HashMap源码分析优秀解读
-
HashMap(1.7,超详细的解读):https://blog.csdn.net/carson_ho/article/details/79373026
-
HashMap(1.8,超详细的解读,包含各个函数的执行流程以及和1.7的区别):https://blog.csdn.net/carson_ho/article/details/79373134
-
HashMap(1.8):https://segmentfault.com/a/1190000012926722
HashMap 1.7
为了便于理解,以下源码分析以 JDK 1.7 为主。转载自https://github.com/CyC2018/CS-Notes/blob/master/notes/Java
1. 存储结构
内部包含了一个 Entry 类型的数组 table。Entry 存储着键值对。它包含了四个字段,从 next 字段我们可以看出 Entry 是一个链表。即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值和散列桶取模运算结果相同的 Entry。

transient Entry[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
}
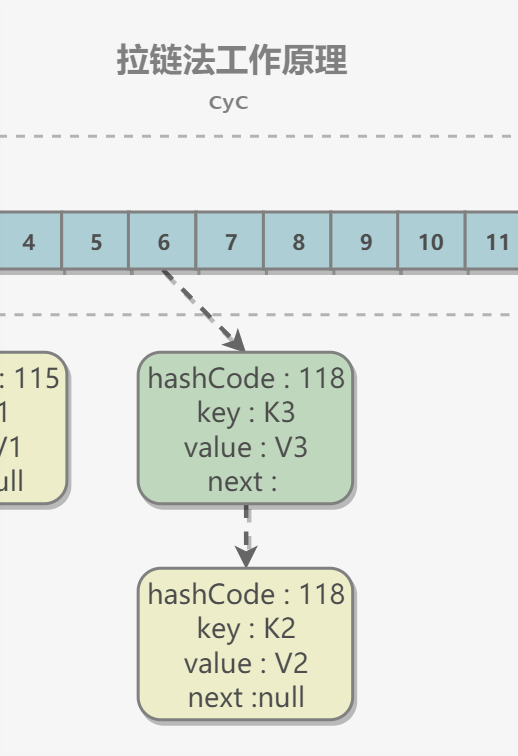
2.拉链法的工作原理
HashMap<String, String> map = new HashMap<>();
map.put("K1", "V1");
map.put("K2", "V2");
map.put("K3", "V3");
新建一个 HashMap,默认大小为 16;
插入 <K1,V1> 键值对,先计算 K1 的 hashCode 为 115,使用除留余数法得到所在的桶下标 115%16=3。
插入 <K2,V2> 键值对,先计算 K2 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6。
插入 <K3,V3> 键值对,先计算 K3 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6,插在 <K2,V2> 前面。
应该注意到链表的插入是以头插法方式进行的,例如上面的 <K3,V3> 不是插在 <K2,V2> 后面,而是插入在链表头部。
查找需要分成两步进行:
- 计算键值对所在的桶;
- 在链表上顺序查找,时间复杂度显然和链表的长度成正比。(所以要使用0.75为加载因子,这样的话链表的长度不会太长)
3. put 操作
HashMap 允许插入键为 null 的键值对。但是因为无法调用 null 的 hashCode() 方法,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对。
4. 扩容-基本原理
设 HashMap 的 table 长度为 M,需要存储的键值对数量为 N,如果哈希函数满足均匀性的要求,那么每条链表的长度大约为 N/M,因此查找的复杂度为 O(N/M)。
为了让查找的成本降低,应该使 N/M 尽可能小,因此需要保证 M 尽可能大,也就是说 table 要尽可能大。HashMap 采用动态扩容来根据当前的 N 值来调整 M 值,使得空间效率和时间效率都能得到保证。
和扩容相关的参数主要有:capacity、size、threshold 和 load_factor。

当需要扩容时,令 capacity 为原来的两倍。
扩容使用 resize() 实现,需要注意的是,扩容操作同样需要把 oldTable 的所有键值对重新插入 newTable 中,因此这一步是很费时的。
5.扩容-重新计算桶下标
在进行扩容时,需要把键值对重新计算桶下标,从而放到对应的桶上。在前面提到,HashMap 使用 hash%capacity 来确定桶下标。HashMap capacity 为 2 的 n 次方这一特点能够极大降低重新计算桶下标操作的复杂度。
假设原数组长度 capacity 为 16,扩容之后 new capacity 为 32
6.链表转红黑树
从 JDK 1.8 开始,一个桶存储的链表长度大于等于 8 时会将链表转换为红黑树。
为什么用红黑树
在jdk1.7中,HashMap处理“碰撞”的时候,都是采用链表来存储的,当碰撞的结点很多的时候(也就是hash值相同、key不同的元素很多时),查询时间是O(n)(最坏的情况)。查询时间从O(1)到O(n)。
而在jdk1.8中,HashMap处理“碰撞”增加了红黑树这种数据结构,当碰撞结点少时,采用链表存储,当较大的时候(>8),采用红黑树存储,查询时间是O(log n)。
7.与 Hashtable 的比较
- Hashtable 使用 synchronized 来进行同步。
- HashMap 可以插入键为 null 的 Entry。
- HashMap 的迭代器是 fail-fast 迭代器。
- HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。