一、基础
1.为某张表添加一列
alter table table_name add column_name column_type;
2.查看表的结构
desc table_name;
3.修改表中的列的类型、长度
alter table table_name modify column_name column_type;
4.删除表中的列
alter table table_name drop column column_name;
5.to_date('日期',对应输入的格式);
eg: to_date('20200805','yyyymmdd');
6.查询空值:使用 is null
select * from student where sname is null;
7.创建和已存在的表 结构数据均相同的表
create table table_name as select * from student;
8.删除数据表中的所有数据 但保留表的结构
truncate table table2_name;--包含提交工作,不可回滚
delete from table_name; --需要commit 才能删除,可以回滚
9.为空表插入 数据同已存在的表(也可添加where 限制 添加符合条件的若干行数据插入)
insert into table_name1 select * from table_name2;
10.修改或添加的数据中 存在 单引号时 ,使用两个单引号 表示一个单引号
update student set sname =' A''B'; where sno = 4;
11.当列名的别名 存在空格时,为别名加上双引号
select sno " 学 号" from student
二、常用函数
initcap --将字符串的第一个字符改成大写 add_months(sysdate,1) --将日期进行增加 一个月 mouths_between(sysdate, to_date('20200805','yyyymmdd')) --计算两个时间相差的月数 select extract(year/month/day from sysdate) from dual; --提取出 时间的年份或月份或日期 last_day(sysdate) --取出时间中该月份的最后一天 nvl(emp1,emp2) --emp1为空 返回emp2 ,否则返回emp1 nvl(emp1,emp2,emp3) --emp1不为空 返回emp2,否则返回emp3
集合操作
使用集合操作符时,必须确保不同查询的列的个数、数据类型匹配
union --获取两个结果集的并集,自动去掉重复行,以第一列的结果进行排序 union all --与union的区别就是 包含重复行 minus -- 获取两个结果集的差集,只显示第一个集合中的存在的数据
intersect --获取两个结果集的交集
重命名
--重命名表:
rename table_name1 to table_name2; --重命名列
alter table table_name rename column col_oldname to col_newname;
sql语句的执行顺序
from--where --group by--having--select --order by
练习
1.student(sno,sname,sage)存在相同姓名的学生,找出姓名相同的记录,并显示出来
1 select * 2 from student 3 group by sname 4 having count(sno)>1;-- 报错:不是group by 表达式 5 -- select 列表项中不存在的列可以出现在group by的列表项中,
-- 在select列表项中出现的列必须全部出现在group by后面(聚合函数除外)
7 select * 8 from student 9 where sname in (select sname from student1 group by sname having (count(*)>1));
select case when 的使用
--语法 case when 条件1 then action1 when 条件2 then action2 ……… else actionN end case case 计算式 when value1 then action1 when value2 then action2 when value3 then action3 …… else actionN end case
练习:
学生成绩表score_table(sno,kc,score,grade) 根据学生成绩 插入对应的等级
--1.根据成绩显示出学生的等级 select sno, case when score>90 then '优秀' when score>80 then '优秀' when score>70 then '优秀' when score>60 then '优秀' else '不及格 ' end grade --grade 给查询的结果列的别名、 from score_table; --2. 再从1中的结果集a(sno,grade)中取出等级grade update score_table set grade =( select grade from (select sno, case when score>90 then '优秀' when score>80 then '优秀' when score>70 then '优秀' when score>60 then '优秀' else '不及格 ' end grade --grade 给查询的结果列的别名、 from score_table;) a where score_table.sno = a.sno );
表T1里有a、b、c…N个字段,表T2里有a、b、c三个字段,在T1表中c字段和T2表中的c字段相同的情况下,从表T2中将a、b覆盖表T1中的a、b
update T1 set a=(select a from T2 where T2.c =T1.c), b=(select b from T2 where T2.c =T1.c) where t1.c in (select c from T2);
分析函数:用于计算完成聚集的累计排名、序号等
分析函数为每组记录返回多个行
以下三个分析函数用于计算一个行在一组有序行中的排位、序号从1 开始
row_number 返回连续的排序,不论值是否相等
使用row_number 时 需要用over()说明对哪一列进行排序
rank 具有相等值的航排序相同,序数随后跳跃
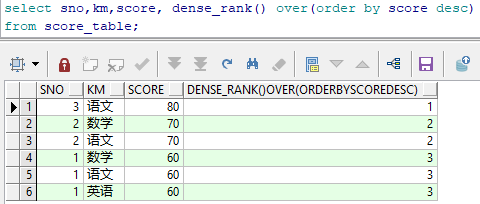
dense_rank 具有相等值的行排序相同,序号 是连续的
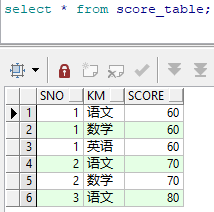
对成绩表进行排序---使用row_number()
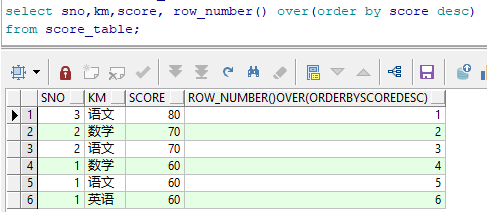
对成绩表进行排序-----使用rank()

对成绩表进行排序-----使用dense_rank()
decode 中的if-then-else逻辑
语法:decode(value, if1,then1,if2,then2,…else)
value 代表某个表的任何类型的任意列或一个通过计算所得的任何结果。每当value值被测试,如果value的值为if1,decode函数的结果是 then1,等等,如果value结果不等于给出的 任何配对时,decode结果就返回else
练习
1.已存在student(id,sname,sex)将学生表信息中的性别的表示方法从1/2 换成男/女
1 select id,name,decode(sex,1,'男','女') 2 from student;
rownum 伪列
作用:对查询结果,输出前若干条记录
只能与<、<=、between and 连用
between and 使用约束:必须从第一条开始
练习--已存在员工工资表yggz(bh,gz) 输出员工工资的前的5条记录 select * from yggz where rownum<=5;
select * from yggz where rownum between 1 and 5;
联合聚合函数 查询中间条目数的记录
--查询员工工资记录中的第3条到第5条记录 select * from yggz where rownum <=5; minus select * from yggz where rownum <3; 或 select * from (select yggz.* ,rownum rn from yggz) where rn <=5 and rn >=3;
删除记录中的重复记录
rowid 伪列
rowid里面的信息有:数据库对象号、数据文件号、数据块号 、行号
--若学生表student(sno,sname,sage)中存在重复记录 --思路1:删除学生学号不为唯一,并且rowid不是最小的 delete (from) student where sno in (select sno from student group by sno having (count(*)>1)) and rowid not in (select min(rowid) from studnet group by sno having (count(*)>1)); --思路2:使用自连接 delete from student where rowid in (select a.rowid from student a,student b where a.sno =b.sno and a.rowid >b.rowid); --思路3:嵌套查询 delete from student d where d.rowid >(selete min(rowid) from student x where d.sno = x.sno);
用户和权限
创建用户账户
create user username
identified by password --不能以数字开头
profile(概要文件)管理用户
当创建用户时候 没有指定profile,那么oracle把名字叫default的profile赋予给用户
指定test1 只能最多输入3次密码
--创建profile文件: create profile pro1 limit failed_login_attempts 3 password_lock_time 2;
--failed_login_attempts 用于指定联系登录的最大失败次数
--password_lock_time 用于指定账户被锁定的天数
权限
权限类型:系统权限、对象权限
系统权限允许用户执行某些数据库操作,如创建表
对象权限允许用户对数据库对象(如表、视图、序列等)执行特定的操作
授予用户权限,可以是系统权限或者对象权限
grant privilege to user [with admin option]-- 包含该句,只能是系统权限
三、完整性约束
维护数据的完整性:not null、unique、check、primary key、foreign key五种
unique :不可以重复,但是可以为空
primary key 不可以重复,且不能为空
一个表中只能有一个primary key 但却可以多个unique
锁:数据库用来控制共享资源并发访问的机制
使用锁的优点:保持数据的一致性、数据的完整性、并行性
锁的类型:行级锁、表级锁
四、表
表的分类:普通表、分区表 、索引组织表IOT、簇表、临时表、(嵌套表、对象表了解)等
相关概念:高水位线HWM、pctfree、pctused
1.高水位线HWM
把表想象成一个从左到右依次排开的数据块,高水位线就是包含数据块最右边的位置。最初的高水位线处于表的第一个快中,随着不断插入数据,使得hwd不断 升高,但当删除表中一些数据行(或者全部数据行),HWM不会下降(除非使用rebuild、truncated或shrunk操作)
2.pctfree
当用户执行insert操作,数据块应该保留多少 的free空间,pctfree=20 ,插入数据时,需要保留20%的空间,该保留空间的意义在于用于将来数据扩展的update操作。默认pctfree=10;
3.pctused
delete操作,如果数据块的使用率低于40%的话,那么让用户可以进行insert操作,pctused操作的含义,默认pctused=40
1.普通表
异动表move,从 一个表空间移到另个表空间,可以清除表里的碎片
alter table table_name move [tablespace users]; --move过程中,表上 不能有应用 --move之后,表上索引需要重新建立
--将数据行从一个数据块移动到另个数据块,分为2个阶段:收缩,降HWM,在收缩阶段,可以对表进行DML操作,在降低HWM阶段,不能对表进行DML操作 --收缩表shrink 前提:表所在的表空间使用了ASSM,表上启用了row movement alter table table_name sapce [cascade];
2.索引组织表IOT
①区别于普通表的无需组织方式,IOT表必须有主键,是有序的表,其中的数据按照主键进行存储和排序。
②使用普通组织表时,需要为表和表主键上的索引分别留出空间,而IOT不存在主键的空间开销,IOT的数据存储在与其关联的索引中,索引就是数据,数据就是索引;
③IOT表的数据存放在索引块中,通过主键访问表时,只需要读取一个块即可,而如果通过主键索引普通表,至少需要读取两个块,一个索引块,一个是数据块
④对经常通过主键访问数据的表来说,适合使用IOT表。
--创建IOT表的语句:在普通表的创建后添加:organization index --建立学生表的IOT表 create table iot_student( sno int, sname varchar2(100), sage int, constraint pk_studnet primary key(sno) ) organization index; [pctthreshold 30 overflow tablespace users]
--pctthreshold是指定一个数据块的百分比,当行数据占用大小超出时,该行的其他列数据放入溢出段,即overflow指定的存储空间去, --pctthreshold是保留在索引块里的数据量占整个索引块的大小百分比,默认50%
3.簇表
两个相互关联的表的数据列,同时放到一个簇数据块中,当以后进行关联读取时,只需要扫描一个数据块就可以了,极大的提高了效率
分为索引簇表和哈希簇表
创建簇表的步骤:
1.建立簇段 cluster segment
2.基于簇,创建两个相关表,每个表都关联到cluster segment上
3.为簇创建索引
--创建簇 create cluster cluster(code_key number); --创建表 create table student( sno1 number, sname varchar2(10) )cluster cluster1(sno1); create table address( sno2 number, zz varchar2(10) )cluster cluster1(sno2); --在簇上建立索引 create index index1 on cluster cluster1;
--查看簇的所有信息
select * from user_clusters;
五、表分区
允许用户将一个表分成多个分区;用户可以执行查询,只访问表中的特定分区;将不同的分区存储在不同的磁盘,提高访问性能和安全;可以独立地备份和恢复每个分区 。
分区方法:范围分区、散列分区、列表分区、复合分区
1.范围分区:以表中的一个列或一组列的值的范围分区
范围分区的语法
partition by range(column_name) ( partition part1 values less than(range1), partition part2 values less than(range2), … partition partN values less than(maxvalue) );
--根据范围分区建表 create table sales( produce_id varchar2(5), sales_count number(10,2) ) partition by range(sale_count) ( partition p1 value less than(1000), --值小于1000的数据放在p1块中 partition p2 value less than(2000), partition p3 value less than(3000) ); --查询分区表中某个特定分区的信息 select * from sales patition(p1); --当范围分区中,分区不合理,添加一个最大分区 alter table sales add partition p4 values less than(maxvalue);
2.散列分区
允许用户对不具有逻辑范围的数据进行分区;通过在分区键上执行hash函数决定存储的分区;将数据平均地分不到不同的分区
partition by hash(column_name) partitions number_of_partitions; 或 partition by hash(column_name) ( partition part1[tablespace tb1], partition part2[tablespace tb2], …… partition partN[tablespace tbN], ) -- create table my_emp( empno number, ename varchar2(10) ) partition by hash(empno) ( partition p1, partition p2 );
3.列表分区
允许用户将不相关的数据组织在一起
创建列表分区语法:
partition by list(column_name) ( partition part1 values(value_list1), partition part2 values(value_list2), …… partition partN values(DEFAULT) ); -- create table personCity( id number, name varchar2(10), city varchar2(10) ) partition by list(city) ( partition 东边 values('开封'), partition 西边 values('洛阳'), partition 南边 values('许昌'), partition 北边 values('新乡') );
4.复合分区
范围分区与散列分区或列表分区的组合
复合分区的语法:
partition by range(column_name1) subpartition by hash(column_name2) subpartition number_of_partitions --子分区的个数 ( partition part1 values less than(range1), partition part2 values less than(range2), …… partition partN values less than(rangeN) ); -- create table student( sno number, sname varchar2(10) ) partition by range(sno) subpartition by hash0(sname) subpartition 4 ( partition p1 values less than(1000), partition p2 values less than(2000), partition p3 values less than(maxvalue), );
5.引用分区
引用分区:基于由外键引用的浮标的分区的方法,它依赖已有的父表子表的关系,子表通过外键关联到父表,进而继承了父表的分区方式而不需要自己创建,子表还继承了父表的维护操作。
①主表是范围分区,子表是引用分区
②主表是列表分区,子表是引用分区
③主表是散列分区,子表是引用分区
create table student( stu_id number primary key, stu_name varchar2(10), grade varchar2(10) ) partition by range(stu_id) ( partition par_stu1 values less than(1000), partition par_stu2 values less than(2000), partition par_stu3 values less than(maxvalue) ); create table score( id number primary key, stu_id number not null, couse_name varchar2(20), score number, constraint fk_score foreign key(stu_id) references studnet(stu_id) ) partition by reference(fk_score);
6.间隔分区
可以完全自动地根据间隔阀值创建范围分区,它是范围分区的扩展。
create table sale_detail( sale_detail_id number, product_id number, quantity numbers, sale_date date ) partition by range(sale_date) interval (numtoyminterval('1',MONTH))--每隔一个月添加一个分区 ( partition p_201006 values less than(to date('20100601','yyyymmdd'))--设置初始分区 )
7.基于虚拟列的分区
把分区建立在某个虚拟列上,即建立在函数或表达式的计算结果上,来完成某种任务。