1、来自外部文件json
val data=spark.read.json("hdfs://cslcdip/home/dip/lzm/sparkdata/people.json") println(data.schema) data.show()
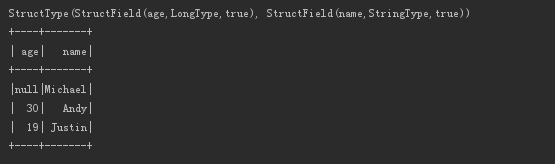
2、来自json格式的RDD
val nameRDD = spark.sparkContext.makeRDD(Array( "{"name":"zhangsan","age":18}", "{"name":"lisi","age":19}", "{"name":"wangwu","age":20}" )) val nameDF=spark.read.json(nameRDD) println(nameDF.schema) nameDF.show()

3、来自parquet文件
spark.sparkContext.setLogLevel("error") val data=spark.read.parquet("hdfs://cslcdip/home/dip/lzm/sparkdata/users.parquet") println(data.schema) data.show()

4、 from mysql pom配置jdbc
spark.sparkContext.setLogLevel("error") val data=spark.read.format("jdbc").option("url","jdbc:mysql://172.16.10.20:3306/hue") .option("driver","com.mysql.jdbc.Driver") .option("user","hue") .option("password","hue") .option("dbtable", "auth_user").load() data.printSchema() data.show()
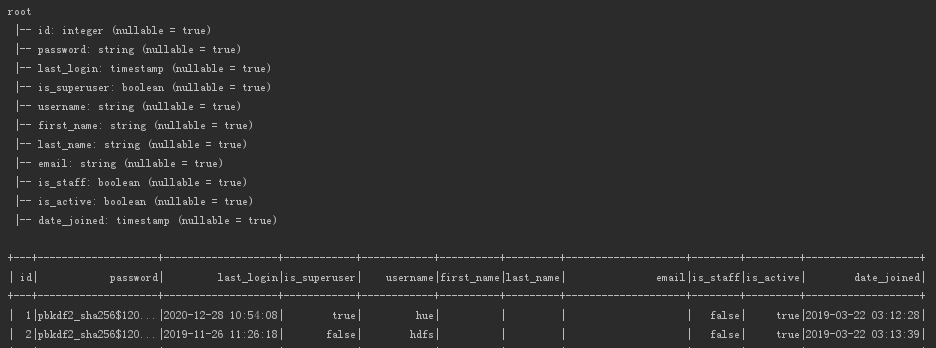
5、from hive pom配置spark-hive (默认是provide要注释),制定连接账户名


package com.cslc import org.apache.hadoop.conf.Configuration import org.apache.hadoop.fs.Path import scala.collection.JavaConversions._ import org.apache.spark.rdd.RDD import org.apache.spark.sql.SparkSession object Day01 { def main(args: Array[String]): Unit = { val sparkBuilder=SparkSession.builder val conf =new Configuration() val c=new Path("F:\IdeaWorkspace\lzm\Resource\core-site.xml") val hd=new Path("F:\IdeaWorkspace\lzm\Resource\hdfs-site.xml") val hi=new Path("F:\IdeaWorkspace\lzm\Resource\hive-site.xml") val y=new Path("F:\IdeaWorkspace\lzm\Resource\yarn-site.xml") val m=new Path("F:\IdeaWorkspace\lzm\Resource\mapred-site.xml") conf.addResource(hd) conf.addResource(c) conf.addResource(hi) conf.addResource(m) conf.addResource(y) for(c<-conf.iterator()){ sparkBuilder.config(c.getKey,c.getValue) } System.setProperty("user.name", "dip") val spark:SparkSession=sparkBuilder.master("local[2]").enableHiveSupport().getOrCreate() spark.sql("show databases").show() spark.stop() } }
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.25</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.3.0</version>
<!--<scope>provided</scope>-->
</dependency>
</dependencies>
