同类数据具有一定的统计规律性。
随机变量->数据特征;概率分布->数据规律

步骤如下:






过拟合——学习时选择的模型所包含的参数过多,以至于出现这一模型对已知数据预测得很好,但对未知数据预测得很差的现象。

M次多项式函数拟合问题

泛化能力——指学习方法对未知数据的预测能力。
选择经验风险与模型复杂度同时较小的模型。
交叉验证

把给定的数据进行切分,将切分的数据集组合为训练集和测试集,在此基础上反复地进行训练、测试以及模型选择。
- 简单交叉验证:用训练集在不同条件下训练模型,得到不同的模型;在测试集上评价各模型基于损失模型测试误差,选出测试误差最小的模型。
- S折交叉验证:随机将已给数据切分为S个互不相交的相同的子集;利用S-1个子集的数据训练模型,利用余下的子集测试模型;将这一过程对可能的S种选择重复进行;最后选出S次评测中平均测试误差最小的误差。
- 留一交叉验证:S折交叉验证中,S=N=数据集的容量。
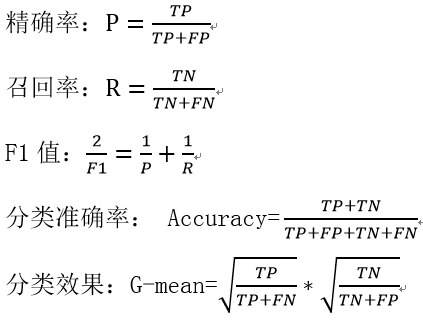
分类问题
分类——分类器对新的输入进行输出的预测,输出变量Y取有限个离散值。
|
预测正类数 |
预测负类数 |
|
|
实际正类数 |
TP |
FN |
|
实际负类数 |
FP |
TN |