第1章 迭代器
1.1 什么是迭代?
#1 什么是迭代:指的是一个重复的过程,每一次重复称为一次迭代,并且每一次重复的结果是下一次重复的初始值


# while True: # print('=====>') #只是单纯地重复,因而不是迭代 # l=['a','b','c'] # count=0 # while count < len(l): #迭代 # print(l[count]) # count+=1
1.2 为何要有迭代器?什么是可迭代的对象?什么是迭代器对象?
1.2.1 为什么要有迭代器?
#2 为什么要有迭代器?
#对于序列类型:str,list,tuple,可以依赖索引来迭代取值,
# 但是对于dict,set,文件,python必须为我们提供一种不依赖于索引的迭代取值的方式-》迭代器
对于序列类型:字符串、列表、元组,我们可以使用索引的方式迭代取出其包含的元素。但对于字典、集合、文件等类型是没有索引的,若还想取出其内部包含的元素,则必须找出一种不依赖于索引的迭代方式,这就是迭代器。
1.2.2 可迭代的对象
#3 可迭代的对象(下列都是):obj.__iter__
可迭代对象指的是内置有__iter__方法的对象,即obj.__iter__,如下
# name='egon' # l=[1,2,3] # t=(1,2,3) # d={'name':'egon','age':18,'sex':'male'} # s={'a','b','c'} # f=open('a.txt','w',encoding='utf-8') # # name.__iter__ # l.__iter__ # t.__iter__ # d.__iter__ # s.__iter__ # f.__iter__
1.2.3 迭代器对象
#4 迭代器对象(文件是):obj.__iter__,obj.__next__
# f.__iter__
# f.__next__
可迭代的对象执行obj.__iter__()得到的结果就是迭代器对象
而迭代器对象指的是即内置有__iter__又内置有__next__方法的对象
文件类型是迭代器对象
open('a.txt').__iter__()
open('a.txt').__next__()
1.2.4 总结
#1 可迭代对象不一定是迭代器对象
#2 迭代器对象一定是可迭代的对象
#3 调用obj.__iter__()方法,得到的是迭代器对象(对于迭代器对象,执行__iter__得到的仍然是它本身)。
1.3 迭代器对象的使用
# d={'name':'egon','age':18,'sex':'male'} # d_iter=d.__iter__() # f=open('a.txt','w',encoding='utf-8') # f_iter=f.__iter__().__iter__().__iter__().__iter__() # # print(f_iter is f) # d={'name':'egon','age':18,'sex':'male'} # d_iter=d.__iter__() # # print(d_iter.__next__()) # print(d_iter.__next__()) # print(d_iter.__next__()) # print(d_iter.__next__()) #迭代器d_iter没有值了,就会抛出异常StopIteration # f=open('a.txt','r',encoding='utf-8') # print(f.__next__()) # print(f.__next__()) # print(f.__next__()) # print(f.__next__()) # f.close() # l=['a','b','c'] # l_iter=l.__iter__() # # print(l_iter.__next__()) # print(l_iter.__next__()) # print(l_iter.__next__()) # print(l_iter.__next__()) # d={'name':'egon','age':18,'sex':'male'} # d_iter=iter(d) #d_iter=d.__iter__() # # #len(obj) 等同于obj.__len__() # # while True: # try: # print(next(d_iter)) #print(d_iter.__next__()) # except StopIteration: # break # # print('=>>>') # print('=>>>') # print('=>>>') # print('=>>>')
dic={'a':1,'b':2,'c':3}
iter_dic=dic.__iter__() #得到迭代器对象,迭代器对象即有__iter__又有__next__,但是:迭代器.__iter__()得到的仍然是迭代器本身
iter_dic.__iter__() is iter_dic #True
print(iter_dic.__next__()) #等同于next(iter_dic)
print(iter_dic.__next__()) #等同于next(iter_dic)
print(iter_dic.__next__()) #等同于next(iter_dic)
# print(iter_dic.__next__()) #抛出异常StopIteration,或者说结束标志
#有了迭代器,我们就可以不依赖索引迭代取值了
iter_dic=dic.__iter__()
while 1:
try:
k=next(iter_dic)
print(dic[k])
except StopIteration:
break
#这么写太丑陋了,需要我们自己捕捉异常,控制next,python这么牛逼,能不能帮我解决呢?能,请看for循环
1.4 for循环
#for循环详解: #1、调用in后的obj_iter=obj.__iter__() #2、k=obj_iter.__next__() #3、捕捉StopIteration异常,结束迭代 # d={'name':'egon','age':18,'sex':'male'} # for k in d: # print(k) #基于for循环,我们可以完全不再依赖索引去取值了 dic={'a':1,'b':2,'c':3} for k in dic: print(dic[k]) #for循环的工作原理 #1:执行in后对象的dic.__iter__()方法,得到一个迭代器对象iter_dic #2: 执行next(iter_dic),将得到的值赋值给k,然后执行循环体代码 #3: 重复过程2,直到捕捉到异常StopIteration,结束循环
1.5 迭代器的优缺点
#总结迭代器的优缺点: #优点: #1、提供一种统一的、不依赖于索引的取值方式,为for循环的实现提供了依据 #2、迭代器同一时间在内存中只有一个值——》更节省内存, #缺点: #1、只能往后取,并且是一次性的 #2、不能统计值的个数,即长度 # l=[1,2,3,4,5,6] # l[0] # l[1] # l[2] # l[0] # l_iter=l.__iter__() # # print(l_iter) # print(next(l_iter)) # print(next(l_iter)) # print(next(l_iter)) # print(next(l_iter)) # print(next(l_iter)) # print(next(l_iter)) # print(next(l_iter)) # # l_iter=l.__iter__() # print(next(l_iter)) # print(next(l_iter)) # print(next(l_iter)) # print(len(l_iter))
第2章 生成器
2.1 什么是生成器?
#1 什么是生成器:只要在函数体内出现yield关键字,那么再执行函数就不会执行函数代码,会得到一个结果,该结果就是生成器
def func(): print('=====>1') yield 1 print('=====>2') yield 2 print('=====>3') yield 3 g=func() print(g) #<generator object func at 0x0000000002184360>
2.2 生成器就是迭代器
g.__iter__ g.__next__ #2、所以生成器就是迭代器,因此可以这么取值 res=next(g) print(res) #生成器就是迭代器 # g=func() # # res1=next(g) # print(res1) # # # res2=next(g) # print(res2) # # # res3=next(g) # print(res3) #yield的功能: #1、yield为我们提供了一种自定义迭代器对象的方法 #2、yield与return的区别1:yield可以返回多次值 #2:函数暂停与再继续的状态是由yield帮我们保存的 # obj=range(1,1000000000000000000000000000000000000000000000000000000000000000,2) # obj_iter=obj.__iter__() # print(next(obj_iter)) # print(next(obj_iter)) # print(next(obj_iter)) # print(next(obj_iter)) # print(next(obj_iter)) # def my_range(start,stop,step=1): # while start < stop: # yield start #start=1 # start+=step #start=3 # # # g=my_range(1,5,2) # print(g) # print(next(g)) # print(next(g)) # print(next(g)) # print(next(g)) # print(next(g)) # print(next(g)) # print(next(g)) # for i in my_range(1,5,2): # print(i)
2.3 练习
1、自定义函数模拟range(1,7,2) 2、模拟管道,实现功能:tail -f access.log | grep '404' #题目一: def my_range(start,stop,step=1): while start < stop: yield start start+=step #执行函数得到生成器,本质就是迭代器 obj=my_range(1,7,2) #1 3 5 print(next(obj)) print(next(obj)) print(next(obj)) print(next(obj)) #StopIteration #应用于for循环 for i in my_range(1,7,2): print(i) #题目二 import time def tail(filepath): with open(filepath,'rb') as f: f.seek(0,2) while True: line=f.readline() if line: yield line else: time.sleep(0.2) def grep(pattern,lines): for line in lines: line=line.decode('utf-8') if pattern in line: yield line for line in grep('404',tail('access.log')): print(line,end='') #测试 with open('access.log','a',encoding='utf-8') as f: f.write('出错啦404 ')
#小练习::tail -f access.log | grep '404' # import time # def tail(filepath): # with open(filepath,'rb') as f: # f.seek(0,2) # while True: # line=f.readline() # if line: # yield line # else: # time.sleep(0.05) # # def grep(lines,pattern): # for line in lines: # line=line.decode('utf-8') # if pattern in line: # yield line # # # lines=grep(tail('access.log'),'404') # # for line in lines: # print(line)
2.4 协程函数(了解)
#yield关键字的另外一种使用形式:表达式形式的yield def eater(name): print('%s 准备开始吃饭啦' %name) food_list=[] while True: food=yield food_list print('%s 吃了 %s' % (name,food)) food_list.append(food) g=eater('egon') g.send(None) #对于表达式形式的yield,在使用时,第一次必须传None,g.send(None)等同于next(g) g.send('蒸羊羔') g.send('蒸鹿茸') g.send('蒸熊掌') g.send('烧素鸭') g.close() g.send('烧素鹅') g.send('烧鹿尾')
#了解知识点:yield表达式形式的用法 def eater(name): print('%s ready to eat' %name) food_list=[] while True: food=yield food_list#food=yield='一盆骨头' food_list.append(food) print('%s start to eat %s' %(name,food)) e=eater('alex') #首先初始化: print(e.send(None)) # next(e) #然后e.send:1 从暂停的位置将值传给yield 2、与next一样 print(e.send('一桶泔水')) print(e.send('一盆骨头'))
2.5 练习
1、编写装饰器,实现初始化协程函数的功能 2、实现功能:grep -rl 'python' /etc #题目一: def init(func): def wrapper(*args,**kwargs): g=func(*args,**kwargs) next(g) return g return wrapper @init def eater(name): print('%s 准备开始吃饭啦' %name) food_list=[] while True: food=yield food_list print('%s 吃了 %s' % (name,food)) food_list.append(food) g=eater('egon') g.send('蒸羊羔') #题目二: #注意:target.send(...)在拿到target的返回值后才算执行结束 import os def init(func): def wrapper(*args,**kwargs): g=func(*args,**kwargs) next(g) return g return wrapper @init def search(target): while True: filepath=yield g=os.walk(filepath) for dirname,_,files in g: for file in files: abs_path=r'%s\%s' %(dirname,file) target.send(abs_path) @init def opener(target): while True: abs_path=yield with open(abs_path,'rb') as f: target.send((f,abs_path)) @init def cat(target): while True: f,abs_path=yield for line in f: res=target.send((line,abs_path)) if res: break @init def grep(pattern,target): tag=False while True: line,abs_path=yield tag tag=False if pattern.encode('utf-8') in line: target.send(abs_path) tag=True @init def printer(): while True: abs_path=yield print(abs_path) g=search(opener(cat(grep('你好',printer())))) # g.send(r'E:CMSaaadb') g=search(opener(cat(grep('python',printer())))) g.send(r'E:CMSaaadb')
2.6 yield总结
#1、把函数做成迭代器
#2、对比return,可以返回多次值,可以挂起/保存函数的运行状态
2.7 面向过程编程
2.7.1 定义
#1、首先强调:面向过程编程绝对不是用函数编程这么简单,面向过程是一种编程思路、思想,而编程思路是不依赖于具体的语言或语法的。言外之意是即使我们不依赖于函数,也可以基于面向过程的思想编写程序 #2、定义 面向过程的核心是过程二字,过程指的是解决问题的步骤,即先干什么再干什么 基于面向过程设计程序就好比在设计一条流水线,是一种机械式的思维方式 #3、优点:复杂的问题流程化,进而简单化 #4、缺点:可扩展性差,修改流水线的任意一个阶段,都会牵一发而动全身 #5、应用:扩展性要求不高的场景,典型案例如linux内核,git,httpd #6、举例 流水线1: 用户输入用户名、密码--->用户验证--->欢迎界面 流水线2: 用户输入sql--->sql解析--->执行功能
2.7.2 举例
#grep -rl 'python' /etc #补充:os.walk # import os # g=os.walk(r'D:videopython20期day4a') # # print(next(g)) # # print(next(g)) # # print(next(g)) # # print(next(g)) # for pardir,_,files in g: # for file in files: # abs_path=r'%s\%s' %(pardir,file) # print(abs_path) #分析一: # #第一步:拿到一个文件夹下所有的文件的绝对路径 # import os # # def search(target): #r'D:videopython20期day4a' # while True: # filepath=yield #fllepath=yield=r'D:videopython20期day4a' # g=os.walk(filepath) # for pardir, _, files in g: # for file in files: # abs_path = r'%s\%s' % (pardir, file) # # print(abs_path) # target.send(abs_path) # # # search(r'D:videopython20期day4a') # # search(r'D:videopython20期day4') # # # #第二步:打开文件拿到文件对象f # def opener(): # while True: # abs_path=yield # print('opener func--->',abs_path) # # # target=opener() # next(target) #target.send('xxxx') # # g=search(target) # next(g) # g.send(r'D:videopython20期day4a') #分析二: # 第一步:拿到一个文件夹下所有的文件的绝对路径 import os def init(func): def inner(*args,**kwargs): g=func(*args,**kwargs) next(g) return g return inner @init def search(target): # r'D:videopython20期day4a' while True: filepath = yield g = os.walk(filepath) for pardir, _, files in g: for file in files: abs_path = r'%s\%s' % (pardir, file) #把abs_path传给下一个阶段 target.send(abs_path) # 第二步:打开文件拿到文件对象f @init def opener(target): while True: abs_path = yield with open(abs_path,'rb') as f: #把(abs_path,f)传给下一个阶段 target.send((abs_path,f)) #第三步:读取f的每一行内容 @init def cat(target): while True: abs_path,f=yield for line in f: #把(abs_path,line)传给下一个阶段 res=target.send((abs_path,line)) #满足某种条件,break掉for循环 if res: break #第四步:判断'python' in line @init def grep(target,pattern): pattern = pattern.encode('utf-8') res=False while True: abs_path,line=yield res res=False if pattern in line: #把abs_path传给下一个阶段 res=True target.send(abs_path) #第五步:打印文件路径 @init def printer(): while True: abs_path=yield print('<%s>' %abs_path) g=search(opener(cat(grep(printer(),'python')))) #'python' in b'xxxxx' g.send(r'D:videopython20期day4a') #面向过程编程:核心是过程二字,过程指的就是解决问题的步骤,即先干什么后干什么。。。。 #基于该思路编写程序就好比设计一条流水线,是一种机械式的思维方式 #优点:复杂的问题流程化、进而简单化 #缺点:可扩展性差
ps:函数的参数传入,是函数吃进去的食物,而函数return的返回值,是函数拉出来的结果,面向过程的思路就是,把程序的执行当做一串首尾相连的功能,该功能可以是函数的形式,然后一个函数吃,拉出的东西给另外一个函数吃,另外一个函数吃了再继续拉给下一个函数吃。。。
第3章 三元表达式、列表推导式、生成器表达式
3.1 三元表达式
name=input('姓名>>: ') res='SB' if name == 'alex' else 'NB' print(res)
实例一: def my_max(x,y): if x >= y: return x else: return y #以上函数演变为以下三元表达式: x=10 y=20 # res=x if x >= y else y ===>此为三元表达式 # print(res) 实例二: name=input('>>: ').strip() res='Sb' if name == 'alex' else 'NB' print(res)
3.2 列表推导式
#1、示例 egg_list=[] for i in range(10): egg_list.append('鸡蛋%s' %i) egg_list=['鸡蛋%s' %i for i in range(10)] #2、语法 [expression for item1 in iterable1 if condition1 for item2 in iterable2 if condition2 ... for itemN in iterableN if conditionN ] 类似于 res=[] for item1 in iterable1: if condition1: for item2 in iterable2: if condition2 ... for itemN in iterableN: if conditionN: res.append(expression) #3、优点:方便,改变了编程习惯,可称之为声明式编程
#1 列表推导式 # l=[] # for i in range(1,11): # res='egg'+str(i) # l.append(res) # # print(l) # l=['egg'+str(i) for i in range(1,11)] # print(l) # l1=['egg'+str(i) for i in range(1,11) if i >= 6] # print(l1) # l1=[] # for i in range(1,11): # if i >= 6: # l1.append('egg'+str(i))
3.3 生成器表达式
#1、把列表推导式的[]换成()就是生成器表达式 #2、示例:生一筐鸡蛋变成给你一只老母鸡,用的时候就下蛋,这也是生成器的特性 >>> chicken=('鸡蛋%s' %i for i in range(5)) >>> chicken <generator object <genexpr> at 0x10143f200> >>> next(chicken) '鸡蛋0' >>> list(chicken) #因chicken可迭代,因而可以转成列表 ['鸡蛋1', '鸡蛋2', '鸡蛋3', '鸡蛋4',] #3、优点:省内存,一次只产生一个值在内存中
#2 生成器表达式 # g=('egg'+str(i) for i in range(0,1000000000000000000000000000000000)) # print(g) # print(next(g)) # print(next(g)) # print(next(g))
3.4 声明式编程练习题
1、将names=['egon','alex_sb','wupeiqi','yuanhao']中的名字全部变大写 2、将names=['egon','alex_sb','wupeiqi','yuanhao']中以sb结尾的名字过滤掉,然后保存剩下的名字长度 3、求文件a.txt中最长的行的长度(长度按字符个数算,需要使用max函数) 4、求文件a.txt中总共包含的字符个数?思考为何在第一次之后的n次sum求和得到的结果为0?(需要使用sum函数) 5、思考题: with open('a.txt') as f: g=(len(line) for line in f) print(sum(g)) #为何报错? 6、文件shopping.txt内容如下: mac,20000,3 lenovo,3000,10 tesla,1000000,10 chicken,200,1 求总共花了多少钱? 打印出所有商品的信息,格式为[{'name':'xxx','price':333,'count':3},...] 求单价大于10000的商品信息,格式同上 题1: names=['egon','alex_sb','wupeiqi','yuanhao'] # names=[name.upper() for name in names] # print(names) 题2: names=['egon','alex_sb','wupeiqi','yuanhao'] # sbs=[name for name in names if name.endswith('sb')] # print(sbs) 题3: with open('a.txt',encoding='utf-8') as f: print(max(len(line) for line in f)) 题4: with open('a.txt', encoding='utf-8') as f: print(sum(len(line) for line in f)) print(sum(len(line) for line in f)) #求包换换行符在内的文件所有的字符数,为何得到的值为0? print(sum(len(line) for line in f)) #求包换换行符在内的文件所有的字符数,为何得到的值为0? #题目五(略) #题目六:每次必须重新打开文件或seek到文件开头,因为迭代完一次就结束了 with open('a.txt',encoding='utf-8') as f: info=[line.split() for line in f] cost=sum(float(unit_price)*int(count) for _,unit_price,count in info) print(cost) with open('a.txt',encoding='utf-8') as f: info=[{ 'name': line.split()[0], 'price': float(line.split()[1]), 'count': int(line.split()[2]), } for line in f] print(info) with open('a.txt',encoding='utf-8') as f: info=[{ 'name': line.split()[0], 'price': float(line.split()[1]), 'count': int(line.split()[2]), } for line in f if float(line.split()[1]) > 10000] print(info)
3.5 递归与二分法
3.5.1 递归调用的定义
#递归调用是函数嵌套调用的一种特殊形式,函数在调用时,直接或间接调用了自身,就是递归调用
3.5.2 递归分为两个阶段:递推,回溯
#递归必备的两个阶段:1、递推 2、回溯 # import sys # print(sys.getrecursionlimit()) # sys.setrecursionlimit(2000) # print(sys.getrecursionlimit()) # def func(n): # print('---->',n) # func(n+1) # # func(0) # def bar(): # print('from bar') # func() # # def func(): # print('from func') # bar() # # func() # age(5) = age(4) + 2 # age(4) = age(3) + 2 # age(3) = age(2) + 2 # age(2) = age(1) + 2 # # age(1) = 18 # age(n)=age(n-1)+2 # n > 1 # age(1) = 18 #n = 1 # def age(n): # if n == 1: # return 18 # return age(n-1) + 2 # # res=age(5) # print(res) # l=[1,[2,[3,[4,[5,[6,[7,]]]]]]] # # # def func(l): # for item in l: # if type(item) is list: # func(item) # else: # print(item) # def func(): # print('===>') # func() # # func()
#图解。。。 # salary(5)=salary(4)+300 # salary(4)=salary(3)+300 # salary(3)=salary(2)+300 # salary(2)=salary(1)+300 # salary(1)=100 # # salary(n)=salary(n-1)+300 n>1 # salary(1) =100 n=1 def salary(n): if n == 1: return 100 return salary(n-1)+300 print(salary(5))
3.5.3 python中的递归效率低且没有尾递归优化
#python中的递归 python中的递归效率低,需要在进入下一次递归时保留当前的状态,在其他语言中可以有解决方法:尾递归优化,即在函数的最后一步(而非最后一行)调用自己,尾递归优化:http://egon09.blog.51cto.com/9161406/1842475 但是python又没有尾递归,且对递归层级做了限制 #总结递归的使用: 1. 必须有一个明确的结束条件 2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少 3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
3.5.4 可以修改递归最大深度
import sys sys.getrecursionlimit() sys.setrecursionlimit(2000) n=1 def test(): global n print(n) n+=1 test() test() 虽然可以设置,但是因为不是尾递归,仍然要保存栈,内存大小一定,不可能无限递归
3.6 二分法
想从一个按照从小到大排列的数字列表中找到指定的数字,遍历的效率太低,用二分法(算法的一种,算法是解决问题的方法)可以极大低缩小问题规模
3.6.1 实现类似于in的效果
l=[1,2,10,30,33,99,101,200,301,402] #从小到大排列的数字列表 def search(num,l): print(l) if len(l) > 0: mid=len(l)//2 if num > l[mid]: #in the right l=l[mid+1:] elif num < l[mid]: #in the left l=l[:mid] else: print('find it') return search(num,l) else: #如果值不存在,则列表切为空 print('not exists') return search(100,l)
3.6.2 实现类似于l.index(30)的效果
l=[1,2,10,30,33,99,101,200,301,402] def search(num,l,start=0,stop=len(l)-1): if start <= stop: mid=start+(stop-start)//2 print('start:[%s] stop:[%s] mid:[%s] mid_val:[%s]' %(start,stop,mid,l[mid])) if num > l[mid]: start=mid+1 elif num < l[mid]: stop=mid-1 else: print('find it',mid) return search(num,l,start,stop) else: #如果stop > start则意味着列表实际上已经全部切完,即切为空 print('not exists') return search(301,l)
3.6.3 小练习
#了解的知识点 l=[1,2,10,30,33,99,101,200,301,402] #从小到大排列的数字列表 def binary_search(l,num): print(l) if len(l) == 0: print('not exists') return mid_index=len(l) // 2 if num > l[mid_index]: #往右找 binary_search(l[mid_index+1:],num) elif num < l[mid_index]: #往左找 binary_search(l[0:mid_index],num) else: print('find it') # binary_search(l,301) binary_search(l,302)
第4章 匿名函数与内置函数
4.1 什么是匿名函数?
匿名就是没有名字 def func(x,y,z=1): return x+y+z 匿名 lambda x,y,z=1:x+y+z #与函数有相同的作用域,但是匿名意味着引用计数为0,使用一次就释放,除非让其有名字 func=lambda x,y,z=1:x+y+z func(1,2,3) #让其有名字就没有意义
4.2 有名字的函数与匿名函数的对比
#有名函数与匿名函数的对比
有名函数:循环使用,保存了名字,通过名字就可以重复引用函数功能
匿名函数:一次性使用,随时随时定义
应用:max,min,sorted,map,reduce,filter
4.3 实例
# def func(): #func=内存地址 # print('from func') # # func() # func() # 内存地址 # def my_sum(x,y): # return x+y # print(lambda x,y:x+y) # print((lambda x,y:x+y)(1,2)) # func=lambda x,y:x+y # # print(func) # print(func(1,2)) #max,min,sorted,map,reduce,filter # salaries={ # 'egon':3000, # 'alex':100000000, # 'wupeiqi':10000, # 'yuanhao':2000 # } # print(max(salaries)) # s='hello' # l=[1,2,3] # g=zip(s,l) # # print(g) # print(list(g)) # g=zip(salaries.values(),salaries.keys()) # # print(list(g)) # print(max(g)) # def func(k): # return salaries[k] # print(max(salaries,key=func)) #key=func('egon') # print(max(salaries,key=lambda k:salaries[k])) #key=func('egon') # print(min(salaries,key=lambda k:salaries[k])) #key=func('egon') #sorted # salaries={ # 'egon':3000, # 'alex':100000000, # 'wupeiqi':10000, # 'yuanhao':2000 # } # print(sorted(salaries,key=lambda k:salaries[k])) # print(sorted(salaries,key=lambda k:salaries[k],reverse=True)) #map,reduce,filter # names=['alex','wupeiqi','yuanhao'] # l=[] # for name in names: # res='%s_SB' %name # l.append(res) # # print(l) # g=map(lambda name:'%s_SB' %name,names) # # print(g) # print(list(g)) # names=['alex_sb','wupeiqi_sb','yuanhao_sb','egon'] # g=filter(lambda x:x.endswith('sb'),names) # print(g) # print(list(g)) from functools import reduce print(reduce(lambda x,y:x+y,range(1,101),100))
4.4 内置函数
#注意:内置函数id()可以返回一个对象的身份,返回值为整数。这个整数通常对应与该对象在内存中的位置,但这与python的具体实现有关,不应该作为对身份的定义,即不够精准,最精准的还是以内存地址为准。is运算符用于比较两个对象的身份,等号比较两个对象的值,内置函数type()则返回一个对象的类型
#更多内置函数:https://docs.python.org/3/library/functions.html?highlight=built#ascii

4.4.1 format(了解即可)
#字符串可以提供的参数 's' None >>> format('some string','s') 'some string' >>> format('some string') 'some string' #整形数值可以提供的参数有 'b' 'c' 'd' 'o' 'x' 'X' 'n' None >>> format(3,'b') #转换成二进制 '11' >>> format(97,'c') #转换unicode成字符 'a' >>> format(11,'d') #转换成10进制 '11' >>> format(11,'o') #转换成8进制 '13' >>> format(11,'x') #转换成16进制 小写字母表示 'b' >>> format(11,'X') #转换成16进制 大写字母表示 'B' >>> format(11,'n') #和d一样 '11' >>> format(11) #默认和d一样 '11' #浮点数可以提供的参数有 'e' 'E' 'f' 'F' 'g' 'G' 'n' '%' None >>> format(314159267,'e') #科学计数法,默认保留6位小数 '3.141593e+08' >>> format(314159267,'0.2e') #科学计数法,指定保留2位小数 '3.14e+08' >>> format(314159267,'0.2E') #科学计数法,指定保留2位小数,采用大写E表示 '3.14E+08' >>> format(314159267,'f') #小数点计数法,默认保留6位小数 '314159267.000000' >>> format(3.14159267000,'f') #小数点计数法,默认保留6位小数 '3.141593' >>> format(3.14159267000,'0.8f') #小数点计数法,指定保留8位小数 '3.14159267' >>> format(3.14159267000,'0.10f') #小数点计数法,指定保留10位小数 '3.1415926700' >>> format(3.14e+1000000,'F') #小数点计数法,无穷大转换成大小字母 'INF' #g的格式化比较特殊,假设p为格式中指定的保留小数位数,先尝试采用科学计数法格式化,得到幂指数exp,如果-4<=exp<p,则采用小数计数法,并保留p-1-exp位小数,否则按小数计数法计数,并按p-1保留小数位数 >>> format(0.00003141566,'.1g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留0位小数点 '3e-05' >>> format(0.00003141566,'.2g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留1位小数点 '3.1e-05' >>> format(0.00003141566,'.3g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留2位小数点 '3.14e-05' >>> format(0.00003141566,'.3G') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留0位小数点,E使用大写 '3.14E-05' >>> format(3.1415926777,'.1g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留0位小数点 '3' >>> format(3.1415926777,'.2g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留1位小数点 '3.1' >>> format(3.1415926777,'.3g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留2位小数点 '3.14' >>> format(0.00003141566,'.1n') #和g相同 '3e-05' >>> format(0.00003141566,'.3n') #和g相同 '3.14e-05' >>> format(0.00003141566) #和g相同 '3.141566e-05'
4.4.2 !!!lambda与内置函数结合使用!!!
字典的运算:最小值,最大值,排序 salaries={ 'egon':3000, 'alex':100000000, 'wupeiqi':10000, 'yuanhao':2000 } 迭代字典,取得是key,因而比较的是key的最大和最小值 >>> max(salaries) 'yuanhao' >>> min(salaries) 'alex' 可以取values,来比较 >>> max(salaries.values()) >>> min(salaries.values()) 但通常我们都是想取出,工资最高的那个人名,即比较的是salaries的值,得到的是键 >>> max(salaries,key=lambda k:salary[k]) 'alex' >>> min(salaries,key=lambda k:salary[k]) 'yuanhao' 也可以通过zip的方式实现 salaries_and_names=zip(salaries.values(),salaries.keys()) 先比较值,值相同则比较键 >>> max(salaries_and_names) (100000000, 'alex') salaries_and_names是迭代器,因而只能访问一次 >>> min(salaries_and_names) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: min() arg is an empty sequence sorted(iterable,key=None,reverse=False)
4.4.3 eval与exec
#1、语法 # eval(str,[,globasl[,locals]]) # exec(str,[,globasl[,locals]]) #2、区别 #示例一: s='1+2+3' print(eval(s)) #eval用来执行表达式,并返回表达式执行的结果 print(exec(s)) #exec用来执行语句,不会返回任何值 ''' 6 None ''' #示例二: print(eval('1+2+x',{'x':3},{'x':30})) #返回33 print(exec('1+2+x',{'x':3},{'x':30})) #返回None # print(eval('for i in range(10):print(i)')) #语法错误,eval不能执行表达式 print(exec('for i in range(10):print(i)'))
4.4.4 complie(了解即可)
compile(str,filename,kind) filename:用于追踪str来自于哪个文件,如果不想追踪就可以不定义 kind可以是:single代表一条语句,exec代表一组语句,eval代表一个表达式 s='for i in range(10):print(i)' code=compile(s,'','exec') exec(code) s='1+2+3' code=compile(s,'','eval') eval(code)
4.5 阶段性练习
1、文件内容如下,标题为:姓名,性别,年纪,薪资 egon male 18 3000 alex male 38 30000 wupeiqi female 28 20000 yuanhao female 28 10000 要求: 从文件中取出每一条记录放入列表中, 列表的每个元素都是{'name':'egon','sex':'male','age':18,'salary':3000}的形式 2 根据1得到的列表,取出薪资最高的人的信息 3 根据1得到的列表,取出最年轻的人的信息 4 根据1得到的列表,将每个人的信息中的名字映射成首字母大写的形式 5 根据1得到的列表,过滤掉名字以a开头的人的信息 6 使用递归打印斐波那契数列(前两个数的和得到第三个数,如:0 1 1 2 3 4 7...) 7 一个嵌套很多层的列表,如l=[1,2,[3,[4,5,6,[7,8,[9,10,[11,12,13,[14,15]]]]]]],用递归取出所有的值
#1 with open('db.txt') as f: items=(line.split() for line in f) info=[{'name':name,'sex':sex,'age':age,'salary':salary} for name,sex,age,salary in items] print(info) #2 print(max(info,key=lambda dic:dic['salary'])) #3 print(min(info,key=lambda dic:dic['age'])) # 4 info_new=map(lambda item:{'name':item['name'].capitalize(), 'sex':item['sex'], 'age':item['age'], 'salary':item['salary']},info) print(list(info_new)) #5 g=filter(lambda item:item['name'].startswith('a'),info) print(list(g)) #6 #非递归 def fib(n): a,b=0,1 while a < n: print(a,end=' ') a,b=b,a+b print() fib(10) #递归 def fib(a,b,stop): if a > stop: return print(a,end=' ') fib(b,a+b,stop) fib(0,1,10) #7 l=[1,2,[3,[4,5,6,[7,8,[9,10,[11,12,13,[14,15]]]]]]] def get(seq): for item in seq: if type(item) is list: get(item) else: print(item) get(l)
第5章 作业
作业需求: 模拟实现一个ATM + 购物商城程序 额度 15000或自定义 实现购物商城,买东西加入 购物车,调用信用卡接口结账 可以提现,手续费5% 每月22号出账单,每月10号为还款日,过期未还,按欠款总额 万分之5 每日计息 支持多账户登录 支持账户间转账 记录每月日常消费流水 提供还款接口 ATM记录操作日志 提供管理接口,包括添加账户、用户额度,冻结账户等。。。 用户认证用装饰器 示例代码 https://github.com/triaquae/py3_training/tree/master/atm 简易流程图:https://www.processon.com/view/link/589eb841e4b0999184934329 作业要求: 下周五中午十二点之前交: 1,本周博客。 2,作业流程图。 3,实现作业中任意五个功能 作业位置:http://www.cnblogs.com/linhaifeng/articles/7532512.html 预习博客是在本次作业博客的下一篇!希望各位利用元旦假期的时间,复习之前的知识,预习下周要讲的东西,大家加油,争取用最短的时间拿下python
####简易流程图
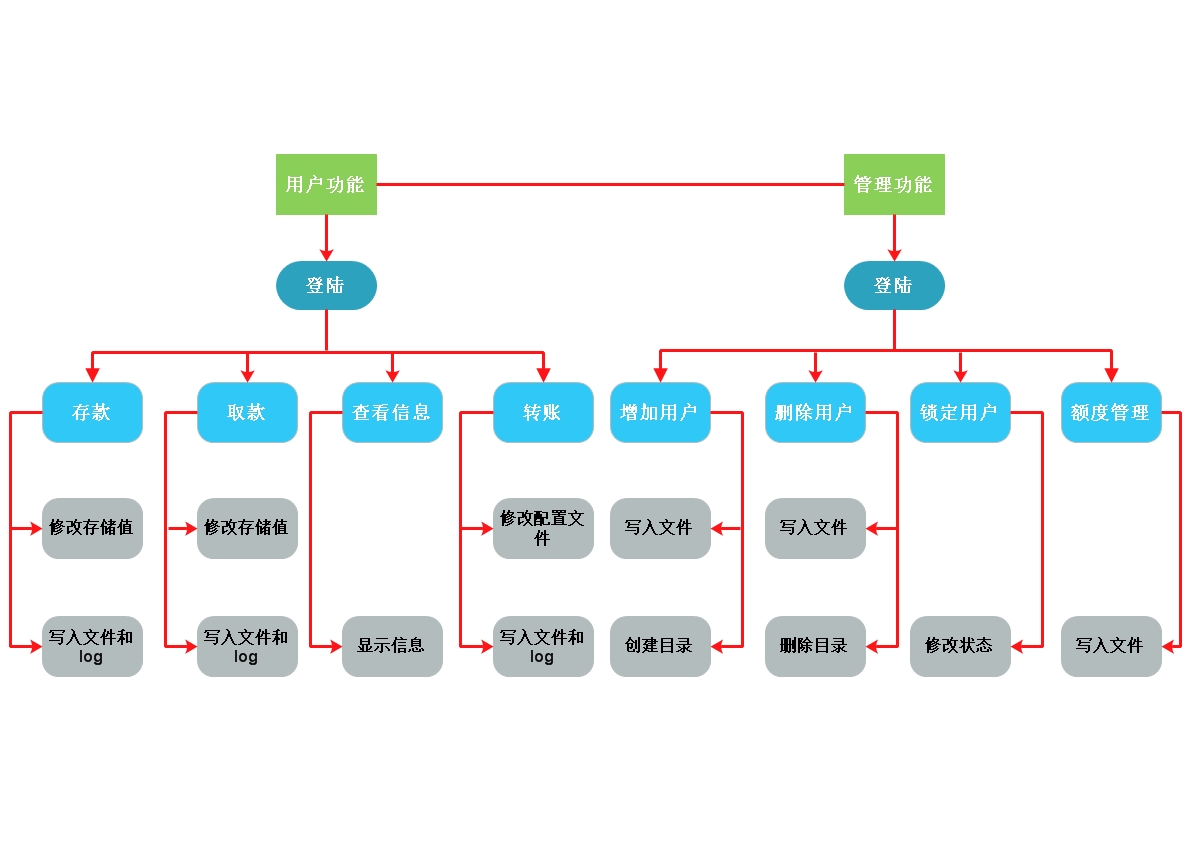
####说明

ATM.py为核心代码文件
其他为引用写入文件(商城商品列表文件shoplist.txt,账户余额usercardmoney.txt,信用卡登陆账号userinfo.txt,信用卡消费记录xiaofeilist.txt)
#!/usr/bin/python # --*-- coding:utf-8 --*-- import time#引入时间模块 import datetime#引入日期小时 ''' 各种全局变量、与全局参数 ''' tempusercardmoney = []#定义用户信用卡临时消费总额度的列表 f9 = open('usercardmoney.txt','r',encoding='utf-8')#只读打开用户消费信用卡总额度文件 for p in f9.readlines():#读取用户消费信用卡总额度文件中每行内容 tempusercardmoney.append(p)#读取用户消费信用卡总额度文件中每行内容,到用户信用卡临时消费总额度的列表,对用户查询用户可用额度有用 #print p f9.close() #print int(tempusercardmoney[0]) inittotalmoney = int(tempusercardmoney[0])#从用户信用卡临时消费总额度的列表的第一个元素,把数据变成整形数据,赋值初始总可用额度 shishitotalmoney = []#实时变化的总余额列表 shishitotalmoney.append(inittotalmoney)#把初始总可用额度值增加到实时消费总额度的列表中 shouxufei = []#总手续费变化列表 jiamoney = []#金钱增加的列表 jianmoney = []#金钱减少的列表 buyshop = []#消费商场购物购买的商品 ''' 读取当前系统的时间 ''' def curtime(): #now = int(time.time()) now = datetime.datetime.now()#获取当前时间时分秒 otherstyletime = now.strftime('%Y-%m-%d %H:%M:%S')#显示当前时间的时分秒 #print otherstyletime return otherstyletime#返回当前时间的时分秒 ''' 查询账单要求:所有用户共享一个xiaofeilist.txt文件,用户查询只显示当前用户账单信息, 还款记录在日志中高亮显示出来,用户查询显示收入、支出和消费总额(此条未实现) ''' def searchbill(): gudingedu = 15000#固定总额度 bl_hktotalmoney = gudingedu - shishitotalmoney[-1]#账单还款总额度等于固定总额度减去实时花费的总额度 bl_min_hktotalmoney = bl_hktotalmoney*0.01#最低还款额度等于账单还款总额度的百分之一 print('信用卡总额度为15000¥,信用卡可用额度为%d,本期还款总额为%d,本期最低还款额度为%d' %(shishitotalmoney[-1],bl_hktotalmoney,bl_min_hktotalmoney)) print('-'*79) bl_file = open('xiaofeilist.txt','r',encoding='utf-8')#只读打开消费清单文件 for p in bl_file.readlines():#读取消费清单文件中每行内容 print(p) bl_file.close() ''' 消费商城要求: 1、产品及产品价格 2、消费后扣除价格:判断账户余额是否足够,将消费记录写入xiaofeilist.txt账单 ''' def buy():#消费商城 products = []#定义可以购买商品名称的列表 prices = []#定义可以购买商品价格的列表 xf_money = 0#初始商品的价格 xf_date = []#定义消费购物清单列表 f_shoplist = open('shoplist.txt','r',encoding='utf-8')#只读方式打开商城可以购买的商品文件 for p in f_shoplist.readlines():#每行数据读取 new_p = p.split()#对商城可以购买的商品文件中每个元素进行空格分割 products.append(new_p[0])#把每行读取的元素第一个值赋值给购买商品名称的列表 prices.append(new_p[1])#把每行读取的元素第二个值赋值给购买商品价格的列表 print(products) print(prices) while True: choice = input('请输入要购买的产品:')#输入需要购买的商品名称 f_choice = choice.strip()#对输入的商品名称进行整块前后空格过滤 #print f_choice if f_choice != 'q':#如果输入不是字母q,则进入 if f_choice in products:#如果输入商品名称在可以购买商品名称的列表中,则进入 #print products.index(f_choice)#可以购买的商品在可以购买商品名称的列表中索引编号 xf_money = int(prices[products.index(f_choice)])#利用可以购买的商品在可以购买商品名称的列表中索引编号,来定位对应的价格,为整形 #print type(xf_money)#打印类型 #print shishitotalmoney[-1]#打印实时变化的且可用的余额 if xf_money <= shishitotalmoney[-1] and shishitotalmoney[-1] > 0:#输入的商品价格小于可用余额,并可用余额大于0 buyshop.append(f_choice)#把成功购买的商品加入全局的购物清单中 jianmoney.append(xf_money)#把成功购买的商品价格增加到全局的减金额的列表中 curtime()#引入当前时间函数,查看当前交易时间 xf_date.append(curtime())#把当前交易时间增加到消费购物清单列表 xf_date.append(str(f_choice))#把成功购买的商品增加到消费购物清单列表 xf_date.append(str(xf_money))#把成功购买商品价格增加到消费购物清单列表 xf_date.append('0')#把购物手续费0元增加到消费购物清单列表 #print xf_date #print buyshop,jianmoney print('恭喜你购买了%s' %f_choice) creditcardmoneyleft()#引入总余额函数,查看当前可以余额,必须放到减金额列表才能实时查看余额 f7 = open('xiaofeilist.txt','a+',encoding='utf-8')#使用追加写入的方式打开消费清单文件 f7.write(xf_date[-4])#把交易时间列表中倒数第4个元素写入消费清单中 f7.write(' ')#把一个tab写入消费清单中 f7.write('购买:')#写入‘购买’说明信息 f7.write(xf_date[-3])#把交易时间列表中倒数第三个元素写入消费清单中 f7.write(' ') f7.write(xf_date[-2])#把交易时间列表中倒数第二个元素写入消费清单中 f7.write(' ') f7.write(xf_date[-1])#把交易时间列表倒数中第一个元素写入消费清单中 f7.write(' ') f7.close() else: print('余额不足!请存入足够的金额进行购买!按q键退出购物!') else: print('你购买的商品,商铺清单没有!请选择商铺存在的物品!') else: print('你购买的清单如下:') print(buyshop) break#退出该函数模块 ''' 存款要求:额度不能低于100,额度不能高于2000,必须为100的整数倍, 存款金额只能为数字为字母时会提示,将该笔写入xiaofeilist.txt账单 ''' def deposit():#存款 ck_totalmoney = 0#初始存款的总金额 ck_shouxufei = 0#初始存款的手续费金额 ck_date = []#定义交易时间列表 while True: ck_money = int(input('额度不低于100,不高于2000,必须为100整数倍,请输入你要存款的金额:'))#输入存款金额 if ck_money%100 == 0:#存款金额为100的整数倍 if ck_money > 99 and ck_money < 2001:#存款金额不低于100,不高于2000 curtime()#引入当前时间函数,计算当前存款的时间 ck_date.append(curtime())#把当前时间值加入交易时间列表中 ck_date.append(str(ck_money))#把当前输入的存款金额转换成字符存入交易时间列表中 ck_date.append(str(ck_shouxufei))#把当前输入存款的手续费金额转换成字符存入交易时间列表中 print('你存入的金额为%d' % ck_money) jiamoney.append(ck_money)#把存款金额加入金钱增加的列表 creditcardmoneyleft()#引入总余额函数,查看当前可以余额,必须放到加金额列表才能实时查看余额 f6 = open('xiaofeilist.txt','a+',encoding='utf-8')#使用追加写入的方式打开消费清单文件 f6.write(ck_date[0])#把交易时间列表中第一个元素写入消费清单中 f6.write(' ')#把一个tab写入消费清单中 f6.write('存款')#写入‘存款’说明信息 f6.write(' ') f6.write(ck_date[1])#把交易时间列表中第二个元素写入消费清单中 f6.write(' ') f6.write(ck_date[2])#把交易时间列表中第三个元素写入消费清单中 f6.write(' ') f6.close() break#退出该函数模块 else: print('你输入的存款金额不能低于100元,不能高于2000元!') else: print('输入的存款金额不为100的整数倍,请输入100整数倍!') ''' 取款要求:额度不能低于100,额度不能高于2000,必须为100的整数倍,扣除% 5的手续费, 取现额度不能超过余额,取款金额只能为数字为字母时会提示,将该笔记录写入xiaofeilist.txt账单 ''' def withdraw():#取款 qk_totalmoney = 0#初始取款的总金额 qu_shouxufei = 0#初始取款的手续费 qk_date = []#定义交易时间列表 while True: qk_money = int(input('取款金额不低于100元,不高于2000元,为100整数倍,请输入取款金额:'))#输入取款金额 if qk_money < shishitotalmoney[-1] and shishitotalmoney[-1] > 0 and qk_money > 0:#取款金额小于总可用余额,总可用余额大于0,取款金额大于0 print(shishitotalmoney[-1]) if qk_money%100 == 0:#取款金额为100的整数倍 if qk_money > 99 and qk_money < 2001:#取款金额不低于100,不高于2000 qk_shouxufei = qk_money * 0.05#计算取款手续费 qk_totalmoney = qk_money + qk_shouxufei#取款总金额 curtime()#引入当前时间函数 qk_date.append(curtime())#把当前时间值加入交易时间列表中 qk_date.append(str(qk_totalmoney))#把当前输入的取款金额转换成字符存入交易时间列表中 qk_date.append(str(qk_shouxufei))#把当前输入取款的手续费金额转换成字符存入交易时间列表中 jianmoney.append(qk_money)#把取款金额加入金钱减少的列表 shouxufei.append(qk_shouxufei)#把手续费金额加入金钱减少的列表 #print qk_date[1],qk_date[2] print('取款实际金额为%d元,手续费为%d元,总取款花费金额为%d元' %(qk_money,qk_shouxufei,qk_totalmoney)) creditcardmoneyleft()#引入总余额函数,查看当前可以余额,必须放到减金额列表才能实时查看余额 f5 = open('xiaofeilist.txt','a+',encoding='utf-8')#使用追加写入的方式打开消费清单文件 f5.write(qk_date[0])#把交易时间列表中第一个元素写入消费清单中 f5.write(' ') f5.write('取款') f5.write(' ') f5.write(qk_date[1])#把交易时间列表中第二个元素写入消费清单中 f5.write(' ') f5.write(qk_date[2])#把交易时间列表中第三个元素写入消费清单中 f5.write(' ') f5.close() break#退出该函数模块 else: print('你输入的取款金额不能低于100元,不能高于2000元!') else: print('输入的取款金额不为100的整数倍,请输入100整数倍!') else: print('你输入的取款金额超过总余额,请重新输入大于0的金额!') ''' 查询当前账户可用余额 ''' def creditcardmoneyleft():#查询当前可用余额 zhengtotalmoney = 0#初始正符号的总金额 futotalmoney = 0#初始负符号的总金额 jiatotalmoney = []#定义加的总金额的列表 jiantotalmoney = []#定义减的总金额的列表 for p in range(len(shouxufei)):#遍历手续费列表中所有元素 #print shouxufei[p] jiantotalmoney.append(shouxufei[p])#把手续费的每个元素增加到‘减的总金额列表’中 for m in range(len(jianmoney)):#遍历减金额列表中所有元素 #print jianmoney[m] jiantotalmoney.append(jianmoney[m])##把减金额的每个元素增加到‘减的总金额列表’中 for n in range(len(jiamoney)):#遍历加金额列表中所有元素 #print jiamoney[n] jiatotalmoney.append(jiamoney[n])#把加金额的每个元素增加到‘加的总金额列表’中 for i in range(len(jiatotalmoney)):#遍历加的金额列表中所有元素 #print jiatotalmoney[i] zhengtotalmoney = zhengtotalmoney + jiatotalmoney[i]#计算正符号金额总额 for j in range(len(jiantotalmoney)):#遍历减的金额列表中所有元素 #print jiantotalmoney[j] futotalmoney = futotalmoney + jiantotalmoney[j]#计算负符号金额总额 totalmoney = inittotalmoney + zhengtotalmoney - futotalmoney#计算总余额 shishitotalmoney.append(totalmoney)#把实时变化的总余额增加到shishitotalmoney列表中 f8 = open('usercardmoney.txt','w',encoding='utf-8')#写入方式打开用户消费信用卡总额度文件 f8.write(str(int(totalmoney)))#总金额变成整形数据,然后变成字符类型写入用户消费信用卡总额度文件 f8.close() print('-'*31) print('你的总可用的余额为%d' %totalmoney) print('-'*31) ''' 修改密码要求:旧密码验证后才能提示修改新密码 新密码需输入两次。两次相同即可通过 密码长度必须在6位以上 ''' def modpassword(): pd_oldtmp = []#定义临时修改旧密码列表 pd_old = input('请输入信用卡的旧的密码:')#输入旧密码 f3 = open('userinfo.txt','r',encoding='utf-8')#只读打开用户信息文件 for p in f3.readlines():#每行读取用户信息文件内容 new_p = p.split()[1]#对用户信息文件中元素使用空格分割,并把第二个元素值赋值给new_p #print new_p pd_oldtmp.append(new_p)#把赋值给new_p的值增加到临时修改旧密码列表中 if pd_old == pd_oldtmp[0]:#如果输入旧密码与存入临时修改旧密码列表中第一个元素值相等,则进入 moduser = []#定义修改用户列表 modpd = []#定义修改密码列表 moduserinfo = []#定义修改用户、密码列表 f1 = open('userinfo.txt','r',encoding='utf-8')#只读打开用户信息文件 #print type(f1) for p in f1.readlines():#每行读取用户信息文件内容 new_p = p.split()#对用户信息文件中元素使用空格分割,并把每个元素值循环赋值给new_p moduser.append(new_p[0])#把取到的第一个元素增加到修改用户列表中 modpd.append(new_p[1])#把取到的第二个元素增加到修改用户列表中 f1.close() #print moduser,modpd moduserinfo.append(moduser[0])#把修改用户的第一个元素值增加到‘修改用户、密码列表’中 moduserinfo.append(modpd[0])#把修改密码的第一个元素值增加到’修改用户、密码列表‘中 pd_new1 = input('请输入新信用卡密码,至少6位以上:')#第一次输入的密码值 pd_new2 = input('请再次输入新信用卡密码,至少6位以上:')#第二次输入的密码值 if pd_new1 == pd_new2:#如果第一次输入的密码值与第二次输入的密码值相等,则进入 #print moduserinfo moduserinfo[1] = pd_new1#把第一次输入的密码值赋值到‘修改用户、密码列表’中第二个元素 #print moduserinfo f1 = open('userinfo.txt','w',encoding='utf-8')#写入模块打开用户信息文件 f1.write('')#把用户信息文件所有内容清空 f1.close() f2 = open('userinfo.txt','a+',encoding='utf-8')#追加写入模式打开用户信息文件 f2.write(moduserinfo[0])#把修改用户、密码列表’中第一个元素用户写入用户信息文件中 f2.write(' ') f2.write(moduserinfo[1])#把修改用户、密码列表’中第二个元素用户写入用户信息文件中 f2.close() print('恭喜您!信用卡密码修改成功!') else: print('你输入的两次新的信用卡密码不相同!请重新输入!') else: print('你输入的信用卡密码错误,请重新输入!') ''' 转账要求:额度不能低于100元,额度不能高于20000元 必须为100的整数倍,扣除手续费10% 将该笔记录写入账单中 ''' def tranfer(): tr_totalmoney = 0#初始转账总金额 tr_shouxufei = 0#初始转账手续费 tr_date = []#定义转账交易时间清单列表 while True: tr_money = int(input('转账金额不低于100元,不高于2000元,为100整数倍,请输入转账金额:'))#输入转账金额 if tr_money < shishitotalmoney[-1] and shishitotalmoney[-1] > 0 and tr_money > 0:#转账金额小于总余额,总余额与转账金额必须大于0 if tr_money%100 == 0:#转账金额为100整数倍 if tr_money > 99 and tr_money < 2001:#转账金额大于100,不高于2000 tr_shouxufei = tr_money*0.1#计算转账手续费 tr_totalmoney = tr_money + tr_shouxufei#计算转账总金额 curtime()#引入当前交易时间函数 tr_date.append(curtime())#增加当前时间到转账交易时间清单列表中 tr_date.append(str(tr_totalmoney))#增加转账总金额到转账交易时间清单列表中 tr_date.append(str(tr_shouxufei))##增加转账手续费到转账交易时间清单列表中 #print tr_date[1],tr_date[2] jianmoney.append(tr_money)#把转账金额增加到加金额列表中 shouxufei.append(tr_shouxufei)#把转账手续费增加到手续费列表中 print('转账实际金额为%d元,手续费为%d元,总转账金额花费为%d元' %(tr_money,tr_shouxufei,tr_totalmoney)) creditcardmoneyleft()#引入总余额函数,查看当前可以余额,必须放到减金额列表才能实时查看余额 f4 = open('xiaofeilist.txt','a+',encoding='utf-8')#追加写入方式打开消费清单文件 f4.write(tr_date[0])#把转账交易时间清单列表中第一个元素写入消费清单文件中 f4.write(' ') f4.write('转账') f4.write(' ') f4.write(tr_date[1])##把转账交易时间清单列表中第二个元素写入消费清单文件中 f4.write(' ') f4.write(tr_date[2])#把转账交易时间清单列表中第三个元素写入消费清单文件中 f4.write(' ')#换行写入 f4.close() break#退出该函数模块 else: print('你输入的转账金额不能低于100元,不能高于2000元!') else: print('输入的转账金额不为100的整数倍,请输入100整数倍!') else: print('你输入的转账金额超过总余额,请重新输入大于0的金额!') def gongneng():#选择的业务功能模块 print(''' 请选择操作的业务:(输入q退出系统) (1) 消费商城购物 (2) 查询余额 (3) 存款 (4) 取款 (5) 转账 (6) 查询账单 (7) 修改密码 ''') while True: choice = input('请输入需要操作业务编号:') f_choice = choice.strip() #除去空格 if f_choice != 'q': if f_choice != ''or f_choice ==1 or f_choice ==2 or f_choice ==3 or f_choice ==4 or f_choice ==6 or f_choice ==7: if f_choice == '1': buy() elif f_choice == '2': creditcardmoneyleft() elif f_choice == '3': deposit() elif f_choice == '4': withdraw() elif f_choice == '5': tranfer() elif f_choice == '6': searchbill() elif f_choice == '7': modpassword() else: continue else: print('你已经退出中国银行ATM取款系统!欢迎下次光临!') exit() ''' 多个账户(未实现)/单个账户登录验证,密码输入超过三次错误冻结帐号30秒 ''' while True: counttime = 5#初始锁定时间值 count = 3#初始初始次数 user = []#定义用户列表 pd = []#定义密码列表 file = open('userinfo.txt','r+',encoding='utf-8')#只读打开用户信息文件 for p in file.readlines():#每行读取用户信息文件 new_p = p.split()#把每个元素空格分割,并循环赋值给new_p user.append(new_p[0])#把new_p取到的第一个元素增加到用户列表中 pd.append(new_p[1])#把new_p取到的第二个元素增加到用户列表中 file.close() #print user[0],pd[0] creditcard = input('请输入信用卡卡号:')#输入用户信用卡信息 #f_creditcard = creditcard.strip() if creditcard == user[0]:#如果输入用户信用卡信息与用户列表中第一个元素相等,则进入 creditcardpd = pd[0]#把密码列表中第一个元素赋值给creditcardpd while True: if count != 0:#如果锁定次数不等于0,初始值为3,则进入 creditcardpassword = input('请输入信用卡密码:')#输入用户密码 #f_creditcardpassword = creditcardpassword.strip() if creditcardpassword != creditcardpd:#如果不想等,则进入 count -= 1#每次循环递减1次 print('输入的密码不对,还有%d次机会,请重新输入密码' %count) else: print('恭喜你!欢迎进入中国银行ATM取款系统!') curtime()#引入当前时间函数 gongneng()#引入业务功能函数 else: print('对不起,你输入密码错误次数已达到3次,将锁定5秒!') timeseconds = 0#设置锁定时间值,锁定功能,倒计时 while (counttime != timeseconds):#锁定时间参数不等于设置锁定时间值,则进入 time.sleep(1)#5秒倒计时 counttime -= 1#每次减少一秒 print(counttime) break#倒计到0秒退出,跳到用户输入信用卡帐号 else: print('输入的信用卡号%s错误!请重新输入你的信用卡号码!' %creditcard)
2018-01-02 22:13:44 购买:mouse 799 0 2018-01-02 22:14:10 存款 2000 0 2018-01-02 22:14:20 存款 2000 0 2018-01-02 22:14:30 取款 105.0 5.0 2018-01-02 22:14:43 转账 110.0 10.0 2018-01-03 11:09:13 存款 2000 0 2018-01-03 11:09:24 取款 105.0 5.0 2018-01-03 11:09:52 转账 110.0 10.0
6321
1234567890 123456
BMW 50000 computer 15000 iphone 6999 TV 2089 LVbag 799 book 69 Apple 12