三、顺序博弈
- 马尔可夫博弈中的强化学习
- 值迭代
在多智能体Q学习方法中,智能体不是简单地学习估计每个状态动作对的Q(s,a),而是给出采取联合动作 状态s中的动作α= a1,...,an来估计Q(s,a)。智能体对其在州s中采取行动时将获得的未来奖励没有一个单一的估计。在学习过程中,agent选择一个动作,然后需要观察其他agent所采取的动作,以更新相应的Q(s,a)值。
问题:智能体不能预测下一个状态下采取行动的值,因为这个值也依赖于其他智能体的行动。
解决问题的方式:
(1)利用对手建模
如果智能体能够估计其他代理所使用的策略,它就可以利用这一信息来确定不同联合行动的期望概率。基于这些概率,智能体可以确定状态的期望值。如:联合行动学习者(JAL)算法。
联合行动学习者会保留系统中其他智能体的状态、行动对 的次数,这个信息可以用来确定其他智能体可能的联合行动的经验概率:
的次数,这个信息可以用来确定其他智能体可能的联合行动的经验概率:

算法流程:

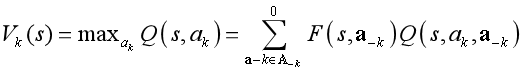
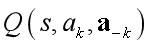 代表在状态s下采取ak,而其他智能体采取
代表在状态s下采取ak,而其他智能体采取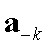 的Q值,这些期望的q值可以用于agent的动作选择,以及Q-learning的更新,就像在标准的单智能体的Q-learning算法中一样。
的Q值,这些期望的q值可以用于agent的动作选择,以及Q-learning的更新,就像在标准的单智能体的Q-learning算法中一样。
(2)假设其他智能体将根据某种策略进行博弈
例如:在minimax Q-learning算法(Littman, 1994)中,该算法是针对二主体零和问题而开发的,学习主体假设其对手将采取使学习者收益最小化的行动。这意味着单agent Q-learning的max算子被minimax值代替:
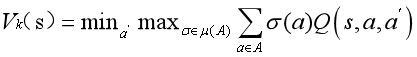
(3)假设行动者将采取均衡策略
例如:Nash-Q (Hu and Wellman, 2003)观察了所有智能体的回报,并保持了q值的估计,不仅是学习智能体,而且是所有其他智能体。这允许学习者将每个状态下的联合行动选择表示为一个博弈,其中支付矩阵中的条目由联合行动的agent的q值定义。
Nash- q行动者假设所有行动者在每个状态下都将按照这个阶段博弈的纳什均衡进行博弈:

- 策略迭代
互联学习自动机的马尔可夫对策:主要思想很简单:每个agent k在每个系统状态s中放置一个学习自动机LA (k,i)。在每个时间步骤中,只有当前状态的自动机是活动的。然后,每个自动机分别为其相应的智能体选择一个操作。由此产生的联合行动会触发下一个状态转换和即时奖励。自动机的更新不是使用即时奖励,而是使用估计平均奖励的响应。详细算法步骤如下:

算法分析:
(1)对所有智能体进行循环,如果状态s被人访问过,计算接受的奖励和上次访问状态s到现在的时间。更新上次访问s时所采取的行动预估。然后计算反馈。然后通过算出的反馈值和联合动作以及学习自动机上一步的状态来进行更新。更新后选择一个动作a。
(2)循环结束后把现在的数据进行储存,记录时间、奖励、还有动作。
(3)执行联合动作,观测即时奖励和新的状态,更新状态和奖励函数。时间自增。