题记
最近发现2个脚本,尝试一步步学习下,也推荐一下,脚本一来自墨雪飘香的edu漏洞集合脚本,方便查看目标学校什么漏洞多,这对edusrc的挖掘有一定帮助,通过一步步测试学会了一小部分正则的利用,以前是拿lxml取值,get到新姿势了。第二个脚本为备份文件的字典脚本,针对目标生成特定字典,也是我在微信公众号看到的。
脚本一:edu学校漏洞汇总脚本
代码
import requests
import re
low=0
mid=0
high=0
critical=0
name=''
percent=0.0
#定义漏洞类型和数量
bugsName=['SQL注入漏洞','文件上传漏洞','代码执行漏洞','命令执行漏洞','XSS漏洞','CSRF漏洞','SSRF漏洞','点击劫持漏洞','弱口令','敏感信息泄露','水平权限绕过','垂直权限绕过','其他漏洞']
bugsCount=[0,0,0,0,0,0,0,0,0,0,0,0,0]
#定义漏洞等级和数量
bugsLevel=['低危','中危','高危','严重']
id=input('请输入厂商ID:')
for i in range(1,999):#此处设置为999为了不用控制页数,使用try进行中断
userHomeUrl='https://src.sjtu.edu.cn/list/firm/'+id+'?page='+str(i)
backInfo=requests.get(userHomeUrl)
#print(backInfo.text) #backinfo为响应号,backInfo.text为返回的链接内容。
try:
#终止循环
break_str='?page='+str(i)
#if backInfo.text.find(break_str)==-1:
#print(backInfo.text.find(break_str))
#检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
if backInfo.text.find(break_str)==-1 and i!=1:#完成后修改,防止页数不足一页而跳出循环
print('第'+str(i)+'页,不存在,循环终止!')
break
#正则规则中保留尖括号为了提高准确率,防止匹配到用户昵称和用户签名
r_name=r'学校名称:.+?<' #输出学校名称:.+?< <h2>学校名称:温州大学</h2>
# 1、. 匹配任意1个字符(除了 )
# 2、+ 匹配前一个字符出现1次多次或则无限次,直到出现一次
# 3、? 匹配前一个字符出现1次或者0次,要么有1次,要么没有
r_total=r'漏洞总数:d+' #d 匹配数字,也就是0-9
r_valid=r'漏洞威胁值:d+'
r_low=r'>低危<'
r_mid=r'>中危<'
r_high=r'>高危<'
r_critical=r'>严重<'
if name=='':
#print(re.search(r_name,backInfo.text)) #学校名称:温州大学<
name=re.search(r_name,backInfo.text).group().replace('<','') #学校名称:温州大学<替换掉
#print(re.search(r_total, backInfo.text))
total = re.search(r_total, backInfo.text).group().replace('漏洞总数:', '')
# print(total)
rank = re.search(r_valid, backInfo.text).group().replace('漏洞威胁值:', '') # 此处采用偷懒式写法,偷懒但有效
# 计算各类型漏洞个数
# print(len(bugsName))
for ii in range(len(bugsName)):
# print(ii)
# print(re.findall(bugsName[ii], backInfo.text)) #爬出来每个漏洞的个数
bugsCount[ii] = len(re.findall(bugsName[ii], backInfo.text)) + bugsCount[ii]
# print(bugsCount[ii])
low_result = re.findall(r_low, backInfo.text) # 低危
mid_result = re.findall(r_mid, backInfo.text) # 中危
high_result = re.findall(r_high, backInfo.text) # 高危
critical_result = re.findall(r_critical, backInfo.text) # 严重
# 开始计算总通过率
# print(total)
if percent == 0.0:
percent = '%.4f' % (float(rank) / float(total))
# 计算完毕
# 计算各等级漏洞数
low = low + len(low_result)
mid = mid + len(mid_result)
high = high + len(high_result)
critical = critical + len(critical_result)
# 状态报告
print('第' + str(i) + '页,已处理!')
except:
print('出现异常,中断进程')
break
#打印空行
print(' ')
#bugsName[i]为各种漏洞名
for i in range(len(bugsName)):
print(bugsName[i]+':'+str(bugsCount[i]))
#打印空行
print('')
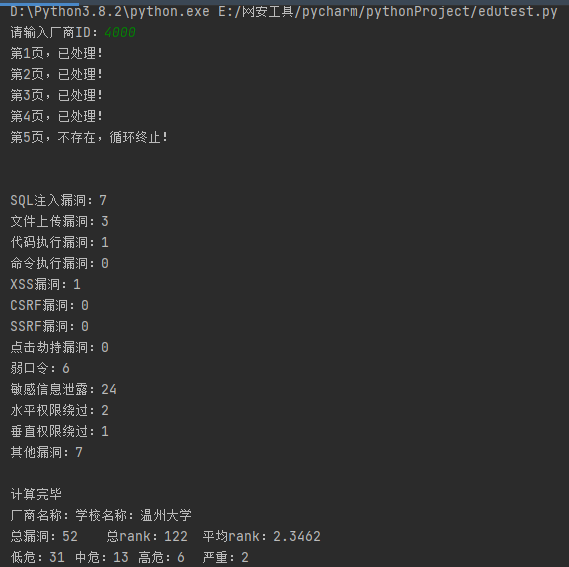
print('计算完毕 厂商名称:'+name+' 总漏洞:'+str(total)+' 总rank:'+str(rank)+' 平均rank:'+percent+' 低危:'+str(low)+' 中危:'+str(mid)+' 高危:'+str(high)+' 严重:'+str(critical))
执行截图
脚本二:敏感备份文件字典生成脚本
代码
import argparse
import time
#直接泄露除动态生成部分
def list1():
list1 = [".git/",".gitgnore",".DS_Store",".svn/entries","/WEB-INF/web.xml","/WEB-INF/classes/","/WEB-INF/lib/","/WEB-INF/src/","/WEB-INF/database.properties",".hg/","/CVS/",".bzr/",".bash_history",]
return list1
#所有文件名列表
def list21(target,targets,suffix,suffixs):
#文件名静态列表
list21 = ["beifen","备份","源码","www","wwwroot","web","wap","m","webroot","index","info","config","backup","back","bak","data","database","admin","1","2","3","123","456","789","新建 Text Document","新建 文本文档","New Text Document","tip","tips","根目录","网站",]
#将给定的后缀名和目标名参数赋给s和t列表
s = []
t = []
if(suffix is not None):
s.append(suffix)
if(suffixs is not None):
with open(suffixs) as lines:
for line in lines:
s.append(line.strip())
if(target is not None):
t.append(target)
if(targets is not None):
with open(targets) as lines:
for line in lines:
t.append(line.strip())
#往所有文件名列表里添加t列表元素和t.s组合的列表元素
if t:
for ti in t:
list21.append(ti)
if s:
for ti in t:
for si in s:
list21.append(ti+'.'+si)
return list21
#所有后缀名列表
def list22():
list22 = ["zip","rar","7z","tar.gz","gz","tar","bak","sql","txt","sh","mdb",]
return list22
#所有文件名+后缀名
def list2(filename,suffix):
list23 = []
for s in suffix:
for f in filename:
list23.append(f+'.'+s)
return list23
#直接泄露动态生成部分
def list3(filename):
list3 = []
for f in filename:
list3.append("."+f+".swp")
return list3
if __name__ == '__main__':
#参数提示
parser = argparse.ArgumentParser()
parser.description='源码泄露字典生成脚本'
parser.add_argument("-t","--target",help="目标名或目标域名,用于生成文件名list",default=None)
parser.add_argument("-ts","--targets",help="多个目标名或目标域名存放的文件",default=None)
parser.add_argument("-s","--suffix",help="目标的域名后缀",default=None)
parser.add_argument("-ss","--suffixs",help="多个目标的域名后缀存放的文件",default=None)
args = parser.parse_args()
#参数赋值
target = args.target
targets = args.targets
suffix = args.suffix
suffixs = args.suffixs
#确认参数
print("################################################")
if(target is not None):
print("指定的目标名或域名:"+target)
if(targets is not None):
print("指定的多个目标名或域名存放的文件:"+targets)
if(suffix is not None):
print("指定的目标域名后缀:"+suffix)
if(suffixs is not None):
print("指定的多个目标域名后缀存放的文件:"+suffixs)
print("################################################")
print("开始生成源码泄露字典")
#生成字典各部分列表
list1 = list1()
list21 = list21(target,targets,suffix,suffixs)
list22 = list22()
list2 = list2(list21,list22)
list3 = list3(list21)
#拼接列表并输出到文件
now = time.strftime("%Y%m%d%H%M%S",time.localtime())
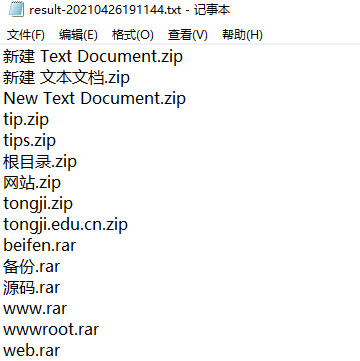
result = 'result-'+now+'.txt'
f = open(result,'w')
listall = list1 + list2 + list3
for i in listall:
f.write(i+' ')
f.close()
print("字典生成完毕!文件名:"+result)
运行截图
python bfzd.py -ts "yuming.txt" -ss "houzhui.txt"
python bfzd.py -t "tongji" -s "edu.cn"

正则学习地址
http://blog.csdn.net/weixin_40136018/article/details/81183504
http://blog.csdn.net/weixin_40136018/article/details/81193361