1.缺失索引:
USE AdventureWorks2014 SET STATISTICS TIME ON; SET STATISTICS IO ON ; SELECT per.FirstName,per.LastName,p.Name,p.ProductNumber,soh.OrderDate,sod.LineTotal,soh.TotalDue FROM sales.SalesOrderHeader AS soh INNER JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID=sod.SalesOrderID INNER JOIN Production.Product AS p ON sod.ProductID=p.ProductID INNER JOIN sales.Customer AS c ON soh.CustomerID=c.CustomerID INNER JOIN Person.Person AS per ON c.PersonID=per.BusinessEntityID WHERE sod.LineTotal>25000 SET STATISTICS IO OFF; SET STATISTICS TIME OFF;
得到下面的信息:
SQL Server 执行时间: CPU 时间 = 63 毫秒,占用时间 = 378 毫秒。 SQL Server 执行时间: CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
--创建一个索引
CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_LineTotal ON sales.SalesOrderDetail(LineTotal)
索引后结果如下:
SQL Server 执行时间: CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 SQL Server 执行时间: CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
2.统计信息过时
你明知道返回和处理的结果集都很小,而优化器却选择了hash连接,这是就可以检查一下图形化执行计划中是否有黄色叹号,或者用文本化执行计划看看预估和实际行数的差异是否很大。如果是使用UPDATE STATISTICS语句更新统计信息,同时检查为什么统计信息过时
3.非SARG查询
如果是一个谓词(特别是Where条件中)能用到索引查找操作,就可以理解为SARG,
如果在where 条件所用到的列中使用了标量函数(YEAR、UPPER)或使用like ‘%%’这类的查询,称为非SARG查询会导致索引无效
--非SARG(聚集索引扫描) SELECT soh.SalesOrderID,soh.OrderDate,soh.DueDate,soh.ShipDate,soh.Status,soh.SubTotal,soh.TaxAmt,soh.Freight,soh.TotalDue FROM sales.SalesOrderHeader AS soh INNER JOIN sales.SalesOrderDetail AS sod ON soh.SalesOrderID=sod.SalesOrderID WHERE CONVERT(DATE,sod.ModifiedDate)='07/01/2005'
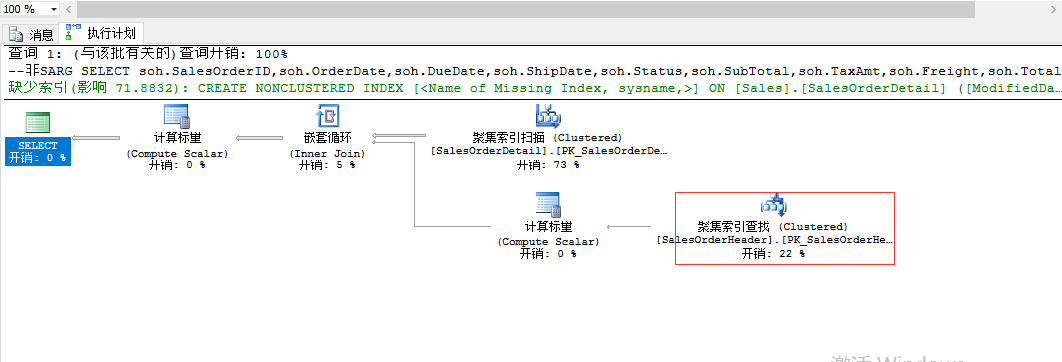
进行改写:(聚集索引查找)
SELECT soh.SalesOrderID,soh.OrderDate,soh.DueDate,soh.ShipDate,soh.Status,soh.SubTotal,soh.TaxAmt,soh.Freight,soh.TotalDue FROM sales.SalesOrderHeader AS soh INNER JOIN sales.SalesOrderDetail AS sod ON soh.SalesOrderID=sod.SalesOrderID WHERE sod.ModifiedDate>='2005-07-01 00:00:00.000' AND sod.ModifiedDate<'2005-07-02 00:00:00.000'
非SARG对where条件中的列使用UPPER/LTRIM/ISNULL之类的标量函数,对于这种情况,改写查询解决。
4.隐式转换
指一个查询From/Where子句中,用于关联和判断列之间数据类型不同,导致优化器需要根据数据类型的优先级高低进行类型转换然后在优化、执行。
SELECT p.FirstName,p.LastName,c.AccountNumber FROM Sales.Customer AS c INNER JOIN Person.Person AS p ON c.PersonID =p.BusinessEntityID WHERE c.AccountNumber=N'AW00029594'
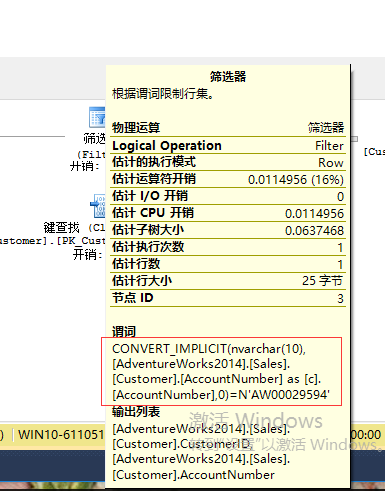
如上图加宽部分就是需要把varchar类型转换成nvarchar类型。可以考虑在传入where条件之前先进行显式数据类型转换。
5.参数嗅探
创建针对存储过程、函数或者参数化查询的执行计划时,根据传入的参数进行预估并生成执行计划的一个功能,参数嗅探出现在执行计划的编译或者重编译过程中。
CREATE PROCEDURE user_GetCustomerShipDates ( @ShipDateStart Datetime, @ShipDateEnd datetime ) AS SELECT CustomerID,SalesOrderNumber FROM Sales.SalesOrderHeader WHERE ShipDate BETWEEN @ShipDateStart AND @ShipDateEnd --创建非聚集索引 CREATE NONCLUSTERED INDEX IDX_ShipDate_ASC ON Sales.SalesOrderHeader(ShipDate) --清空缓存 DBCC FREEPROCCACHE EXEC user_GetCustomerShipDates '2005/07/08','2008/01/01' EXEC user_GetCustomerShipDates '2005/07/10','2008/07/20' --删除索引 drop index IDX_ShipDate_ASC on Sales.SalesOrderHeader
在ShipDate上有索引,还是进行了聚集索引扫描。
在第一个存储过程的参数中,查询条件的时间范围几乎包括了全表的所有时间,另外非聚集索引没有覆盖查询,因此使用了聚集索引扫描
第二个存储过程仍然会用上面的执行计划。
把存储过程的顺序调换一下:(执行计划)
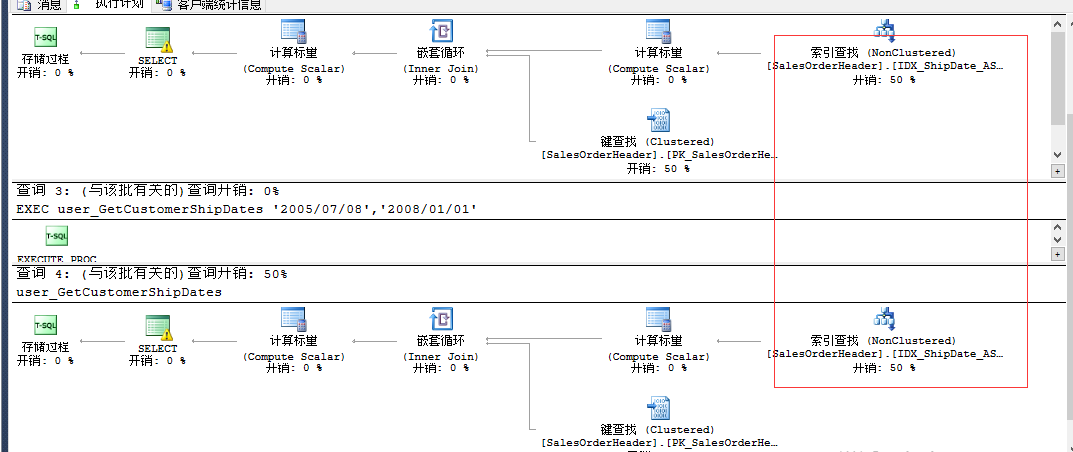
对于参数嗅探问题,可以使用部分编译、编译提示等功能来避免,更多的优化应该考虑数据和研究数据分布问题
6.--非参数化Ad—hoc查询
Ad-hoc称为即席查询,可以理解为没有使用存储过程、SP_Executesql或其他方式强制预定义SQL语句。
如:SELECT * FROM bt WHERE id=***这类查询引起的问题
可以把:高级--真对即席工作负荷进行优化:true
或者在数据库层面强制参数化:
ALTER DATABASE AdventureWorks2014 SET PARAMETERIZATION FORCED
7.非必要的并行查询
并行操作会把一个查询分开到多个线程中执行,然后在合并到一起返回结果
数据库事务:
事务是对数据库操作的单元,可以是一个Select语句,也可以是包好多个Select、Update、Delete、Insert的操作的命名集合
1.原子性:意味着一个事务内的所有操作必须全部完成或者全部回滚。
2.一致性:要求整个事务在运行的前后数据库的状态必须一致,不能打破数据定义中的一致性约束
3.隔离性:保证同一时间中,一个事务的运行不能被另一个事务影响。
4.持久性:事务一旦提交成功,将永久存储到服务器的文件系统中,即使系统在中途奔溃,所发生的的效果都不会丢失,这个会通过日志来保证。
显示事务隐式事务(区别在于创建和提交的方式)
隐式事务:由SQL Server自己去开启和提交/回滚,并且在内部保证ACID特性。
显示事务:以Begin Tran/Transaction开始以Commit Tran/Transaction 或者Rollback Tran结束