mapPartitionWithindex transformation算子,每次输入是一个分区的数据,并且传入数据的分区号
spark.sparkContext.setLogLevel("error")
val kzc=spark.sparkContext.parallelize(List(("hive",8),("apache",8),("hive",30),("hadoop",18)),2)
val bd=spark.sparkContext.parallelize(List(("hive",8),("test",2),("spark",20)),1)
val result=bd.union(kzc)
def fun(x:Int,y:Iterator[(String,Int)]):Iterator[(Int,String,Int)]={
val l=new scala.collection.mutable.ListBuffer[(Int,String,Int)]()
while (y.hasNext){
var tmpy=y.next()
l.append((x,tmpy._1,tmpy._2))
}
l.iterator
}
val result2=result.mapPartitionsWithIndex(fun)
result2.collect().foreach(println(_))

repartition transformation算子,从新定义分区,(多个分区分到一个分区不会产生shuffle)
spark.sparkContext.setLogLevel("error") val kzc=spark.sparkContext.parallelize(List(("hive",8),("apache",8),("hive",30),("hadoop",18)),2) val bd=spark.sparkContext.parallelize(List(("hive",8),("test",2),("spark",20)),1) val result=bd.union(kzc).repartition(4) def fun(x:Int,y:Iterator[(String,Int)]):Iterator[(Int,String,Int)]={ val l=new scala.collection.mutable.ListBuffer[(Int,String,Int)]() while (y.hasNext){ var tmpy=y.next() l.append((x,tmpy._1,tmpy._2)) } l.iterator } val result2=result.mapPartitionsWithIndex(fun) result2.collect().foreach(println(_))
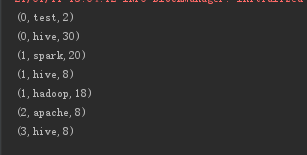
coalesce常用来减少分区,第二个参数是减少分区的过程中是否产生shuffle。true为产生shuffle,false不产生shuffle。默认是false。如果coalesce设置的分区数比原来的RDD的分区数还多的话,第二个参数设置为false不会起作用,如果设置成true,效果和repartition一样。
spark.sparkContext.setLogLevel("error") val kzc=spark.sparkContext.parallelize(List(("hive",8),("apache",8),("hive",30),("hadoop",18)),2) val bd=spark.sparkContext.parallelize(List(("hive",8),("test",2),("spark",20)),1) val result=bd.union(kzc).coalesce(2,true) def fun(x:Int,y:Iterator[(String,Int)]):Iterator[(Int,String,Int)]={ val l=new scala.collection.mutable.ListBuffer[(Int,String,Int)]() while (y.hasNext){ var tmpy=y.next() l.append((x,tmpy._1,tmpy._2)) } l.iterator } val result2=result.mapPartitionsWithIndex(fun) result2.collect().foreach(println(_))
