本单元三次作业层层递进,每次增加一些需求。我在第一次作业的时候,就针对性地设计了完整的表达式树结构,使得后续扩展非常容易。
程序结构
一些概念
Token 输入字符串中可以被独立解析的最小单位,如运算符(加、减、乘、乘方),数,未知数等。
Expression 表达式中的元素,如 ConstantNumberExpression(表示常数)、SumExpression(表示若干个表达式相加构成的表达式)等各个类型。表达式元素互相嵌套,构成完整的表达式。表达式均为不可变对象,化简、求导操作都需要创建新的表达式对象。
程序运行流程
1. 从标准输入流读入字符串;
2. 对字符串进行词法分析,将字符串转换为一系列 Token;
3. 对 Token 流进行格式验证,确保不是 WRONG FORMAT;
4. 使用调车场(Shunting Yard)算法,将 Token 流转换为表达式树;
5. 对表达式树进行递归求导;
6. 对表达式树进行递归化简;
7. 将结果转换为字符串并输出。
关键的函数
1. Lexer.Tokenize 将输入转换为词对象(比如数字转换为 NumberToken 的实例、括号转换为 Parenthesis 类的实例等)。
2. Parser.Parse 解析表达式。
3. Operator.constructExpression 与 Function.constructExpression 使用 Token 构造 Expression 的方法。此时运算符 Token 对象作为一个工厂,根据参数传入的表达式,创建它所代表的表达式。例如,加法运算符 PlusMinusOperator 类根据传入的两个表达式,返回两个表达式的和或者差。
3. Expression.simplify 求出对表达式进行化简后的表达式。化简表达式采用递归的形式进行,一般的化简原则是首先化简子表达式,然后丢弃、合并其中的对象(如乘法合并所有常数因子、加法丢掉加零),最后返回新的表达式。新的表达式类型可能与原表达式类型不同,例如 1+1 (SumExpression)会被化简为 2(ConstantNumberExpression)。
4. Expression.derive 求出当前表达式对应的导函数。求导也采用递归的方式进行,例如加法表达式返回每一项加数求导结果之和;乘法表达式会根据链式求导法则进行处理。
5. Validator.validate 对表达式格式的验证方法。程序的结构决定它可以处理许多不符合格式的表达式,需要使用单独的代码验证。
迭代流程
第一次作业中,实现了基本的表达式(加、乘、乘方)和它们的求导。
第二次作业新增了三角函数(Cos、Sin),及 Validator。代码修改量为 13 files changed, 339 insertions(+), 57 deletions(-)
第三次作业新增了一些优化策略,以及根据作业要求改进了 Validator。代码修改量为 14 files changed, 286 insertions(+), 73 deletions(-)
可以看到,删除的代码都比较少,说明程序初期的结构是比较合理的。
第一次作业
第一次作业中,程序复杂度比较高的几个方法如下:
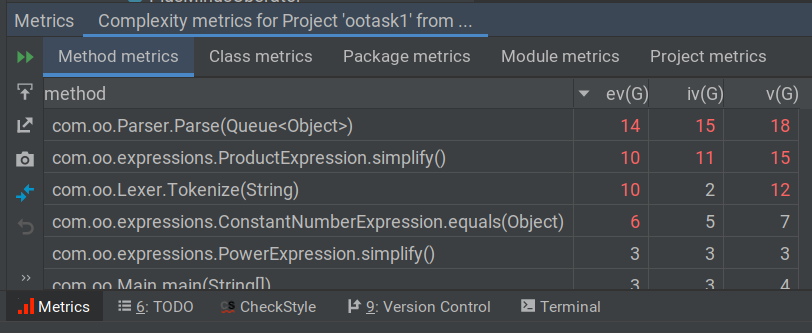
我个人认为这些方法的复杂度都是恰当的,是算法本身的需要,也不会造成对程序理解上的障碍。ProductExpression 表达式化简方法由于需要处理的情况较多,所以复杂度较高。
第二次作业
第二次作业中,程序复杂度比较高的几个方法如下:
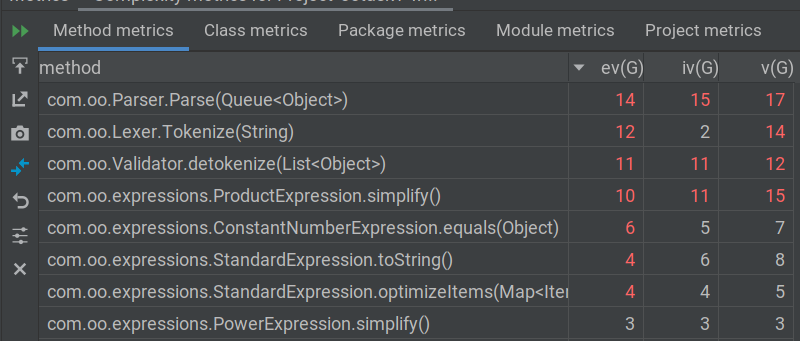
由于第一次作业框架设计比较全面,所以第二次作业的复杂程度并没有较多增加。
第三次作业

第三次作业增加了一些化简操作,所以复杂度有所上升。
bug 分析
本次作业总共出现了两个 bug,均与 WRONG FORMAT 有关。
第二次作业中,由于判断指数大小的代码有误(在 Expression 中判断了大小),导致当原表达式指数中出现 -10000 的时候,会出现误判。
第三次作业中,判断空格导致 WRONG FORMAT 的黑名单中漏掉 sin/cos(- n) 的情况。
第一个 bug 的出现与数据生成器的覆盖度不足有关。数据生成器只会生成四位数及以下的数据,导致没有测试到这种情况。第二个 bug 与考虑不周到、测试不完整有关。
自动测试脚本架构
本次作业没有出现除 WRONG FORMAT 之外的 bug,与自动测试脚本的高效程度有关。
本次自动测试脚本使用 Python 完成,生成数据的策略与多数同学采用的 xeger 不同,采用了严格模仿形式化表达的方式来进行。具体的方法是,为形式化表达中的每一行编写一个生成函数,递归调用这些函数。例如,提供了 generate_number / generate_factor / generate_power_expression / generate_triangular 等不同函数,并使用这些函数结果互相拼接。这样做的好处是,可以手动调整随机的概率(例如,0.4 的几率生成幂函数、0.4 的几率生成三角函数、0.2 的几率生成常数项),达到更好的测试覆盖。
同时,测试器在测试时需要将程序改为多组输入。Java VM 的启动是很慢的,将程序改为多组输入后,就不需要测试每组数据都启动一次 Java VM,可以极大地提高测试效率。
在第三次作业中,发现有的表达式求导结果即使正确,也可能因为浮点误差被 sympy 判为错误。这时候调用 Wolfram Mathematica 进行化简验证,如果化简结果为 0,就表示求导无误。
寻找他人 bug 的策略
使用自动测试脚本批量测试他人的代码。如果发现导致代码错误的数据,首先尝试简化随机生成的表达式,化简能到让代码出错的“最小表达式”,然后阅读程序源代码尝试理解思路。找到 bug 原因后,就提交 hack 数据。提交后,尝试修复错误,修复后继续测试。
应用对象创建模式来重构
在将 Token 转换为表达式树时,已经采取了一定的“工厂模式”思想,使用 Token 作为工厂来创建 Expression 对象。另外,可以考虑进一步在 Lexer 中使用 Factory 来创建 Token,但我认为就目前的需求来看这种做法的价值并不是特别大。
改进和优化
本次作业架构设计我认为没有重大缺陷,但是一些细节还有优化的空间。
首先是化简的方式还可以进一步优化。目前在第三次作业中并没有实现三角变换 / 因式分解等高级的化简策略,需要思考这些策略应该如何应用到代码当中,特别是应该学习一些同学已经实现的、结合时间限制进行递归化简的方式。
其次,判断 WRONG FORMAT 的部分,在涉及到空白造成的错误时,使用了“黑名单”的方式。这种方式是很容易出现错误的(事实证明第三次就出现了 bug),需要继续思考应该如何改进。