1.句子如下:
s1 = "周杰伦是一个歌手,也是一个叉叉" s2 = "周杰伦不是一个叉叉,但是是一个歌手"
2.分词:
import jieba s1_list = [x for x in jieba.cut(s1,cut_all=True) if x != ''] s2_list = [x for x in jieba.cut(s2,cut_all=True) if x != ''] print (s1_list) print (s2_list)
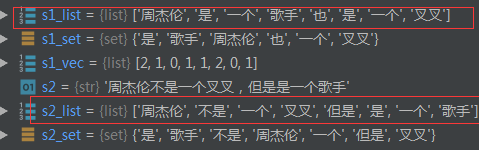
2.词频向量化:
import jieba s1 = "周杰伦是一个歌手,也是一个叉叉" s2 = "周杰伦不是一个叉叉,但是是一个歌手" s1_list = [x for x in jieba.cut(s1,cut_all=True) if x != ''] s2_list = [x for x in jieba.cut(s2,cut_all=True) if x != ''] s1_set = set(s1_list) s2_set = set (s2_list) word_dict=dict() i=0 for word in s1_set.union(s2_set): word_dict [word] = i i+=1
#词频向量化函数,输入一个总字典和待向量化列表 def word_to_vec(word_dict,lists): word_count=dict() result=[0]*len(word_dict) for word in lists: if word_count.get(word,-1) == -1: word_count[word]=1 else: word_count[word]+=1 for word,freq in word_count.items(): wid = word_dict[word] result[wid]=freq return result s1_vec=(word_dict,s1_list) s2_vec=(word_dict,s2_list) print (s1_vec) print (s2_vec)
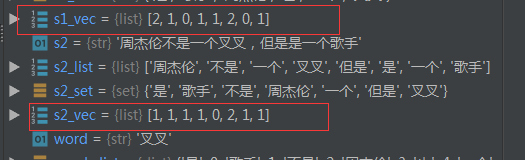
4.计算2个向量的相似度:
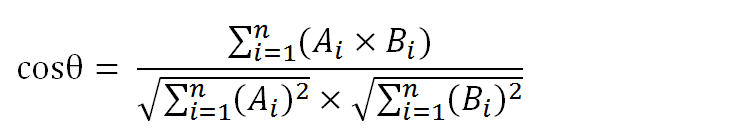
import jieba import math s1 = "周杰伦是一个歌手,也是一个叉叉" s2 = "周杰伦不是一个叉叉,但是是一个歌手" s1_list = [x for x in jieba.cut(s1,cut_all=True) if x != ''] s2_list = [x for x in jieba.cut(s2,cut_all=True) if x != ''] s1_set = set(s1_list) s2_set = set (s2_list) word_dict=dict() i=0 for word in s1_set.union(s2_set): word_dict [word] = i i+=1
#词频向量化函数 def word_to_vec(word_dict,lists): word_count=dict() result=[0]*len(word_dict) for word in lists: if word_count.get(word,-1) == -1: word_count[word]=1 else: word_count[word]+=1 for word,freq in word_count.items(): wid = word_dict[word] result[wid]=freq return result
#计算2个向量的余弦相似度 def cos_dist(a, b): if len(a) != len(b): return None part_up = 0.0 a_sq = 0.0 b_sq = 0.0 for a1, b1 in zip(a,b): part_up += a1*b1 a_sq += a1**2 b_sq += b1**2 part_down = math.sqrt(a_sq*b_sq) if part_down == 0.0: return None else: return part_up / part_down s1_vec = word_to_vec(word_dict,s1_list) s2_vec = word_to_vec(word_dict,s2_list) num=cos_dist(s1_vec,s2_vec) print (num)