模块:py文件
包:目录,目录里面包含__init__.py,内容可以是空
里面可以包含多个模块文件,还可以包含子包
1、模块和包,可以很方便的提供给其他程序以复用
1) 利于组织复杂工程
我们写代码的时候,实际上可以把所有的代码都包含在一个文件里面。
需要把一个很大的文件,拆分为不同的模块或者包,以此来实现代码的可维护性
2) 有利于实现分工
在构建工程的时候,还可以基于模块和包进行开发人员的任务分配工作。
2、模块是个文件,包是个目录
b.py实际上是一个python文件,它是一个模块,模块给其他程序文件提供公用的变量、函数和类
a.py实际上是主程序,引用b模块(b.py)来做一些事情
包的组成:__init__.py+模块
一个包中可以包含多个模块文件,还可以包含子包
3、a.py与b.py在同一个目录下
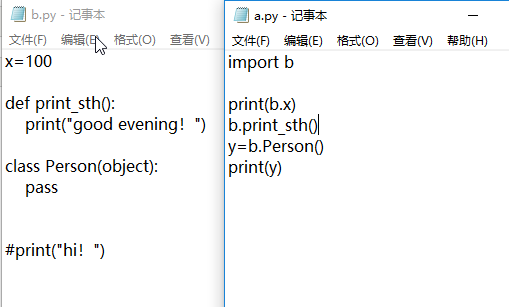
1)新建一个模块b.py
x=100 #变量
def print_sth(): #函数
print("good evening!")
class Person(object): #类
pass
变量、函数、类是模块和包通常包含的这三种数据。
2)主程序a.py调用模块b.py
import b #a.py中引入模块b
print(b.x) #打印模块b中的变量x的值
b.print_sth() #调用模块b中的函数print_sth()
y=b.Person() #将模块b中的类做了一下实例化
print(y) #打印了一下
执行结果:
D:study>py -3 a.py
100
good evening!
<b.Person object at 0x000001EE2EA0D5F8>
4、主程序会打印模块b中的内容
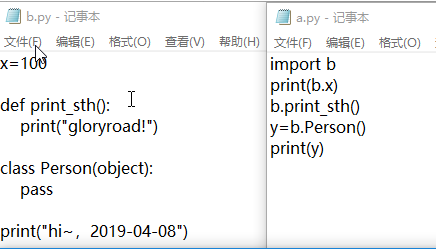
模块b.py中,除了变量,函数,类外,还有一个print语句(print("hi~,2019-04-08") )
主程序a.py调用模块b
运行结果:
D:study>py -3 a.py
hi~,2019-04-08 #下面均是a.py程序的输出内容,但最上面多了一个输出,
100 #我只是改了一下b.py,并且a中也没有调用b.py中的
gloryroad! #print语句的代码,但是也被执行了,为什么?
<b.Person object at 0x0000027C22D2D5F8>
原因:a.py在调用b.py时(import b),b.py中的代码均在编译器中执行了一遍。至于为何只打印了print("hi~,2019-04-08"),原因在于b.py中的其他内容均是定义,看不到任何的执行效果。
5、主程序不打印模块b中的执行结果
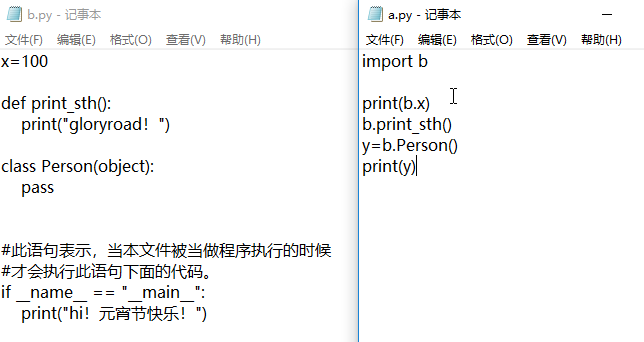
#此语句表示,当本文件被当做程序执行的时候,才会执行此语句下面的代码。
#如果本文件被其他文件import,那么if代码块则不会被执行
if __name__ == "__main__":
print("hi!元宵节快乐!")
主程序a.py调用模块b,不会打印模块b中的 hi!元宵节快乐! 内容
原因:有if __name__==”__main__”:
6、单独运行模块b.py,会打印b的执行结果
x=100
def print_sth():
print("gloryroad!")
class Person(object):
pass
if __name__=="__main__":
print("hi~,2019-04-08")
运行b.py的结果:
D:study>py -3 b.py
hi~,2019-04-08 #会打印if下面的语句,因为该文件被当做程序执行了
7、from方法import模块
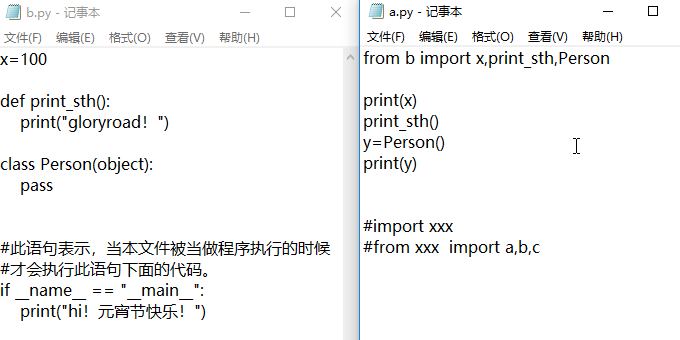
主程序a.py调用,模块b.py
from b import x,print_sth,Person #主程序不再使用import b
print(x) #b.py中的x也就不用再写做b.x
print_sth() #b.py中的函数也不用再写做b.print_sth()
y=Person() #b.py中的类也不用写做b.Person()
print(y)
#import xxx
#from xxx import a,b,c
执行结果:
D:study>py -3 a.py
100
gloryroad!
<b.Person object at 0x0000028721C1D5F8>
#模块的引入,有2种形式:
#import b
#from b import x,print_sth,Person
8、
1) 模块b.py
x=100
def print_sth():
print("gloryroad!")
class Person(object):
pass
xx=1000 #b.py有一个变量xx
2)主程序a.py
from b import x,print_sth,Person #引入模块b中的变量时,没有引入xx
print(x)
print(xx) #主程序中有要求打印xx
运行结果:
E:>python a.py #执行主程序a.py,提示xx未定义
100
Traceback (most recent call last):
File "a.py", line 3, in <module>
print(xx)
NameError: name 'xx' is not defined
解决方法:
(1)主程序a.py引入模块b中的变量时,写全要用的变量
from b import x,print_sth,Person,xx #参数列举全
print(xx)
(2)主程序a.py直接引入所有的模块b中的变量
from b import * #引入模块中所有的参数
print(xx)
(3)
#import b
#print(b.xx)
9、
1) 模块b.py
x=100
def print_sth():
print("gloryroad!")
class Person(object):
pass
xx=1000 #模块b中有定义xx
2) 主程序a.py
from b import * #引入模块b中所有的参数,包括xx
xx=123 #主程序中也定义了一个xx
print(x)
print(xx) #打印xx
运行结果:
E:>python a.py
100
123 #打印的xx是主程序中的xx的值
问:如何同时打印a.py中的xx值和b.py中的xx值?
解决方法:加b.
主程序代码示例:
from b import *
xx=123
print(x)
print(xx)
print(b.xx) #尝试使用(b.xx)输出b中的xx值
运行结果:
E:>python a.py
100
123 #主程序a.py中的xx成功打印
Traceback (most recent call last):
File "a.py", line 5, in <module>
print(b.xx)
NameError: name 'b' is not defined #提示b未定义
综上,即使使用了from b import *,也不可直接使用b.xx等
正确代码:
from b import *
import b #主程序还需多引入一下import b
xx=123
print(x)
print(xx)
print(b.xx)
运行结果:
E:>python a.py
100
123
1000
10、命名空间:
a.py命名空间:
xx
b.py的命名空间:
x
print_sth
Person
1) import b
把b的命名空间引入到了a.py文件中
可以使用b.xxx方式,在a.py中使用b.py中的内容
b.x
b.print_sth
b.Person
优点:
a和b的命名空间的内容不会冲突
因为b.xxxx肯定不会和a文件中的变量、函数和类的命名相冲突
2) from b import *
把b的命名空间引入到了a.py文件中,并且使用的时候无需加上b.
x
print_sth
Person
优点:
省去写b.
缺点:
容易产生冲突
例如:
b.py包含xx
a.py也包含xx
则此时a.py中print(xx),会使用a.py中的xx值。
11、新建一个文件夹packagea,packagea就是包
下面最好包含这个文件:__init__.py
然后再建立一个c.py文件,作为模块
以上就完成了一个包的构建(__init__.py+模块)
包和主程序在同一目录:
其中,包中的模块c.py文件的内容是:
yy=100
def p():
print("gloryroad!")
class P(object):
pass
主程序a.py:
import packagea.c #注意,要引入的是packagea.c.而不是packagea
print(packagea.c.yy) #与模块类似,区别在于,每一个c.前都要加packagea
packagea.c.p() #与模块类似,区别在于,每一个c.前都要加packagea
g=packagea.c.P() #与模块类似,区别在于,每一个c.前都要加packagea
print(g)
综上,主程序调用时,格式是包名.模块名.(变量、函数、类)名
12、
1) 包packagea中的模块c.py的代码是:
yy=100
def p():
print("gloryroad!")
class P(object):
pass
2) 主程序a.py的代码是:
from packagea.c import * #与引入模块的区别就在于packagea.c,多了一个
print(yy) # packagea包名而已
p()
g=P()
print(g)
运行结果:
E:>python a.py
100
gloryroad!
<packagea.c.P object at 0x0000024DD98597F0>
13、子包
E:packageasubpackaged.py模块中的内容是:
mm=456
主程序a.py的内容是:
import packagea.subpackage.d #引入包下面的子包下面的模块
print(mm) #打印d中的变量
运行结果:
E:>python a.py
Traceback (most recent call last):
File "a.py", line 2, in <module>
print(mm)
NameError: name 'mm' is not defined #提示:d中的变量未定义
错误原因:不能直接写print(mm),因为引入方式是import,所以要写全
1)更改后的主程序a.py:
import packagea.subpackage.d
print(packagea.subpackage.d.mm)
运行结果:
E:>python a.py
456
2)更改后的主程序a.py:
from packagea.subpackage.d import *
print(mm) #此种方法可以直接打印mm的值,前提是主程序
运行结果: #中无mm,否则容易相冲突
E:>python a.py
456
14、主程序与模块或包不在同一级目录
运行主程序a.py会报错
E:QQmessage>py -3 a.py
Traceback (most recent call last):
File "a.py", line 1, in <module>
from packagea.subpackage.d import *
ModuleNotFoundError: No module named 'packagea'
1) 模块和包放在sys.path的路径中(即 PYTHONPATH )
>>> import sys
>>> print(sys.path) #python path
['', 'D:\Python36\python36.zip', 'D:\Python36\DLLs', 'D:\Python36\lib', 'D:\Python36', 'D:\Python36\lib\site-packages']
以上列表中的路径意义:只要模块或包在以上列表中包含的路径的任意一个,就可正常执行主程序。
实践:
将packagea该包转移到D:\Python36中
运行主程序a.py
执行结果:
E:>python a.py
456 #虽然主程序与包和模块不在同一目录,但是也可正常执行
2) 通过电脑的设置:
在环境变量中将常使用的路径添加到PYTHONPATH中,重启cmd窗口后即可。
我的电脑-右键-属性-高级系统设置-环境变量-将D:;E:添加到PYTHONPATH中(没有PYTHONPATH的话新建一个),重启cmd后,将包和模块名移到D:或E:的根目录,运行主程序
运行结果:
E:>python a.py #可正常执行主程序
456
3) 只是程序运行时有效的添加方法
主程序a.py的运行代码:
import sys #先引入sys包
sys.path.append("E:\2019-03-02") #将模块或包的路径添加到pyhonpath中
from packagea.subpackage.d import * #在引入包
print(mm)
运行结果:
E:>python a.py #便可正常运行
456
注意:import sys与sys.path.append要在引入模块或包之前
#方法2:
#import sys
#print(sys.path)
#sys.path.append(包的绝对路径或者模块的绝对路径)
#方法3:
#通过我的电脑的设置,把将包或者模块的路径加到pythonpath变量下,需要重启cmd
#方法4:
将包或者模块直接放到pythonpath列表中的某一路径,如:C:Python36Libsite-packages目录下即可