Region的拆分
随着大合并的增多,一个region越来越大,造成数据的存储不平衡,访问速度也会变慢。
- 所以,当region达到一定大小(默认10G),region会先下线,一分为二,分为两个region,R1,R2.
- Hmaster会将R2迁移到其他的regionserver中。底层的Hfile指向新的region2
- 更新元数据信息region1 region2到HBASE:meta表
Region的合并
- Region的合并不是为了性能, 而是出于维护的目的 .
- 比如删除了大量的数据 ,这个时候每个Region都变得很小 ,存储多个Region就浪费了 ,这个时候可以把Region合并起来,进而可以减少一些Region服务器节点
Region合并有两种方式
- 冷合并
- 热合并
Region冷合并
- 执行合并前,需要先关闭hbase集群
- 通过hbase +org.apache.hadoop.hbase.util.Merge类 + table name全名合并
- 不需要进入hbase shell,直接执行
hbase org.apache.hadoop.hbase.util.Merge person
person,,1593953711622.dcd1823dc1cc11ba251fe7e18e747a75.
person,1000,1593953711622.ca647144d51cd76f01909801d070bf6f.
- 1
- 2
- 3

合并前
合并后:
Region热合并
-
不需要关闭hbase集群,在线进行合并
-
与冷合并不同的是,online_merge的传参是Region的hash值,而Region的hash值就是Region名称的最后那段在两个.之间的字符串部分。
-
需求:需要把test表中的2个region数据进行合并:
student,1593954415190.098539361430261d4c02cf78c0134a04.
student,aa,1593954415190.f9650b81405e95bf1d32bdf5c137192a. -
需要进入hbase shell:
merge_region '098539361430261d4c02cf78c0134a04','f9650b81405e95bf1d32bdf5c137192a'
- 1
合并前:
合并后: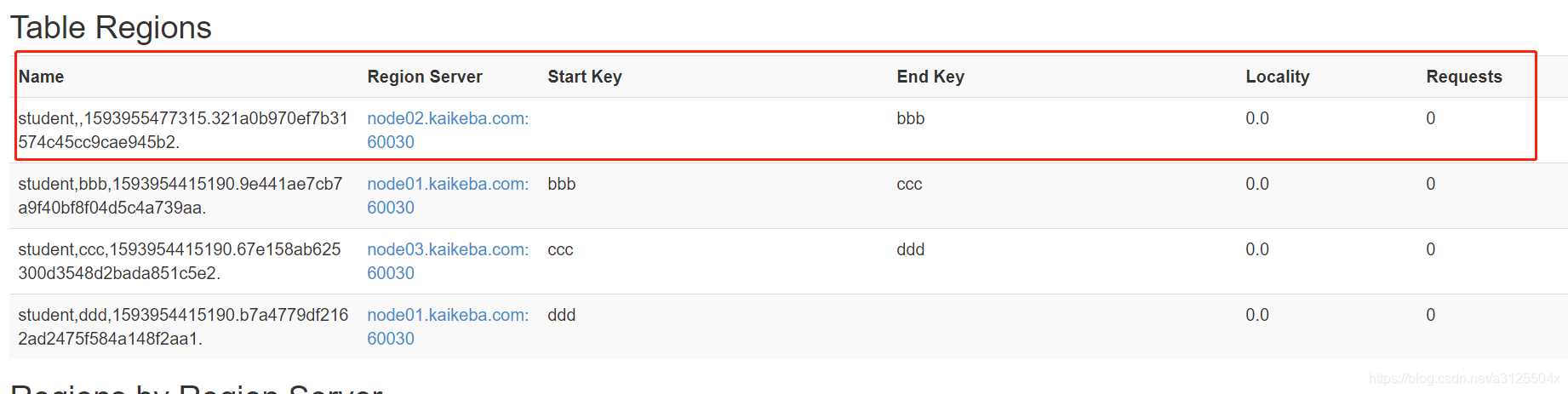
1 Region拆分
一个Region代表一个表的一段Rowkey的数据集合,当Region太大,Master会将其拆分。Region太大会导致读取效率太低,遍历时间太长,通过将大数据拆分到不同机器上,分别查询再聚合,Hbase也被人称为“一个会自动分片的数据库”。
Region可以手动和自动拆分。
1.1 Region自动拆分
1.1.1 ConstantSizeRegionSplitPolicy
固定大小拆分策略,0.94版本之前的唯一拆分方法,如果单个Region大小超过了阀值那么就拆分为两个Region,这种策略使得急群众的Region大小很平均。唯一的参数是(hbase-site.xml):
hbase.hregion.max.filesize:region最大大小,默认为10GB
<property>
<name>hbase.hregion.max.filesize</name>
<value>10 * 1024 * 1024 * 1024</value>
</property>
1.1.2 IncreasingToUpperBoundRegionSplitPolicy
动态限制拆分策略,是新版本的默认策略。有的数据库文件增长是翻倍的数据量,128M,256M,512M……,该策略与之类似,限制是动态的,计算公式为:
Math.min(tableRegionsCount^3 * initialSize,defaultRegionMaxFileSize)
- tableRegionCount:当前表在所有RegionServer上拥有的所有的Region数量的总和
- initialSize:如果定义了hbase.increasing.policy.initial.size,则使用该值,否则用memstore刷写值得2倍,即hbase.hregion.memstore.flush.size*2。
- deffaultRegionmaxFileSize:ConstantSizeRegionSplitPolicy所用到的配置项,也就是Region的最大大小
- Math.min:取这两个数值的最小值
当初始hbase.hregion.memstore.flush.size定义为128M,过程为:
- 刚开始只有一个Region,上限为1^31282=256M
- 当有2个Region,上限为2^31282=2048M
- 当有3个Region,上限为3^31282=6912M
- 以此类推当有4个Region时候,为16G,上限达到了10GB,最大值就保持在了10G,Region数量再增加也不会增加上限
涉及到的相关配置有(hbase-site.xml中配置):
#动态限制拆分策略的初始化大小
hbase.increasing.policy.initial.size
#memstore最大刷写值
hbase.hregion.memstore.flush.size
#固定大小拆分策略定义的最大Region大小
hbase.hregion.max.filesize
1.1.3 KeyPrefixRegionSplitPolicy
固定长度前缀拆分策略,是IncreasingToUpperBoundRegionSplitPolicy的子类,在其基础上增加了对拆分点(splitPoint,拆分点就是Region被拆分出的RwoKey)的定义,保证了有相同前缀的key不会被拆分到两个不同的Region中。该策略会根据KeyPrefixRegionSplitPolicy.prefix_lenth所定义的长度来截取rowkey作为分组的依据。
当所有数据只有一两个前缀那么keyPrefixRegionSplitPolicy就不太有效,采用默认比较好,但是前缀如果划分比较细,查询容易发生跨Region查询的情况,这时候就比较实用。所以适合实用的场景有:
- 数据有多种前缀
- 查询多是针对前缀,比较少跨越多个前缀来查询数据
涉及到的配置参数有:
KeyPrefixRegionSplitPolicy.prefix_length rowkey:前缀长度
1.1.4 DelimitedKeyPrefixRegionSplitPolicy
分隔符前缀拆分策略,也是IncreasingToUpperBoundRegionSplitPolicy的子类,按照分隔符来判断是否进行拆分,比如定义了前缀分隔符为_,那么rowkey为host1_aaaaabbbb,host2_sjfijts,这两个数据会被拆分到不同的Region中。涉及到的配置参数有:
DelimitedKeyPrefixRegionSplitPolicy.delimiter:前缀分隔符
1.1.5 BusyRegionSplitPolicy
热点拆分策略,这是唯一考虑到热点数据的拆分策略,如果数据库中的Region某些短时间内被访问很频繁,承载了很大压力,就是热点Region,涉及到的配置参数有:
hbase.busy.policy.blockedRequests:请求阻塞率,即请求被阻塞的严重程度,范围0.0-1.0,默认0.2,20%请求被阻塞
hbase.busy.policy.minAge:拆分最小年龄,当Region大于这个值才进行拆分,防止判断是否要拆分时候出现短时间的访问频率波分导致没必要拆分的region被拆分。而短时前的波峰可能会快就会恢复到正常水平,单位毫秒,默认值600000,10分钟。
hbase.busy.policy.aggWindow:计算是否繁忙的时间窗口,单位毫秒,默认值300000,5分钟,用以控制计算的评率
上诉三个配置项都是用于计算Region是否是热点Region的配置项,计算方法为:
- 当前时间 - 上次检测时间 >=hbase.busy.policy.aggWindow,则继续进行下一步计算
- 这段时间被阻塞的请求/这段时间的总请求=请求的被阻塞率(aggBlockedRate)
- 若aggBlockedRate > hbase.busy.policy.blockedRequests,那么该Region为繁忙
如果对性能要求比较高,该策略比较有效,但是因为Region拆分的不确定性,会带来很多不确定因素。
1.1.6 DisabledRegionSplitPolicy
手动拆分策略,其实就是上诉所有的策略都失效,不管如何判断,都会返回不拆分。
自动拆分策略都是数据最开始写入一个Region,之后可能会发生数据大量写入的同时还进行拆分,如果我们知道如果拆分Region,我们就可以提前定义拆分点,数据就会直接分配到各自所需的Region,手动拆分有如下良两种:
1.2 手动拆分
1.2.1 pre-splitting Region预拆分
就是在建表的时候就定义好拆分点的算法,使用org.apache.hadoop.hbase.util.RegionSplitter类来创建表,并传入拆分点算法,就可以在建表同事定义拆分点算法。比如;
hbase org.apache.hadoop.hbase.util.RegionSplitter table_name HexStringSplit -c 10 -f mycf
HexStringSplit:指定的拆分点算法
-c:要拆分的Region数量
-f:要建立的列族名称
#会建立10个固定的Region,使用如下语句查看创建的Region
scan 'hbase:meta',{STARTROW=>'table_name',LIMIT => 10}
具体的拆分点算法有:
1.2.1.1 HexStringSplit
ASCII码预拆分策略,只需要传入一个要拆分的Region的数量,HexStringSplit会将数据从“00000000”到“FFFFFFFF”之间的数据长度按照n等分之后算出每一段的其实rowkey和结束rowkey,以此作为拆分点。
1.2.1.2 UniformSplit
字节码预拆分策略,与ASCII码预拆分不同的是,起始结束不是Sting而是byte[]
- 起始rowkey是ArrayUtils.EMPTY_BYTE_ARRAY
- 结束rowkey是new byte[]{xFF,xFF,xFF,xFF,xFF,xFF,xFF,xFF}
最后调用Bytes.split方法把其实rowkey到结束rowkey之间的长度n等分,然后取每一段的起始和结束作为拆分点
默认预拆分算法只有这两个,我们也可以通过实现SplitAlgorithm接口实现自己的拆分算法,或者干脆手动定出拆分点。
1.2.2 手动制定拆分点(属于预拆分)
只需要在建表的时候跟上SPLITS参数:
create 'test_split2','mycf2','mysf2',SPLITS=>['AAA','BBB','CCC']
1.2.3 强制拆分
其实这个才是实际意义上的手动拆分,通过运行命令强制手动拆分(forced splits),调用hbase shell的split方法。
#将表table_name从1000出拆分为两个Region
split 'table_name,c,1476405886999.96dd83893d683','1000'
#其他调用方式有:
split 'tableName'
split 'namespace:tableName'
split 'regionName'#format:'tableName,startKey,id'
split 'tableName','splitKey'
split 'regionName','splitKey'
1.3 总结
建议开始的时候定义预拆分,导入初始数据,之后使用自动拆分来让HBase自动管理Region。不要关闭自动拆分。这样科比避免因为直接使用预拆分导致的热点Region问题。
尽量使用适合业务的拆分策略,比如不要在时间戳为rowley前缀的情况下还是iyongKeyPrefixRegionSplitPolicy来作为拆分策略,这会导致严重的热点问题。
2 Region合并(Merge)
首先,Region的合并(merge)并不是为了性能考虑而是处于维护的目的被创造出来的。比如删了大量的数据,导致每个Region都变小了,这个时候合并Region就比较合适了。
2.1 通过Merge类冷合并Region
通过org.apache.hadoop.hbase.util.Merge类来实现,不需要进入hbase shell,直接执行:
hbase org.apache.hadoop.hbase.util.Merge table_name
table_name,a,147608089478.39erijidsfd8s098fen32j3i8d9.
table_name,b,148893879502.48jfidnxoskd023843257822j3i.
就可以实现两个Region的合并,但是有一个前提,必须保证这两个Region已经下线,保证HMaster和所有的HRegionServer都停掉,否则会报错,但是这样太麻烦了,而且不适合生产使用。
2.2 通过online_merge热合并Region
与冷合并不同的是,online_merge的传参是Region的hash值,而Region的hash值就是Region名称的最后那段在两个.之间的字符串部分,需要进入hbase shell:
> merge_region '39erijidsfd8s098fen32j3i8d9','48jfidnxoskd023843257822j3i'
#通过hbase:meta查看Region合并后的信息
3 HFile合并(Compact)
MemStore每次刷写都会生成一个HFile,当HFile变多,回到值读取数据磁头寻址缓慢,因为HFile都分散在不同的位置,为了防止寻址动作过多,适当的减少碎片文件,就需要合并HFile。
3.1 HFile的合并策略
合并操作主要是在一个Store里边找到需要合并的HFile,然后把它们合并起来,合并在大体意义上有两大类Minor Compation和Major Compaction:
- Minor Compaction:将Store中多个HFile合并为一个HFile,这个过程中,达到TTL(记录保留时间)会被移除,但是有墓碑标记的记录不会被移除,因为墓碑标记可能存储在不同HFile中,合并可能会跨国部分墓碑标记。这种合并的触发频率很高
- Major Compaction:合并Store中所有的HFile为一个HFile(并不是把一个Region中的HFile合并为一个),这个过程有墓碑标记的几率会被真正移除,同时超过单元格maxVersion的版本记录也会被删除。合并频率比较低,默认7天执行一次,并且性能消耗非常大,最后手动控制进行合并,防止出现在业务高峰期。
需要注意的是,有资料说只有Major合并才会删数据,其实Major合并删除的是带墓碑标记的,而Minor合并直接就不读取TTL过期文件,所以也相当于删除了。
3.1.1 老版本的合并策略(0.96之前)RationBasedCompactionPolicy
基于固定因子的合并策略,从旧到新扫描HFile文件,当扫描到某个文件满足条件:
该文件大小 < 比它更新的所有文件大小综合 *hbase.store.compaction.ratio
就把该HFile和比它更新的所有HFile合并为一个HFile。
但是实际上,Memstore很多情况下会有不同的刷写情况,所以每次的HFile不一定一样大,比如最后一次导入数据需要关闭Region,强制刷写导致数据非常少。实际情况下RatioBasedCompactionPolicy算法效果很差,经常应发大面积合并,合并就不能写入数据,影响IO。
3.1.2 新版本合并策略 ExploringCompactionPolicy
是新版本的默认算法,不再是强顺序遍历,而是整体遍历一遍然后综合考虑,算法模型是:
该文件大小 < (所有文件大小综合 - 该文件大小) * 比例因子
如果HFile小于minCompactionSize,则不需要套用公式,直接进入待合并列表,如果没有配置该项,那么使用hbase.hregion.memstore.flush.size。
#合并因子
hbase.store.compaction.ratio
#合并策略执行最小的HFile数量
hbase.hstore.compaction.min.size
#合并策略执行最大的HFile数量
hbase.hstore.compaction.max.size
#memstore刷写值,
hbase.hregion.memstore.flush.size
#参与合并最小的HFile大小
minCompactionSize
所以一个HFile是否进行参与合并:
- 小于minCompactionSize,直接进入合并列表
- 大minCompactionSize,用公式决定是否参与合并
- 穷举出所有可执行合并列表,要求数量要>hbase.hstore.compaction.min.size,且<=hbase.hstore.compaction.max.size
- 比较所有组,选出其中数量最多
- 在数量最多且一样的组中,选择总大小最小的一组
3.1.3 FIFOCompactionPolicy
先进先出合并策略,最简单的合并算法,甚至可以说是一种删除策略。minor、major合并一定会发生但是频率不同,但是有时候没必要执行合并:
- TTL特别短,比如中间表,只是在计算中间暂存一些数据,很容易出现一整个HFile都过去
- BlockCache非常大,可以把整个RegionServer上的数据都放进去,就没必要合并了,因为所有数据都可以走缓存
因为合并会把TTL超时数据删掉,两个合并就回导致其实把HFile都删除了,而FIFO策略在合并时候就会跳过含有未过期数据的HFile,直接删除所有单元格都过期的块,所以结果就是过期的快上整个被删除,而没过期的完全没有操作。而过程对CPU、IO完全没有压力。但是这个策略不能用于:
- 表没有设置TTL,或者TTL=ForEver
- 表设置了Min_Versions,并且大于0
因为如果设置了min_versions,那么TTL就会失效,芮然达到了TTL时间,但是因为有最小版本数的限制,依旧不能删除。但是如果手动进行delete依旧可以删到小于最小版本数,min_versions只能约束TTL,所以FIFO不适用设置了min_versions的情况。
3.1.4 DateTieredCompactionPolicy
日期迭代合并删除策略,主要考虑了一个比较重要的点,最新的数据可能被读取的次数是最多的,比如电商中用户总是会查看最近的订单;随着时间的推移,用户会逐渐减缓对老数据的点击;非常古老的记录鲜有人问津。
电商订单这种数据作为历史记录一定没有TTL,那么FIFO合并策略不合适;单纯的看大小进行合并也不太有效,如果把新数据和老数据合并了,反而不好,所以Exploring也不友好。Ratio就更别考虑了,每次合并都卷入最新的HFile。
所以DateTieredCompactionPolicy的特点是:
- 为了新数据的读取性能,将新旧文件分开处理,新的和新的合并,旧的和旧的合并
- 不能只把数据分为新旧两种,因为读取频率是连续的,所以可以分为多个阶段,分的越细越好
- 太早的文件就不合并了,没什么人读取,合不合并没有太大差别,合并了还消耗性能
涉及到的配置项有有:
#初始化时间窗口时长,默认6小时,最新的数据只要在6小时内都会在初始化时间窗口内
hbase.hstore.compaction.date.tiered.base.window.millis
# 层次增长倍数,用于分层。越老的时间窗口越长,如果增长倍数是2,那么时间窗口为6、12、24小时,以此类推。如果时间窗口内的HFile数量达到了最小合并数量(hbase.hstore.compaction.min)就执行合并,并不是简单合并成一个,默认是使用ExploringCompactionPolicy(策略套策略),使用hbase.hstore.compaction.date.tiered.window.policy.class所定义
hbase.hstore.compaction.date.tiered.windows.per.tier
#最老的层次时间,如果文件太老超过了该时间定义的范围(默认天为单位)就直接不合并了。
hbase.hstore.compaction.date.tiered.max.tier.age.millis
#最小合并数量
hbase.hstore.compaction.min
有一个确定就是,如果Store中的某个HFile太老了,但是有没有超过TTL,且大于了最老层次时间,那么这个HFile在超时被删除之前都不会被删除,不会发生Major合并,用户手动删除数据也不会真正被删除,而是一直占用着空间。
其实归根到底,合并的最终策略是每个时间涌口中的HFile数量达到了最小合并数量,那么就回进行合并。另外,当一个HFile跨了时间线的时候,将其定义为下一个时间窗口(更老的更长的)。
适用场景:
- 适用于经常读写最近数据的系统,专注于新数据
- 因为哪个缺点的原因可能引发不了Major合并,没法删除手动删除的信息,更适合基本不删数据的系统
- 根据时间排序的存储也适合
- 如果数据修改频率较低,只修改最近的数据,也推荐使用
- 如果数据改动平凡,老数据也修改,经常边读边写数据,那么就不太适合了。
3.1.5 StripeCompactionPolicy
简单来说就是将一个Store里边的数据分为多层,数据从Memstore刷写到HFile先落到level 0,当level 0大小超过一定的阀值时候会引发一次合并,会将level 0读取出来插入到level 1的HFile中去,而level 1的块是根据建委范围划分的,最早是分为多层的,后来感觉太复杂,将level 0改名为L0,而level 1-N合并成一个层叫做strips层。依旧是按照键位来划分块。
这种策略的好处是:
- 通过增加L0层,给合并操作增加了一层缓冲,让合并操作更加缓和;
- 严格按照键位来划分Strips,碎玉读取虽然不能提高太多速度,但是可以提高查询速度的稳定性,执行scan时候,跨越的HFile数量保持在了一个比较稳定的数值
- Major合并本来是牵涉到一个store中的所有HFile,现在可以按照子Strip执行了,因为Major合并一直都会存在因为牵涉HFile太多导致的IO不稳定,而该策略一次只是牵涉到一个Strip中的文件,所以克服了IO不稳定的缺点
Stripe合并策略对于读取的优化要好于写的优化,所以很难说会提高多少IO性能,最大的好处就是稳定。那么什么场景适合StripeCompactionPolicy呢?
- Region要足够大,如果Region小于2GB那么就不适合该策略,因为小Region用strips会细分为多个stripe,反而增加IO负担
- RowKey要具有统一的格式,能够均匀分布,如果使用timestamp来做rowkey,那么数据就没法均匀分布了,而用26个首字母就比较合适
3.2 HFile合并的吞吐量限制参数
在使用过程中,如果突然发生IO降低,十有八九是发生compaction了,但是compaction又是不可获取的,所以就可以通过限制compaction的吞吐量来限制其占用的性能。
由于HBase是分布式系统,吞吐量的概念是磁盘IO+网络IO的笼统概念,因为没办法具体判断哪一个的IO的限制更大,HBase的吞吐量是通过要合并的HFile的文件大小/处理时间得出的。未发生合并之前就没法测了,只能通过上一次的合并信息进行简单预测。具体的设置参数有;
#要限制的类型对象的类名,有两种
控制合并相关指标:PressureAwareCompactionThroughputController
控制刷写相关指标:PressureAwareFlushThroughputContoller
hbase.regionserver.throughput.controller
#当StoreFile数量达到该值,阻塞刷写动作,默认是7
hbase.hstore.blockingStoreFile
#合并张勇吞吐量下限
hbase.hstore.compaction.throughput.lower.bound
#合并占用吞吐量上限
hbase.hstore.compaction.throughput.higher.bound
hbase.hstore.blockingStoreFile的设置比较讲究,如果设置不合理,当HFile数量达到该值之后,会导致Memstore占用的内存急剧上升,很快就达到了Memstore写入上限,导致memstore阻塞,一点都写不进去。所以Memstore达到阻塞值的时候,先不要急着调大Memstore的阻塞阀值,要综合考虑HFile的合并阻塞值,可以适当调大,20、30、50都不算多,HFile多,只是读取性能下降而已,但是达到阻塞值不只是慢的问题了,是直接写不进去了。
3.2.1 合并/刷写吞吐量限制机制
HBase会将合并和刷写总的吞吐量做计算,如果总吞吐量太大,那么进行适当休眠,因为这两个参数会限制合并时候占用的吞吐量,也会限制刷写时候占用的吞吐量。保证业务的响应流畅、保障系统的稳定性。限制会区分高峰时段和非高峰时段,通过如下两个参数:
#每天非高峰的起始时间,取值为0-23的整数
hbase.offpeak.start.hour
#每天非高峰的结束时间,取值为0-23的整数
hbase.offpeak.end.hour
通过设置非高峰,其他时段就是高峰时段了。在非高峰期是不会进行限速,只有在高峰期占用了太大的吞吐量才会休眠,主要看一个阀值:
lowerBound+(upperBound-lowerBound)*pressureRatio
#合并占用吞吐量的下限,取值是10MB/sec
lowerBound:hbase.hstore.compaction.throughput.lower.bound
#合并占用吞吐量的上限,取值是20MB/sec
upperBound:hbase.hstore.compaction.throughput.higher.bound
#压力比,限制合并时候,该参数就是合并压力(compactionpressure),限制刷写时候,该参数刷写压力(flushPressure),为0-1.0
pressureRatio
3.2.2 压力比
压力比(pressureRatio)越大,代表HFile堆积的越多,或者即将产生越多的HFile,一旦达到HFile的阻塞阀值,那么久无法写入数据了,所以合并压力比越大,合并的需求变得迫在眉睫。压力比越大,吞吐量的阀值越高,意味着合并线程可以占用更多的吞吐量来进行合并。
压力比有两种:
合并压力(compactionPressure):
(storefileCount-minFilesToCompact) / (blockingFileCount-minFilesToCompact)
storefileCount:当前StoreFile数量
minFilesToCompact:单词合并文件的数量下限,即hbase.hstore.compaction.min
blockingFileCount:就是hbase.hstore.blockingStoreFiles
当前的StoreFile越大,或者阻塞上限越小,合并压力越大,更可能发生阻塞
刷写压力(flusthPressure):
globalMemstoreSize / memstoreLowerLimitSize
globalMemstore :当前Msmstore大小
memstoreLowerLimitSize:Memstore刷写的下限,当全局memstore达到这个内存占用数量的时候就会开始刷写
如果当前的Memstore占用内存越大,或者触发条件越小,越有可能引发刷写,刷写后HFile增多,就有可能发生HFile过多阻塞。
3.3合并的具体过程
具体步骤为:
- 获取需要合并的HFile列表
- 由列表创建出StoreFileScanner
- 把数据从这些HFile中读出,并放到tmp目录(临时文件夹)
- 用合并后的新HFile来替换合并前的那些HFile
3.2.1 minor Compaction
第一步:获取需要合并的HFile列表
获取列表的时候需要排除掉带锁的HFile,分为写锁(write lock)和读锁(read lock),当HFile正在进行如下操作时候会进行上锁:
- 用户正在进行scan查询->上Region读锁(region read lock)
- Region正在切分(split):此时Region会先关闭,然后上Region写锁(region write lock)
- Region关闭->上region写锁(region write lock)
- Region批量导入->Region写锁(region write lock)
第二步:由列表创建出StoreFileScanner
HRegion会创建出一个Scanner,用Scanner读取所有需要合并的HFile上的数据
第三步:把数据从这些HFile中读出,并放到tmp(临时目录)
HBase会在临时目录中创建新的HFile,并把Scanner读取到的数据放入新的HFile,数据过期(达到了TTL时间)不会被读出:
第四步:用合并后的HFile来替换合并前的那些HFile
最后用哪个临时文件夹合并后的新HFile来替换掉之前那些HFile文件,过期的数据由于没有被读取出来,所以就永远消失了。
3.2.2 Major Compaction
HBase中并没有一种合并策略叫做Major Compaction,Major Compaction目的是增加读性能,在Minor Compaction的基础上可以实现删除掉带墓碑标记的数据。因为有时候,用户删除的数据,墓碑标记和原始数据这两个KeyValue在不同的HFile上。在Scanner阶段,会将所有HFile数据查看一遍,如果数据有墓碑标记,那么就直接不Scan这条数据。
所以之前介绍的每一种合并策略,都有可能升级变为majorCompaction,如果本次Minor Compaction包含了当前Store所有的HFile,并且达到了足够的时间间隔,则会被升级为Major Compaction。这两个阀值的配置项为:
- hbase.hregion.majorcompaction:Major Compaction发生的周期,单位毫秒,默认7天
- hbase.hregion.majorcompaction.jitter:Major Compaction周期抖动参数,0-1.0,让MajorCompaction发生时间更加灵活,默认0.5
建议关闭自动Major Compaction,将base.hregion.majorcompaction设置为0.但也不要完全不进行Major Compaction,可以定义一些定时任务在非业务高峰期进行手动调用M按金融Compaction。
3.4 总结
详细查看各种策略的合适场景,根据场景做策略选择
- 如果数据有固定TTL,并且新数据容易被督导,那么选择DataTieredCompaction
- 如果没有TTL或者TTL较大,选择StripeCompaction
- FIFOCompaction一般不会被用到,在一些极端情况,比如生存时间特别短的数据。如果想用FIFO,可以先测试一下DataTieredCompaction的性能。