一:Scala函数式编程
(一)匿名函数
object ClassTest{ def main(args:Array[String]):Unit={ var func = (x:Int)=> { //或者直接(x:Int)=>x+3 x+3 } println(func(3)) } }
匿名函数返回自动判断类型,不需要指定
![]()
(二)函数闭包
闭包:就是函数的嵌套,即在定义一个函数的时候,包含了另外一个函数的定义,在内函数中,可以访问外函数的变量
def func(n:Int):Int={ var i=10 var InnerFunc=(x:Int)=>x * i return InnerFunc(n) } def main(args:Array[String]):Unit={ println(func(3)) }
这里我们引入一个自由变量 i,这个变量定义在闭包函数外面。
这样定义的函数变量 InnerFunc 称为一个"闭包",因为它引用到函数外面定义的变量,定义这个函数的过程是将这个自由变量捕获而构成一个封闭的函数。
(三)柯里化
指的是将原来接受两个参数的函数变成新的接受一个参数的函数的过程。新的函数返回一个以原有第二个参数作为参数的函数。
一般函数定义:
def add(x:Int,y:Int) = x+y
柯里化定义写法:
def add(x:Int)(y:Int) = x+y
两者等价
(四)高阶函数(以函数作为参数)
object ClassTest{ def func(n:Int):Int={ n + 10 } def func2(f:(Int)=>Int,n:Int):Int={ n*f(3) } def main(args:Array[String]):Unit={ println(func2(func,3)) } }

(五)Scala常用高阶函数
定义一个集合:val numbers = List(1,2,3,4,5,6,7,8,9,10)
1.map:对集合中的每个元素执行一个函数运算,返回一个包含相同数目的新的集合

2.foreach: 类似map,对集合中的每个元素执行一个函数运算,跟map的区别是没有返回值

3.filter: 过滤,条件筛选

该匿名函数默认返回i%2==1结果,布尔类型。根据true,false决定是否输出
4.zip: 把两个列表的元素合并到一个由元素对组成的新的列表中
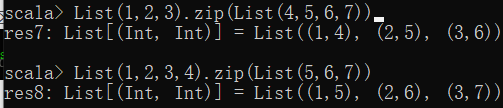
其中合并按照列表最短截取
5.partition:分区,根据条件(断言)的返回值对列表进行分区
![]()
6.find: 查找第一个满足条件的元素
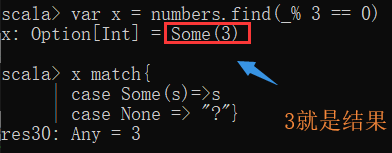
其中_代表list每一个元素
7.flatten:把一个嵌套的结构展开

8.flatMap: 相当于flatten + map

二:Scala的集合
集合分为可变集合和不可变集合
不可变集合必须要用val进行定义,否则里面的元素还是可以被修改的,当使用var进行对不可变集合的定义时,实际上是返回了一个新的集合,而老的集合并没有发生改变。
var不可变集合的修改:
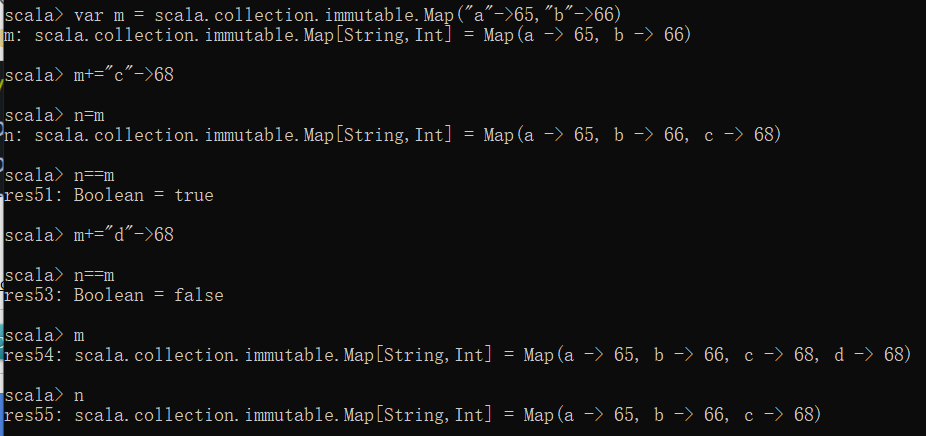
可以看出,当修改了不可变对象的值以后,实际上是返回了一个新的集合
补充:在scala中,== 默认比较内存地址
可变集合的对比:
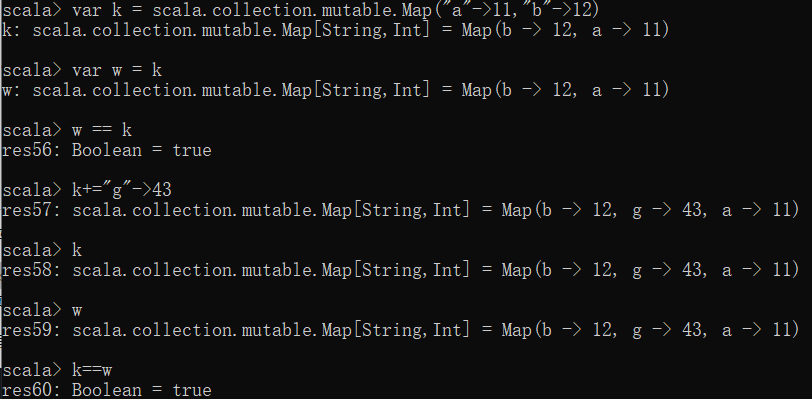
可以看出:修改可变集合后,还是同一对象
定义不可变集合需要导入scala.collection.immutable._,定义可变集合需要导入scala.collection.mutable._
对于immutable对象,它是线程安全的,在多线程下安全,没有竞态条件,而且由于不需要支持可变性, 可以尽量节省空间和时间的开销。所有的不可变集合实现都比可变集合更加有效的利用内存。
(一)不可变集合(在scala.collection.immutable中)
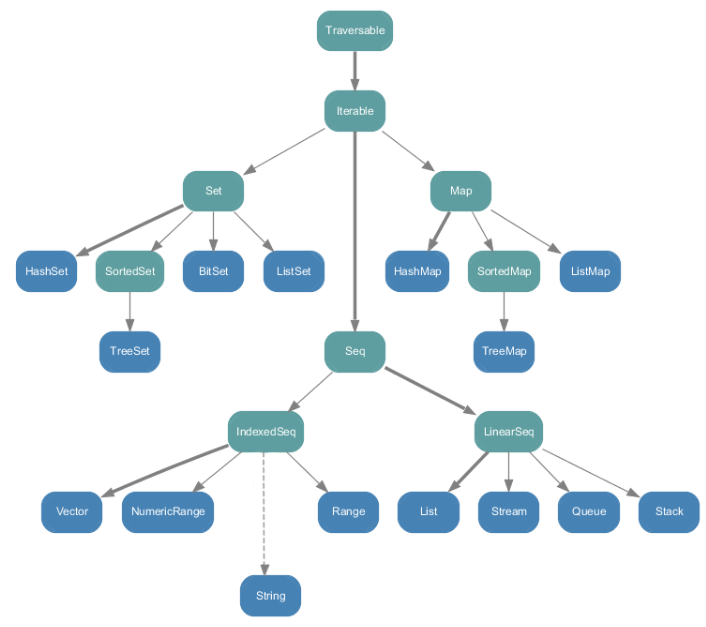
(二)可变集合类(在scala.collection.mutable中)
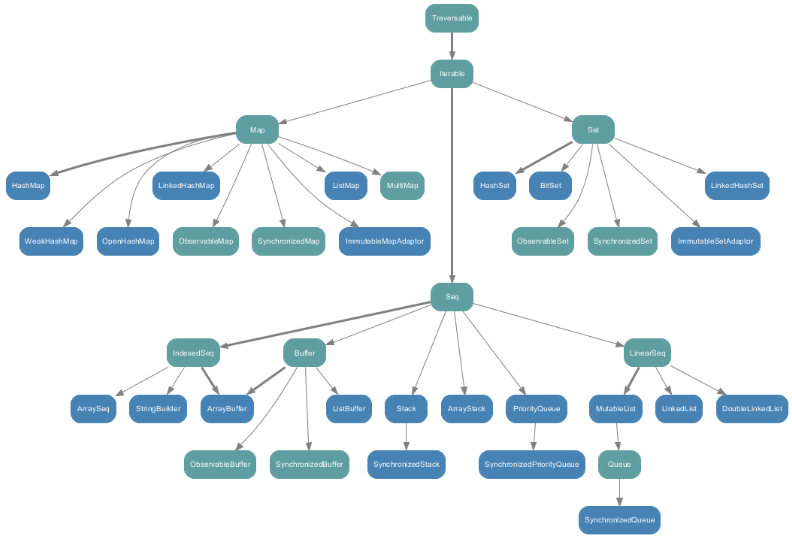
(三)Scala集合分类(3种)
Seq,是一组有序的元素。 Set,是一组没有重复元素的集合。 Map,是一组k-v对。
1.Map的部分操作(以可变集合为主、不可变查询操作相同而没有修改操作)

(1)获取:
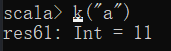
(2)查询元素是否存在:

(3)直接获取元素(若不存在,不抛出异常)
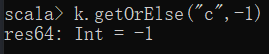
(4)更新元素

(5)添加元素

(6)删除元素

2.List的部分操作(属于seq有序、可重复)
Scala 列表类似于数组,它们所有元素的类型都相同,但是它们也有所不同:列表是不可变的,值一旦被定义了就不能改变,其次列表 具有递归的结构(也就是链接表结构)而数组不是。
(1)列表构造
// 字符串列表
val site: List[String] = List("Runoob", "Google", "Baidu")
// 整型列表
val nums: List[Int] = List(1, 2, 3, 4)
// 空列表
val empty: List[Nothing] = List()
// 二维列表
val dim: List[List[Int]] =
List(
List(1, 0, 0),
List(0, 1, 0),
List(0, 0, 1)
)
//或者使用List.tabulate()方法来创建,,第一个参数是行和列的长度,第二个参数是创建List所使用的函数
val mul = List.tabulate(4, 5)(_*_)
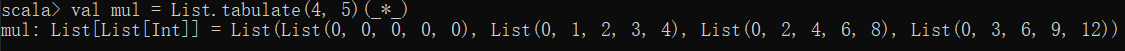
这里使用的_*_是一个语法,等价于下面的写法 * val mul = List.tabulate(4, 5)((row: Int, col: Int) => row * col)
其他列表构造写法有点扯。见官方吧
(2)列表基本操作
head 返回列表第一个元素
tail 返回一个列表,包含除了第一元素之外的其他元素
isEmpty 在列表为空时返回true
(3)列表连接
你可以使用 ::: 运算符或 List.:::() 方法或 List.concat() 方法来连接两个或多个列表。

(4)更多方法见官网,或者https://www.runoob.com/scala/scala-lists.html
3.序列(Vector和Range---都是不可变的,但是Vector可修改)
Vector:支持快速的查找和更新
Range:表示是一个整数序列,一段整数的范围
两者均属于seq,即有序也可重复
(1)vector定义
val v = Vector(1,2,3,4,5,6)
(2)Range定义
//定义Range,表示[0,5),左闭右开区间 var r1 = Range(0,5) //使用until来定义Range,左闭右开区间 var r2 = (0 until 5) //使用to来定义Range,闭区间 var r3 = (0 to 4) //指定步长的方式定义Range,Range里的是1-10里的单数 var r4 = Range(1,10,2)
(3)vector操作
//找出符合要求的第一个元素 println(v.find(_>3)) //输出Some(4) //将第三个元素变成100,注意,这里用了val,而Vector又是不可变集合,所以直接输出v结果是不会变化的 v.updated(2,100) println(v.updated(2,100))
(4)Range操作
//输出r1,r2 println(r1) println(r2) println(r3) println(r4) //Range相加:两个Range按顺序首尾相接 println((0 to 9) ++ ('A' to 'Z'))
4.set集合
Set是不重复元素的集合,本身是无序的,常用的有HashSet和TreeSet
HashSet有以下特点:
使用元素的hashCode值来决定元素的存储位置
不能保证元素的排列顺序,顺序有可能发生变化
不是Synchronized的,因此线程不安全
集合元素可以是null,但只能放入一个null
TreeSet有以下特点:
TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。
TreeSet支持两种排序方式,自然排序 和定制排序,其中自然排序为默认的排序方式。
LinkedHashSet有以下特点:
LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。
这样使得元素看起 来像是以插入顺 序保存的,也就是说,当遍历该集合时候,
LinkedHashSet将会以元素的添加顺序访问集合的元素。
LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet。
操作:https://www.runoob.com/scala/scala-sets.html
三:Scala模式匹配
(一)模式匹配match
给定一个子串,要求在某个字符串中找出与该子串相同的所有子串,这就是模式匹配。
Scala有一个强大的模式匹配机制,可以应用在switch语句,类型检查等
Scala还提供了样本类(case class),对模式匹配进行了优化
(1)普通匹配
var sign = 0 var ch1 = '-' ch1 match{ case '+' => sign = 1 case '-' => sign = -1 case _ => sign = 0 //同default,但是无法捕获该值 } println(sign)
推荐使用变量捕获
var str="Hello"
str(1) match{
case '+'=>println("+")
case '-'=>println("-")
case ch=>println(ch)
}
输出e
(2)结合_进行匹配筛选
//Scala的守卫:匹配某种类型的所有值 var ch2='1' var digit:Int = -1 ch2 match{ case '+' => println("这是一个加号") case '-' => println("这是一个减号") //使用if守卫,如果ch2是数字字符,就给digit返回ch2数字字符的数值 case _ if Character.isDigit(ch2) => digit = Character.digit(ch2, 10) case '1' | '2' =>println("1 or 2") case _ => println("其他") } println("digit:"+digit);
(3)类型匹配
//类型匹配,其中变量x,s的值就是v4的值 var v4:Any = 100 v4 match{ case x:Int => println("Int") case s:String => println("String") case _ => println("others") }
(4)数组匹配
//数组匹配 var myArray = Array(1,2,3) myArray match{ case Array() => println("这是一个空数组") case Array(0) => println("这个数组是Array(0)") case Array(x,y) => println("这个数组包含两个元素,和是"+(x+y)) case Array(x,y,z) => println("这个数组包含三个元素,和是"+(x+y+z)) case Array(x,_*) => println("这是一个数组") }
(5)List匹配...
(二)样本类--同isInstanceOf
简单的来说,Scala的样本类就是在普通的类定义前加case这个关键字,然后你可以对这些类来模式匹配
CaseClass带来的最大的好处是它们支持模式识别
class Fruit class Apple(name:String) extends Fruit class Banana(name:String) extends Fruit class Vehicle case class Car(name:String) extends Vehicle case class Bike(name:String) extends Vehicle def main(args: Array[String]): Unit = { var aApple:Fruit = new Apple("apple") var bBanana:Fruit = new Banana("banana") //使用isInstanceOf来判断某个对象是否是某一个类的对象 println(aApple.isInstanceOf[Fruit]) println(aApple.isInstanceOf[Apple]) println(bBanana.isInstanceOf[Apple]) //使用match匹配进行判断 var aCar:Vehicle = new Car("这是一辆汽车") aCar match{ case Car(name) => println("这是一个汽车") case Bike(name) => println("这是一个自行车") case _ => println("不太确定") }
四:Scala高级特性
(一)隐式转换函数
所谓隐式转换函数指的是implicit关键字修饰的且只有一个参数的函数。
class A{ var age:Int=10 def set(a:Int)={this.age=a} def say(){ println(s"A---${age}") } } class B extends A{ override def say(){ println(s"B---${age}") } } object ClassTest{ implicit def AtoB(a:A):B=new B() A隐式转换为B,名称可以任意 def toSay[T<%B](k:T){ //<%为视图定界 k.say() } def main(args:Array[String]):Unit={ var a:A = new A() var b:B = new B() b.set(20) toSay(a) toSay(b) } }

总结:
1、 隐式转换会首先从全局中寻找,寻找不到,才使用隐式参数
2、 隐式转换只能定义在 object 中
3、 如果隐式转换存在二义性,那么程序会跑错
(二) 隐式参数
使用implicit声明的函数参数叫作隐式参数,我们也可以使用隐式参数实现隐式的转换
1.隐式参数简单使用
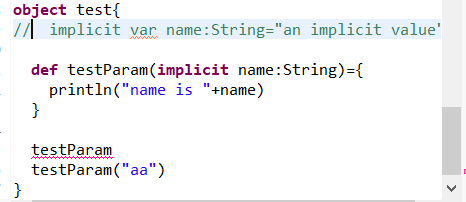


2.隐式参数另法:
object ClassTest{ def testParam2(name:String)(implicit age:Int=10):Unit={ println(name+" "+age) } def main(args:Array[String]):Unit={ testParam2("aa") // testParam2("aa",13) //隐式参数不能修改 } }

(三)隐式类
隐式类就是对类增加implicit修饰符,其作用主要是对类的功能加强


隐式类执行的过程:
Step1:当执行1.add(2)时,scala的编译器不会马上报错,它会在当前域中查找有没有implicit修饰的,同时是将Int作为参数的构造器,并且具有add方法的类,通过查找,找到了Calc类
Step2:利用隐式类Calc来执行add方法
注意:会将前面的1作为构造参数,后面的2作为方法调用传参
(四)泛型类
和Java相似,类和特质可以带类型参数,在Scala中,使用方括号来定义类型参数
这里定义了一个普通的类,但是content只能是Int类型,如果希望保存任意的类型,则需要使用泛型类
1.普通类定义
class User{ private var Age:Int=0 def set(age:Int)={ Age=age } def get():Int={ Age } }
2.泛型类定义
class User2[T]{ private var Age:T=_ //这里下划线代表可以是任何值 def set(age:T)={ Age=age } def get():T={ Age } }
泛型类测试:
object ClassTest{ def main(args:Array[String]):Unit={ var u=new User2[Int] u.set(20) println(u.get()) var v=new User2[String] v.set("二十") println(v.get()) } }

(五)泛型函数
创建一个泛型函数,使其能创建任意类型的数组,在创建泛型函数的时候,我们需要导入import scala.reflect.ClassTag,ClassTag会帮我们存储T的信息,Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会在编译器在编译的时候去掉。这个过程就称为类型擦除。泛型擦除是为了兼容jdk1.5之前的jvm,在这之前是不支持泛型的。
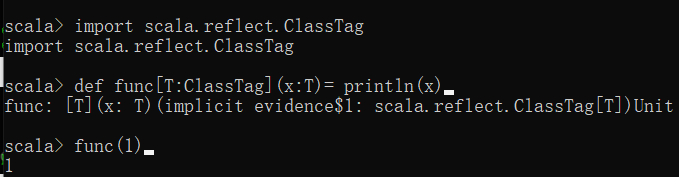

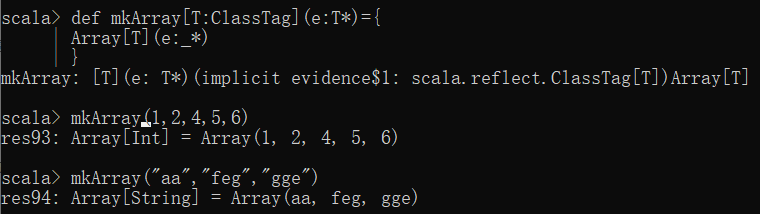
其中T*表示变长参数,e:_*将所有的参数看作一个整体
(六)泛型的上界和下界
类型的上界(Upper Bounds)与下界(Lower Bounds),是用来定义类型变量的范围。
类型上界:S <:T,也就是S必须是类型T本身或它的子类
类型下界:S >:T,也就是S必须是类型T本身或它的父类
例如:
基本类型:Int x:100<=x<=200,这里x的下界就是100,上界就是200
类型变量:A ->B->C->D,依次是后面的父类,定义变量D<: y<: B,这个时候变量y的类型只能是B、C、D

定义的类型A是不允许作为传参的!!
(七)视图界定(View bounds)
视界比上界使用的范围更广,除了所有的子类型,还允许隐式转换的类型,用<%表示。
尽量使用视界来取代泛型的上界,因为使用的范围更加广泛。
class A{ var age:Int=10 def set(a:Int)={this.age=a} def say(){ println(s"A---${age}") } } class B extends A{ override def say(){ println(s"B---${age}") } } class C extends B{ override def say(){ println(s"C---${age}") } } object ClassTest{ implicit def AtoB(a:A):B=new B() def toSay[T<%B](k:T){ k.say() } def main(args:Array[String]):Unit={ var a:A = new A() var b:B = new B() b.set(20) toSay(a) toSay(b) } }

或者:
先是使用泛型上界

可以知道,当我们传入参数Int时,是不允许传入的
使用视图定界(扩宽参数使用范围,使得隐式转换函数也可以使用)
object ClassTest{ implicit def IntToString(n:Int):String=n.toString() def contactString[T<%String](x:T,y:T)={ println(x+" "+y) } def main(args:Array[String]):Unit={ contactString("aa","dd") contactString(1,43) } }

(八)协变和逆变
Scala的类或特征的泛型定义中,如果在类型参数前面加入+符号,就可以使类或特征变成协变了
协变是指泛型变量的值可以是其本身的类或者其子类的类型
class A{ } class B extends A{ } class C[+T](t:T){ def eat(){ s"I want to eat " } } object ClassTest{ def main(args:Array[String]):Unit={ var c1:C[B]=new C[B](new B) var c2:C[A]=c1 c1.eat() c2.eat() } }
逆变就是协变反过来了,是指泛型变量的值可以是其本身或者其父类
在类或特征的定义中,在类型参数之前加上一个-符号,就可以定义逆变泛型类和特征了