一:STUN协议介绍
(一)STUN协议简介

STUN 存在的目的就是进行NAT穿越,NAT有四种类型,每种类型如何穿越,它的基本原理是什么,都是属于STUN协议中的一部分。
(二)RFC STUN规范
RFC STUN规范中,实际上有两套STUN规范:
规范一:RFC3489

STUN的全称是Simple Traversal of User Datagram Protocol (UDP) Through Network Address Translators (NATs),即穿越NAT的简单UDP传输,
是一个轻量级的协议,允许应用程序发现自己和公网之间的中间件类型,同时也能允许应用程序发现自己被NAT分配的公网IP。
它就是将STUN定义成简单的通过UDP进行NAT穿越的一套规范,也就是告诉你如何一步一步通过UDP进行穿越,但是这套规范在穿越的过程中还是存在很多问题,尤其是现在的网络
路由器对UDP的限制比较多,有的路由器甚至不允许进行UDP传输,所以这就导致了我们通过RFC3489这套规范进行NAT穿越的时候它的失败率会非常高。所以为了解决这个问题,
又定义了另一套标准,RFC5389.
规范二:RFC5389

1.RFC5389中,STUN的全称为Session Traversal Utilities for NAT,即NAT环境下的会话传输工具,是一种处理NAT传输的协议,但主要作为一个工具来服务于其他协议。
和STUN/RFC3489类似,可以被终端用来发现其公网IP和端口,同时可以检测端点间的连接性,也可以作为一种保活(keep-alive)协议来维持NAT的绑定。
和RFC3489最大的不同点在于,STUN本身不再是一个完整的NAT传输解决方案,而是在NAT传输环境中作为一个辅助的解决方法,同时也增加了TCP的支持。
RFC5389废弃了RFC3489,因此后者通常称为classic STUN,但依旧是后向兼容的。而完整的NAT传输解决方案则使用STUN的工具性质,ICE就是一个基于offer/answer方法的完整NAT传输方案,如SIP。
2.RFC5389是在RFC3489的基础上又增加了一些功能,但是它对整个STUN的描述就不一样了, 它是把STUN描述成一系列穿越NAT的工具,所以都叫STUN,但是他们的含义完全就不一
样了。RFC5389在UDP尝试可能失败的情况下,尝试使用TCP,也就是说RFC5389是包括UDP和TCP的两种协议进行NAT穿越的,这是两套规范最本质的区别。当然在协议的具体内
容上,包括协议头还有协议体中的属性都有很多的变化,但是那些都不是最关键的,最关键的是RFC5389里面将TCP纳入进来。你可以通过TCP进行穿越。
这是STUN 的RFC的两套规范。大家一定要清楚,尤其是查文档的 时候一定要清楚查询的是哪一套规范。
二:STUN协议详解
STUN是一个C/S架构的协议,支持两种传输类型:
一种是请求/响应(request/respond)类型,由客户端给服务器发送请求,并等待服务器返回响应;
另一种是指示类型(indication transaction),由服务器或者客户端发送指示,另一方不产生响应。
两种类型的传输都包含一个96位的随机数作为事务ID(transaction ID),
对于请求/响应类型,事务ID允许客户端将响应和产生响应的请求连接起来;
对于指示类型,事务ID通常作为debugging aid使用。
所有的STUN报文信息都含有一个固定头部(类型+长度+事务ID,3个字段),包含了方法,类和事务ID。
方法表示是具体哪一种传输类型---由type字段剩下的12位决定(两种传输类型<RFC3489中有两种>又分了很多具体类型),STUN/RFC5389中只定义了一个方法,即binding(绑定),其他的方法可以由使用者自行拓展;
Binding方法可以用于请求/响应类型和指示类型,用于前者时可以用来确定一个NAT给客户端分配的具体绑定,用于后者时可以保持绑定的激活状态。类表示报文类型是请求/成功响应/错误响应/指示---由(C0C1)决定。
在固定头部之后是零个或者多个属性(attribute),长度也是不固定的。
下面我们就具体看看这个STUN协议:

STUN这个协议它是包括了消息头和消息体,消息头是20字节固定的消息头,Body中可以有0个或者多个Attribute属性,后面我们会介绍属性的作用。
(一)消息头(固定20字节)

第三个是事物ID,它是16字节或128bit组成,它的作用就是请求和响应事物是相同的ID,用于请求与响应的匹配的:
比如我客户端发送了好几个请求,那服务端对于每一个请求都要返回一个响应 ,那怎么知道某个响应是对应到的请求呢,就通过这个事物ID。如果它事物ID号相同,说明这两是匹配的,整个逻辑就知道怎么做了,否则的话就很难判断。
所以它有三部分组成,第一是两个字节的类型,第二是两个类型的消息长度,不包括这个消息头,第三个是16字节的128位的事物ID,请求与响应的匹配。这个是消息头。
消息头的格式:

上图的格式是最新的RFC5389的格式,刚刚我们上面说三个的是RFC3489,那么RFC5389和RFC3489之间有什么区别呢?
首先我看消息类型,消息类型的最低两位必须是 0 0,就是RFC5389最新的协议 ,这是第一点的不同;
第二点的不同是,事物ID,老的里面是128位事物ID,在新的里面是 96位,其中有32位单独划出来了单独作为 Magic Cookie,一个魔法数,
以上两点就是RFC3489和5389的STUN消息头的区别。
下面我们再来看每一项,首先是这个STUN Message Type(2字节==16位)

1.前两位必须是00,以区分复用同一端口时STUN协议:就是不同的两个STUN协议复用同一个端口的时候,用它来区分哪个是最新的STUN协议RFC5389,哪个是老的STUN协议RFC3489,这是两位00的作用。
2.剩下的14位中有两位用于分类,就是C0和C1,C0和C1是占两位,所以它有四种类型,也就是四个分类,第一种是请求,第二种是指示,第三种是成功,第四种是错误应答,所以它将Message Type消息类型分成了四类。
3.剩下的12位是用于定义请求和指示,比如1代表绑定,2代表私有消息隐私数据,……,但是在STUN 3489里面定义了两个,就是用这12位定义了两种,但是5389里面就一种,一种就够了。
下图就是STUN Message Type的结构中的C0C1用于分类:

14位其中C0和C1分别在上图中两个不同位置,两个不是放在一起的,它是隔着的,隔着有什么好处,就是按照16进制的话,我们4位为一组,所有的M代表的是请求的值,C是分类,
这样划分,四个一组,第一组里面全都是请求,都是消息类型,第二组里面代表分类,第三组里面又代表另外一种分类。所以这两个进行不同的组合就能分成不同的类型了。
我们来看 C1C0:
C1C0第一个是C1第二个是C0。因为这个C1是处于这个高字节(存放在左侧低地址),对于网络数据对于协议分析对于二进制数据处理的人来说,这些都是比较容易理解的,对于没有接触过这些知识的
人可能稍微有点麻烦。
0b00:表式是一个请求
0b01:表示是一个指示
0b10:表示是请求成功的响应
0b11:表示是请求失败的响应
所以这里我们只要记住成功响应和失败的响应就好了。
下图就是STUN Message Type的结构中的最后12位定义的不同消息类型:
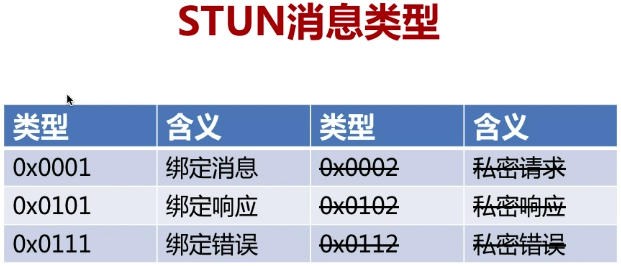
下面我们就可以看一下STUN的消息类型,它一共定义了6个消息类型,这个就是STUN的消息类型,但是RCF5389就将这个私密类型去掉了。就剩下一个 ,那完全够用了。
通过大小端模式理解C0C1:
对于这部分类型,为什么要了解呢,就是后面要对C0和C1要做详细的解释。
大端模式:数据的高字节保存在内存的低地址中
小端模式:数据的高字节保存在内存的高地址中
网络字节顺序:采用大端排序方式
了解这个模式之后,我们在聊C0和C1它是怎么排序的,大家就会很清楚它是怎么排序的。

图片为内存图,左侧为低地址,右侧为高地址!
网络字节排序采用大端,所以对于数据0x0001左侧(数据高字节)在内存的低地址中,先进行发送。如下图所示:0x0001中的1为数据低字节,却存放在内存最右侧(高地址)中!

0x0001:结合C1C0,可以知道,00是表示是一个请求消息
0x0101:C1为1,C0是0,是请求成功响应消息
0x0111:C1为1,C0是1,是请求失败的响应
其中最后一个数字表示具体的请求(是前面所提到的12位中的内容,1表示绑定)
下面这个字段是事物ID
新的RFC5389将它分成了两部分,前四个字节也就是32位是一个magic cookie,magic就是一个魔法数了,在这里是固定的0x2112A442,所以我们看到固定的值是这个的话,就是
RFC5389否则就是RFC3489。

1.前面4字节,32位,固定值0x2112A442. 通过它可以判断客户端是否可以识别某些属性。
通过它是可以识别客户端是否可以识别某些属性,因为不同的规范属性实际上是有变化的,所以你看到 这个魔法数之后就是RFC5389, RFC5389定义了一些新的属性,如果不是的
话,这些新的属性就可以忽略掉。
2.后面12字节 ,96位,标识同一个事物的请求和响应
剩下的12个字节,96位,标识同一个事物的请求和响应,当我们客户端发送多个请求的时候,就能通过这个事物ID将服务端返回的响应与之前发送的请求进行一一匹配。
字段是个96位的标识符,用来区分不同的STUN传输事务。对于request/response传输,事务ID由客户端选择,服务器收到后以同样的事务ID返回response;对于indication则由发送方自行选择。
事务ID的主要功能是把request和response联系起来,同时也在防止攻击方面有一定作用。服务端也把事务ID当作一个Key来识别不同的STUN客户端,因此必须格式化且随机在0~2^(96-1)之间。
重发同样的request请求时可以重用相同的事务ID,但是客户端进行新的传输时,必须选择一个新的事务ID。
(二)消息体
下面再看STUN Message Body 消息体,消息头后有0或多个属性。每个属性都使用TLV(动态)编码:Type,Length,Value

Length字段:
Value这个值是可以变化的,变化的程度怎么知道有多长呢?通过这个Length,这个Length标示了Value的长度,最终的消息是一个32位对齐的,如果最后不是32位对齐,要通过补0来达到对齐,这是整个Body。

字段存储了信息的长度,以字节为单位,不包括20字节的STUN头部。由于所有的STUN属性都是都是4字节对齐(填充)的,因此这个字段最后两位应该恒等于零,这也是辨别STUN包的一个方法之一。
Type字段:
为属性的类型。任何属性类型都有可能在一个STUN报文中出现超过一次。
除非特殊指定,否则其出现的顺序是有意义的:即只有第一次出现的属性会被接收端解析,而其余的将被忽略。为了以后版本的拓展和改进,属性区域被分为两个部分。
Type值在0x0000-0x7FFF之间的属性被指定为强制理解,意思是STUN终端必须要理解此属性,否则将返回错误信息;
而0x8000-0xFFFF之间的属性为选择性理解,即如果STUN终端不识别此属性则将其忽略。
目前STUN的属性类型由IANA维护。
这里列举定义的属性Type:

这里简要介绍几个常见属性的Value结构:
1.MAPPED-ADDRESS
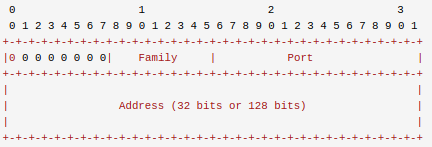
MAPPED-ADDRESS同时也是classic STUN的一个属性,之所以还存在也是为了前向兼容。其包含了NAT客户端的反射地址, Family为IP类型,即IPV4(0x01)或IPV6(0x02),Port为端口,Address为32位或128位的IP地址。
注意高8位必须全部置零,而且接收端必须要将其忽略掉。
2.XOR-MAPPED-ADDRESS
XOR-MAPPED-ADDRESS和MAPPED-ADDRESS基本相同,不同点是反射地址部分经过了一次异或(XOR)处理。对于X-Port字段, 是将NAT的映射端口以小端形式与magic cookie的高16位进行异或,再将结果转换成大端形式而得到的,X-Address也是类似。 之所以要经过这么一次转换,是因为在实践中发现很多NAT会修改payload中自身公网IP的32位数据,从而导致NAT打洞失败。

3.ERROR-CODE
ERROR-CODE属性用于error response报文中。其包含了300-699表示的错误代码,以及一个UTF-8格式的文字出错信息(Reason Phrase)。

另外,错误代码在语义上还与SIP和HTTP协议保持一致。比如:
300:尝试代替(Try Alternate),客户端应该使用该请求联系一个代替的服务器。这个错误响应仅在请求包括一个
USERNAME属性和一个有效的MESSAGE-INTEGRITY属性时发送;否则它不会被发送,而是发送错误代码为400的错误响应;
400:错误请求(Bad Request),请求变形了,客户端在修改先前的尝试前不应该重试该请求。
401:未授权(Unauthorized),请求未包括正确的资格来继续。客户端应该采用一个合适的资格来重试该请求。
420:未知属性(Unknown Attribute),服务器收到一个STUN包包含一个强制理解的属性但是它不会理解。
服务器必须将不认识的属性放在错误响应的UNKNOWN-ATTRIBUTE属性中。
438:过期Nonce(Stale Nonce),客户端使用的Nonce不再有效,应该使用响应中提供的Nonce来重试。
500:服务器错误(Server Error),服务器遇到临时错误,客户端应该再次尝试。
此外还有很多属性,如USERNAME,NONCE,REALM,SOFTWARE等,具体可以翻阅RFC3489。
属性的使用时机:(与具体有出入,以抓包内容为主)
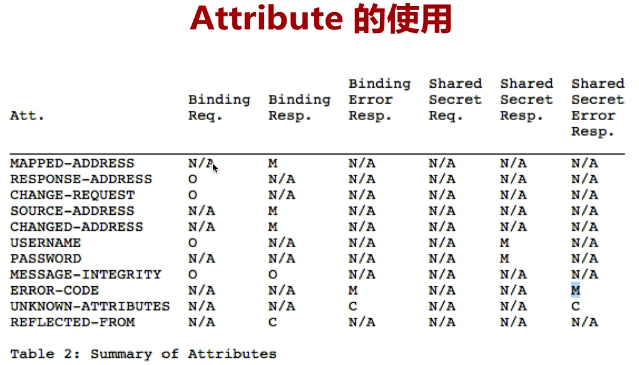
M:必须 O:可选 N/A:没有 C:客户端使用