor
- 值得注意的是,每个目标值都要求在
(0,1)之间,可以在网络最后一层加一个Sigmoid解决这个问题
m = nn.Sigmoid()
loss = nn.BCELoss()
input = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)
print(input)
print(target)
output = loss(m(input), target)
output.backward()
print(output)

BCEWithLogitsLoss
- 同样用于二分类问题,他将
Sigmoid集合在了函数中,因而实际使用中会比BCELoss在数值上更加稳定 class torch.nn.BCEWithLogitsLoss(weight=None, size_average=True, reduce=True),参数同BCELoss一致
loss = nn.BCEWithLogitsLoss()
input = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)
print(input)
print(target)
output = loss(input, target)
output.backward()
print(output)

NLLLoss-负对数似然损失函数
- 应用于多分类任务中,用C表示多分类任务中的类别个数,
N表示minibatch,则NLLLoss的输入必须是(N,C)的二维Tensor,也就是每个实例对应的每个类别的对数概率,可以在网络的最后一层加LogSoftmax层来实现 - 定义:
class torch.nn.NLLLoss(weight=None, size_average=True, ignore_index=-100,reduce=True)
参数含义:
weight:指定一个一维的Tensor,用来设置每个类别的权重(非必须项)ignore_index:设置一个被忽略值,使这个值不会影响到输入的梯度计算,size_average为True时,loss的平均值也会忽略该值
- 值得注意的时,输入根据
reduce而定,True则输出一个标量,False则输出N
m = nn.LogSoftmax(dim=1)
loss = nn.NLLLoss()
# input is of size N x C = 3 x 5
input = torch.randn(3, 5, requires_grad=True)
# each element in target has to have 0 <= value < C
target = torch.tensor([1, 0, 4])
print(input)
print(target)
output = loss(m(input), target)
output.backward()
print(output)

CrossEntropyLoss-交叉熵损失
- 用于多分类问题,
LogSoftmax和NLLLoss的组合 - 定义:
class torch.nn.CrossEntropyLoss(weight=None, size_average=True, ignore_index=-100,reduce=True),参数含义与NLLLoss相同
loss = nn.CrossEntropyLoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
print(input)
print(target)
output = loss(input, target)
output.backward()
print(output)

如有错误,欢迎指正
同时发布在CSDN中:https://blog.csdn.net/tangkcc/article/details/119803598