首先,分清楚一个概念:抽样和随机化
抽样sampling是从整体抽出一部分样本。随机化randomization是将样本分到不同的组,使得各组covariate-adaptive,即组间均衡可比
1,完全随机complete randomization
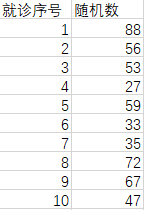
10个患者,随机分两组。
首先按照就诊次序牌排序,。然后成一组随机数(10个),顺序不变赋值给患者序号。
将随机数这列从小到大排列,前五个组1,后五个组2。上图
 到-----
到-----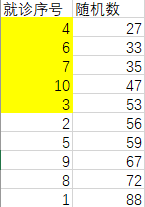
2,分层随机化
将样本按照某一特征分组(block),比如体重相近、同一窝别、BMI接近等,分为若干区组。
区组数一般2、4、6,然后再在组内随机分组
方式1:
将15名患者分为A、B、C三个治疗组
![]()
按照体重将患者分为5组,编号
选一组随即数列
将每个区组内(同一颜色)的随机数的大小 标明。1号为A组,2号为B组,3号为C组
方式2:
将16只小鼠分为A、B两组

按照窝别分为4组,并编号。
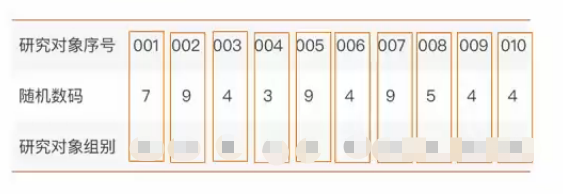
组内随机:一组四个,分为AB,有AABB, ABAB, ABBA,BAAB,BBAA,BABA 六种,别分编号1,2,3,4,5,6
选出一组随机数,留下1-6的数字,(925912--->>2512)
各区组内按照 组内随机的规则 分组。
#随机数的选择,EXCEL,R,随机数表,都可以。
分组隐匿
一般使用信封法,在医生给病人分组时,可能会将 条件相近的患者分到一个组中,采用信封法,医生在分组前一刻不清楚这个病人要被分到哪个组,也不会产生偏移了。如下图,一个红框代表一个信封,只有医生将信封分配给病人之后,才会拆封。
双盲
