MapReduce的流程
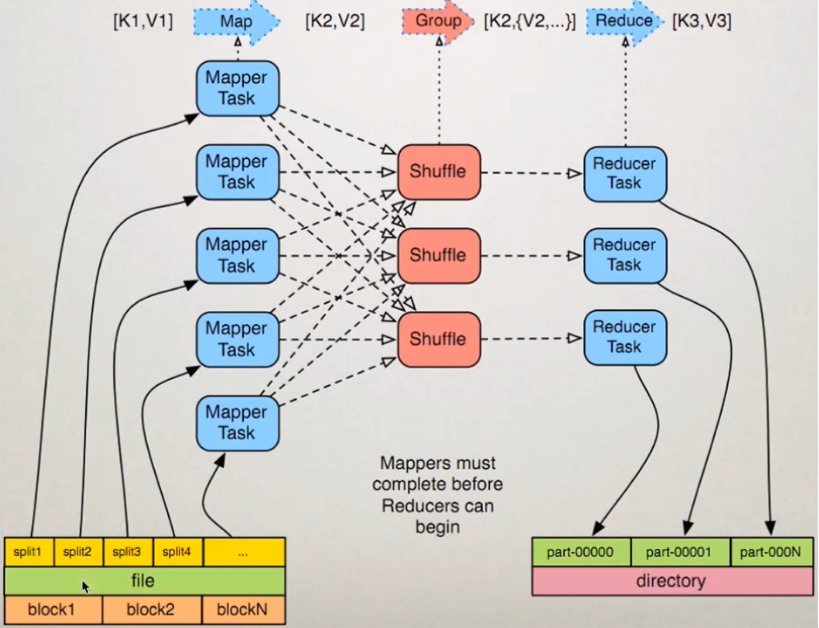
以统计一段文本的词频为例,介绍MapReduce的过程:
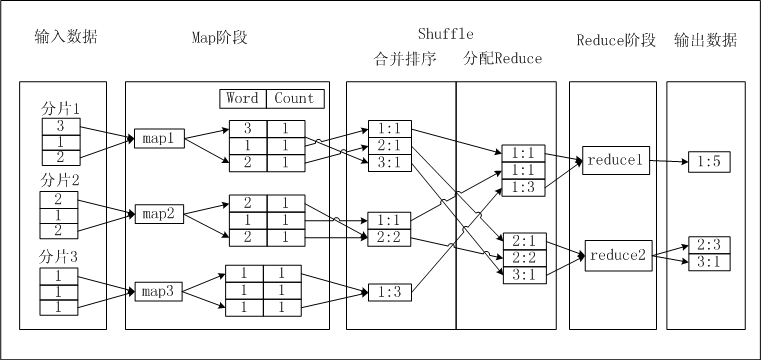
- 输入数据:对输入的文本数据split(分片,数据分片默认splitSize等于64M),每片内的数据作为单个
Map Worker的输入,于是多个Map Worker便可以同时工作 - Map:
Map Worker处理接收到的数据,Map Worker输出的每一条数据都会有一个指定的key,具有相同key值的数据会被发送到同一个Reduce Work - Shuffle:在进入 Reduce 阶段之前,MapReduce 框架会对数据按照 Key 值排序,使得具有相同 Key 的数据彼此相邻,这会有助于降低从Mapper到 Reducer数据传输量
- Reduce:相同Key的数据会传送至同一个Reduce Worker,每个Reduce Worker会对Key相同的多个数据进行Reduce操作
参考: