最近学习了某站上老师讲的Redis入门课程,老师讲的很基础,从最初的Redis安装到搭建集群,到最后的问题讲解。适合刚刚接触Redis和想要复习Redis的初学者,在这里和老师的笔记做了个同步文档,希望可以对大家有帮助。
教程来源:https://www.bilibili.com/video/BV1FZ4y1u7ny
因为这里没有用docker,所以5.1章节抽取本站教程转载。
一、Redis介绍
1.1 引言
1.由于用户量增大,请求数量也随之增大,数据压力过大。
例:数据库根据SQL语句去磁盘通过io来拿到数据,数据压力就会比较大,轻则查询效率降低,重则服务器宕机。
解决:针对热点数据添加缓存,把数据放到Redis,查询都找Redis。
原理:Redis是基于内存存储数据和读取数据的,并且支持并发量很大。
2.多台服务器之间,数据不同步。
例:客户端发送请求,说不定请求会发到哪台服务器中,比如客户在登录中,在服务器1存放了客户的唯一标识,下一次如果请求发送到服务器2,就没有标识了。
解决:不用Session来存放用户数据,用Redis统一存放。
原理:Redis是独立于Tomcat服务器之外的单独中间件,可以将之前存储在Session中的共享数据统一的存放在Redis中,服务器1和服务器2都找Redis。
3.多台服务器之间的锁,已经不存在互斥性了。
例:在服务器1使用锁操作,和在服务器2使用锁操作,两把锁不存在互斥性,会导致锁失效。
解决:使用Redis
原理:Redis基于它接收用户的请求是单线程的,可以帮我们实现类似锁的功能。
1.2 NoSQL
Redis就是一款NoSQL
NoSQL -> 菲关系型数据库 -> Not Only SQL
除了关系型数据库都是非关系型数据库。
NoSQL只是一种概念,泛指非关系型数据库,和关系型数据库做一个区分。
1.3 Redis介绍
Redis(Remote Dictionary Server)远程字典服务,由C语言去编写,所以不需要java环境。
二、Redis安装
2.1 下载中文版Redis可视化软件
RedisDesktopManager

2.2 为Redis赋值

2.3 在Redis中查看

三、Redis常用命令
官网Redis命令参考文档:redisdoc.com
3.1 Redis存储数据的结构
常用的五种数据结构
key-string:一个key对应一个值
key-hash:一个key对应一个Map
key-list:一个key对应一个列表
key-set:一个key对应一个集合
key-zset:一个key对应一个有序的集合
另外三种数据结构。
HyperLogLog:计算近似值的。
GEO:存储地理位置(经纬度)
BIT:一般存储的也是一个字符串,存储的是一个byte[]
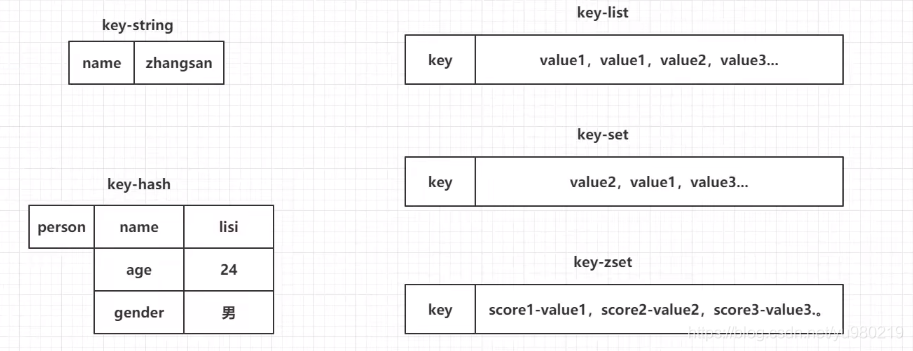
key-string:最常用的,一般用于存储一个值
key-hash:存储一个对象数据的
key-list:使用list结构实现栈和队列结构
key-set:交集,差集和并集的操作
key-zest:排行榜,积分存储等操作。
3.2 String常用命令
#1. 添加值
set key value
#2. 取值
get key
#3. 批量操作
mset key value [key value...]
mget key [key...]
#4. 自增命令(自增1)(应用场景 -> 点赞)
incr key
#5. 自减命令(自减1)
decr key
#6. 自增或自减指定数量
incrby key <increment>
decrby key <increment>
#7. 设置值的同时。指定生存时间(每次向Redis中添加数据时,尽量都设置上生存时间)
setex key <second> value
#8. 设置值,如果当前key不存在的话(如果这个key存在,什么事都不做,如果这个key不存在,和set命令一样)
setnx key value
#9. 在key对应的value后,追加内容
append key value
#10. 查看value字符串的长度
strlen key
3.3 hash常用命令
#1. 存储数据
hset key field value
#2. 获取数据
hget key field
#3. 批量操作
hmset key field value [field value ...]
hmget key field [field ...]
#4. 自增(指定自增的值)
hincrby key field increment
#5. 设置值(如果key-field不存在,那么就正常添加,如果存在,什么事都不做)
hsetnx key field value
#6. 检查field是否存在
hexists key field
#7. 删除key对应的某一个field,可以删除多个
hdel key field [field]
#8. 获取当前hash结构中的全部field和value
hgetall key
#9. 获取当前hash结构中的全部field
hkeys key
#10. 获取当前hash结构中的全部value
hvals key
#11. 获取当前hash结构中field的数量
hlen key
3.4 list常用命令
#1. 存储数据(从左侧插入数据,从右侧插入数据)
lpush key value [value ...]
rpush key value [value ...]
#2. 存储数据(如果key不存在,什么事都不做,如果key存在,但是不是list结构,什么都不做)
lpushx key value
rpushx key value
#3. 修改数据(在存储数据时,指定好你的索引位置,覆盖之前索引位置的数据,index超出整个列表的长度,也会失败)
lset key index value
#4. 弹栈方式获取数据(左侧弹出数据,从右侧弹出数据)
lpop key
rpop key
#5. 获取指定索引范围的数据(start从0开始,stop输入-1代表最后一个)
lrange key start stop
#6. 获取指定索引位置的数据
lindex kek index
#7. 获取整个列表的长度
llen key
#8. 删除列表中的数据(删除当前列表中的count个value值;count>0,从左侧向右侧删除;count<0,从右侧向左侧删除;count==0,删除列表中全部数据)
lrem key count value
#9. 保留列表中的数据(保留指定索引范围内的数据,超过整个索引范围被移除掉)
ltrim key start stop
#10. 将一个列表中最后的一个数据,插入到另外一个列表的头部位置
rpoplpush list1 list2
3.5 set常用命令
#1. 存储数据
sadd key member [member ...]
#2. 获取数据(获取全部数据)
smembers key
#3. 随机获取一个数据(获取的同时,移除数据,count默认为1,代表弹出数据的数量)
spop key [count]
#4. 交集(取多个set集合交集)
sinter set1 set2 ...
#5. 并集(获取全部集合中的数据)
sunion set1 set2 ...
#6. 差集(获取多个集合中不一样的数据)
sdiff set1 set2 ... (获取set1-set2)
sdiff set2 set1 ... (获取set2-set1)
#7. 删除数据
srem key member [member ...]
#8. 查看当前的set集合中是否包含这个值
sismember key member
3.6 zset常用命令
#1. 添加数据(score必须是一个数值,member不允许重复)
zadd key score member [socre member ...]
#2. 修改member的分数(如果member是存在于key中的,正常增加分数,如果member不存在,这个命令就相当于zadd)
zincrby key increment member
#3. 查看指定的member的分数
zscore key member
#4. 获取zset中数据的数量
zcard key
#5. 根据score的范围查询member数量
zcount key min max
#6. 删除zset中的成员
zrem key member [member ...]
#7. 根据分数从小到大排序,获取指定范围内的数据(withscore如果添加这个参数,那么会返回member对应的分数)
zrange key start stop [withscores]
#8. 根据分数从大到小排序,获取指定范围内的数据
zrevrange key start stop [withscores]
#9. 根据分数的返回去获取member(withscores代表返回score,添加limit,就和MySQL一样,如果不希望等于min或者max的值被查询出来可以采用‘(分数’相当于 < 但是不等于的方式,最大值和最小值使用+inf和-inf来表示)
zrangebyscore key min max [withscores] [limit offset count]
#10. 根据分数的返回去获取member(withscores代表返回score,添加limit,就和MySQL一个样)
zrangebyscore key max min [withscores] [limit offset count]
3.7 key常用命令
#1. 查看Redis中的全部的key(pattern: *, xxx*, *xxx)
keys pattern
#2. 查看某一个key是否存在(1 - key存在,0 - key不存在)
exists key
#3. 删除key
del key [key ...]
#4. 设置key的生存时间,单位为秒,单位为毫秒,设置还能活多久
expire key second
pexpire key milliseconds
#5. 设置key的生存时间,单位为秒,单位为毫秒,设置能活到什么时间点
expireat key timestamp
pexpireat key milliseconds
#6. 查看key的剩余生存时间,单位为秒,单位为毫秒(-2 - 当前key不存在,-1 - 当前key没有设置生存时间,具体剩余的生存时间)
ttl key
pttl key
#7. 移除key的生存时间(1 - 移除成功,0 - key不存在生存时间,key不存在)
persist key
#8. 选择操作的库
select 0~15
#9. 移动key到另外一个库中
move key db
3.8 库的常用命令
#1. 清空当前所在的数据库
flushdb
#2. 清空全部数据库
flushall
#3. 查看当前数据库中有多少个key
dbsize
#4. 查看最后一次操作的时间
lastsave
#5. 实时监控redis服务接收到的目录
monitor
四、Java连接Redis
Jedis连接Redis,Lettuce连接Redis
4.1 Jedis连接Redis
- 创建maven项目
- 导入需要的依赖
- 测试
public class JedisTest {
@Test
public void set(){
//1. 连接Redis
Jedis jedis=new Jedis("192.168.200.130",6379);
//2. 操作Redis - 因为Redis的命令是什么,Jedis的方法就是什么
jedis.set("name","王五");
//3. 释放资源
jedis.close();
}
@Test
public void get(){
//1. 连接Redis
Jedis jedis=new Jedis("192.168.200.130",6379);
//2. 操作Redis - 因为Redis的命令是什么,Jedis的方法就是什么
String value=jedis.get("name");
System.out.println(value);
//3. 释放资源
jedis.close();
}
}
4.2 Jedis如何存储一个对象到Redis以Byte[]的形式
准备一个User实体类
public class User implements Serializable {
// serialVersionUID
// NoArgsConstructor
// AllArgsConstructor
private Integer id;
private String name;
private Date birthday;
// get set...
// toString ...
}
导入spring-context依赖
创建Demo类,编写测试内容
public class JedisTest2 {
// 存储对象 - 以byte[]形式存储在Redis中
@Test
public void setByteArray(){
//1. 连接Redis
Jedis jedis=new Jedis("192.168.200.130",6379);
//-------------------------------
//2.1 准备key(String)-value(User)
String key="user";
User value=new User(10,"李四",new Date());
//2.2 将key和value转换为byte[]
byte[] byteKey = SerializationUtils.serialize(key);
byte[] byteValue = SerializationUtils.serialize(value);
//2.3 将key和value存储到Redis
jedis.set(byteKey,byteValue);
//-------------------------------
//3. 释放资源
jedis.close();
}
// 获取对象 - 以byte[]形式在Redis中获取
@Test
public void getByteArray(){
//1. 连接Redis
Jedis jedis=new Jedis("192.168.200.130",6379);
//-------------------------------
//2.1 准备key
String key="user";
//2.2 将key转换为byte[]
byte[] byteKey = SerializationUtils.serialize(key);
//2.3 jedis去Redis中获取value
byte[] value = jedis.get(byteKey);
//2.4 将value反序列化为User对象
User user = (User) SerializationUtils.deserialize(value);
//2.5 输出
System.out.println(user.toString());
//-------------------------------
//3. 释放资源
jedis.close();
}
}
4.3 Jedis如何存储一个对象到Redis以String的形式
public class JedisTest3 {
// 存储对象 - 以String形式存储
@Test
public void setString(){
//1. 连接Redis
Jedis jedis=new Jedis("192.168.200.130",6379);
//2.1 准备key(String)-value(User)
String stringKey="stringUser";
User value=new User(2,"李四",new Date());
//2.2 使用fastJSON将value转化为json字符串
String stringValue = JSON.toJSONString(value);
//2.3 存储到redis中
jedis.set(stringKey,stringValue);
//3. 释放资源
jedis.close();
}
// 获取对象 - 以String形式获取
@Test
public void getString(){
//1. 连接Redis
Jedis jedis=new Jedis("192.168.200.130",6379);
//2.1 准备一个key
String key="stringUser";
//2.2 去Redis中查询value
String value = jedis.get(key);
//2.3 存储到redis中
User user = JSON.parseObject(value, User.class);
//2.4 输出
System.out.println(user.toString());
//3. 释放资源
jedis.close();
}
}
4.4 Jedis的连接池操作
@Test
public void pool2(){
//1. 创建连接池的配置信息
GenericObjectPoolConfig poolConfig=new GenericObjectPoolConfig();
poolConfig.setMaxTotal(100); // 连接池中最大活跃数
poolConfig.setMaxIdle(10); // 最大空闲数
poolConfig.setMinIdle(5); // 最小空闲数
poolConfig.setMaxWaitMillis(3000); // 当连接池空了,多久没获取到jedis对象就超时
//2. 创建连接池
JedisPool pool=new JedisPool(poolConfig,"192.168.200.130",6379);
//3. 通过连接池获取Jedis对象
Jedis jedis = pool.getResource();
//4. 操作
String value=jedis.get("stringUser");
System.out.println(value);
//5. 释放资源
jedis.close();
}
4.5 Redis的管道操作
因为在操作Redis的时候,执行一个命令需要先发送请求到Redis服务器,这个过程需要经历网络的延迟,Rdis还需要给客户端一个响应。
如果我需要一次性执行很多个命令,上述的方式效率很低,可以通过Redis的管道,先将命令放到客户端的一个Pipeline中,之后一次性的将全部命令都发送Redis服务,Redis服务一次性的将全部的返回结果响应给客户端。
(提高Redis并发能力,处理请求的效率更高)
// Redis管道的操作
@Test
public void pipeline(){
//1. 创建连接池
JedisPool pool=new JedisPool("192.168.200.130",6379);
long l = System.currentTimeMillis();
//2. 获取一个连接对象
Jedis jedis = pool.getResource();
//3. 执行incr - 10000次
for(int i=0;i<10000;i++){
jedis.incr("qq");
}
//4. 释放资源
jedis.close();
// =================================
//2. 获取一个连接对象
long l1 = System.currentTimeMillis();
Jedis jedis1=pool.getResource();
//3. 创建管道
Pipeline pipelined = jedis1.pipelined();
//4. 执行incr - 10000次放到管道中
for(int i=0;i<10000;i++){
jedis.incr("pp");
}
//5. 执行命令
pipelined.syncAndReturnAll();
//6. 释放资源
jedis1.close();
System.out.println(System.currentTimeMillis()-l);
System.out.println(System.currentTimeMillis()-l1);
}
五、Redis其它配置及集群
5.1 Redis的AUTH
Redis默认配置是不需要密码认证的,也就是说只要连接的Redis服务器的host和port正确,就可以连接使用。这在安全性上会有一定的问题,所以需要启用Redis的认证密码,增加Redis服务器的安全性。
1. 修改配置文件
Redis的配置文件默认在/etc/redis.conf,找到如下行:
#requirepass foobared
去掉前面的注释,并修改为所需要的密码:
requirepass myPassword (其中myPassword就是要设置的密码)
2. 重启Redis
如果Redis已经配置为service服务,可以通过以下方式重启:
service redis restart
如果Redis没有配置为service服务,可以通过以下方式重启:
/usr/local/bin/redis-cli shutdown
/usr/local/bin/redis-server /etc/redis.conf
3. 登录验证
设置Redis认证密码后,客户端登录时需要使用-a参数输入认证密码,不添加该参数虽然也可以登录成功,但是没有任何操作权限。如下:
$ ./redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> keys *
(error) NOAUTH Authentication required.
使用密码认证登录,并验证操作权限:
$ ./redis-cli -h 127.0.0.1 -p 6379 -a myPassword
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "myPassword"
看到类似上面的输出,说明Reids密码认证配置成功。
除了按上面的方式在登录时,使用-a参数输入登录密码外。也可以不指定,在连接后进行验证:
$ ./redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> auth myPassword
OK
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "myPassword"
127.0.0.1:6379>
4. 在命令行客户端配置密码(redis重启前有效)
前面介绍了通过redis.conf配置密码,这种配置方式需要重新启动Redis。也可以通命令行客户端配置密码,这种配置方式不用重新启动Redis。配置方式如下:
127.0.0.1:6379> config set requirepass newPassword
OK
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "newPassword"
注意:使用命令行客户端配置密码,重启Redis后仍然会使用redis.conf配置文件中的密码。
5. 在Redis集群中使用认证密码
如果Redis服务器,使用了集群。除了在master中配置密码外,也需要在slave中进行相应配置。在slave的配置文件中找到如下行,去掉注释并修改与master相同的密码即可:
# masterauth master-password
6. Jedis客户端中使用auth
//连接Redis
Jedis jedis=new Jedis("192.168.200.130",6379);
jedis.auth("123");
//创建连接池(3000:超时时间;123:auth密码)
JedisPool pool=new JedisPool(poolConfig,"192.168.200.130",6379,3000,"123");
5.2 Redis的事务
Redis的事务:一次事务操作,该成功的成功,该失败的失败。
先开启事务,执行一系列的命令,但是命令不会立即执行,会被放在一个队列中,如果你执行事务,那么这个队列中的命令全部执行,如果取消了事务,一个队列中的命令全部作废。
- 开启事务:multi
- 输入要执行的命令 -> 放到一个队列中
- 执行事务:exec
- 取消事务:discard
Redis的事务向发挥功能,需要配置watch监听机制
在开启事务之前,先通过watch命令去监听一个或多个key,在开启事务之后,如果有其他客户端修改了我监听的key,事务会自动取消。
如果执行了事务,或者取消了事务,watch监听自动消除,一般不需要去手动执行unwatch。
5.3 Redis持久化机制
RDB是Redis默认的持久化机制
RDB是持久化文件,速度比较快,而且存储的是一个二进制的文件,传输起来很方便。
RDB持久化的时机:
save 900 1:在900秒内,有1个key改变了,就执行RDB持久化。
save 300 10:在300秒内,有10个key改变了,就执行RDB持久化。
save 60 10000:在6秒内,有10000个key改变了,就执行RDB持久化。RDB无法保证数据的绝对安全。
# 开启RDB持久化的压缩
rdbcompression yes
# RDB持久化文件的名称
dbfilename redis.rdb
AOF持久化机制默认是关闭的,Redis官方推荐同时开启RDB和AOF持久化,更安全,避免数据丢失。
AOF持久化的速度,相对RDB是较慢的,存储的是一个文本文件,到了后期文件会比较大,传输困难。
AOF的持久化时机。
appendfsync always:每执行一个写操作,立即持久化到AOF文件中,性能比较低。
appendfsync everysec:每秒执行一次持久化。
appendfsync no:会根据你的操作系统不同,环境的不同,在一定时间内执行一次持久化。
AOF相对RDB更安全,推荐同时开启AOF和RDB。
# 代表开启AOF持久化
appendonly yes
# AOF文件的名称
appendfilename "redis.aof"
同时开启RDB和AOF的注意项:
如果同时开启了AOF和RDB持久化,那么Redis宕机重启之后,需要加载一个持久化文件,优先选择AOF文件。
如果先开启了RDB,再次开启AOF,如果RDB执行了持久化,那么RDB文件中的内容会被AOF覆盖掉。
5.4 Redis的主从架构
单机版Redis存在读写瓶颈的问题
5.5 哨兵
哨兵可以帮助我们解决主从架构中的单点故障问题
准备哨兵的配置文件,并且在容器内部手动启动哨兵即可
# 哨兵需要后台启动
daemonize no
# 指定Master 节点的ip的端口(主)
sentinel monitor master localhost 6379 2
# 指定Master 节点的ip的端口(主)
sentinel monitor master master 6379 2
# 哨兵每隔多久监听一次redis架构
sentinel down-after-milliseconds master 10000
在Redis容器内部启动sentinel即可
5.6 Redis的集群
Redis集群在保证主从加哨兵的基本功能之外,还能够提升Redis存储的能力
- Redis集群是无中心的。
- Redis集群有一个ping-pang机制。
- 投票机制,Redis集群节点的数量必须是2n+1。
- Redis集群中默认分配了16384个hash槽,在存储数据时,就会将key进行crc16的算法,并且对16384取余,根据最终的结果,将key-value存放到执行Redis节点中,而且每一个Redis集群都在维护着相应的hash槽。
- 为了保证数据的安全性,每一个集群的节点,至少要跟着一个从节点。
- 单独的针对Redis集群中的某一个节点搭建主从。
- 当Redis集群中,超过半数的节点宕机之后,Redis集群就瘫痪了。
# redis.conf
# 指定redis的端口号
port 7001
# 开启Redis集群
cluster-enabled yes
# 集群信息的文件
cluster-config-file nodes-7001.conf
# 集群的对外ip地址
cluster-announce-ip 192.168.200.130
# 集群的对外port
cluster-announce-port 7001
# 集群的总线端口
cluster-announce-bus-port 17001
启动了6个Redis的节点
随便跳转到一个容器内部,使用redis-cli管理集群
六、Redis常见问题
6.1 key的生存时间到了,Redis会立即删除吗?
不会立即删除。
定期删除:
Redis每隔一段时间就会去查看Redis设置了过期时间的key。会在100ms的间隔中默认查看3个key。
惰性删除:
如果当你去查询一个已经过了生存时间的key时,Redis会查看当前key的生存时间,是否已经到了,直接删除当前key,并且给用户返回一个空值。
6.2 Redis的淘汰机制
在Redis内存已经满的时候,添加了一个新的数据,执行淘汰机制。
volatile-lru:
在内存不足时,Redis会在已经设置过了生存时间的key中干掉一个最近最少使用的key。
allkeys-lru:
在内存不足时,Redis会在全部的key中干掉一个最近最少使用的key。
volatile-lfu:
在内存不足时,Redis会在已经设置过了生存时间的key中干掉一个最近最少频次使用的key。
allkeys-lfu:
在内存不足时,Redis会在全部的key中干掉一个最近最少频次使用的key。
volatile-random:
在内存不足时,Redis会在已经设置过了生存时间的key中随机干掉一个。
allkeys-random:
在内存不足时,Redis会在全部的key中随机干掉一个。
volatile-ttl:
在内存不足时,Redis会在已经设置过了生存时间的key中干掉一个剩余生存时间最少的key。
noeviction:(默认)
在内存不足时,直接报错
指定淘汰机制的方式:maxmemory-policy noeviction
设置Redis的最大内存:maxmemory
6.3 缓存的常见问题
缓存穿透:
问题出现的原因:查询的数据,Redis中没有,数据库也没有。
1:根据id查询时,如果id是自增的,将id的最大值放到Redis中,在查询数据库之前,直接比较一下id。
2:如果id不是整型,可以将全部的id放到set中,在用户查询之前,去set中查看一下是否有一个id。
3:获取客户端的ip地址,可以将ip的访问添加限制。
缓存击穿
问题:缓存中的热点数据,突然到期了,造成了大量的请求都去访问数据库,造成数据库宕机。
1.在访问缓存中没有的时候,直接添加一个锁,让几个请求去访问数据库,避免数据库宕机。
2.热点数据的生存时间去掉。
缓存雪崩
问题:当大量缓存同时到期时,最终大量的请求同时去访问数据库,导致数据库宕机。
将缓存中的数据的生存时间,设置为30~60分钟的一个随机时间。
缓存倾斜
问题:热点数据放在了一个Redis节点上,导致Redis节点无法承受住大量的请求,最终Redis宕机。
1.扩展主从架构,搭建大量的从节点,缓解Redis的压力。
2.可以在Tomcat中JVM缓存,在查看Redis之前,先去查询Tomcat中的缓存。
在内存不足时,Redis会在全部的key中干掉一个最近最少频次使用的key。
volatile-random:
在内存不足时,Redis会在已经设置过了生存时间的key中随机干掉一个。
allkeys-random:
在内存不足时,Redis会在全部的key中随机干掉一个。
volatile-ttl:
在内存不足时,Redis会在已经设置过了生存时间的key中干掉一个剩余生存时间最少的key。
noeviction:(默认)
在内存不足时,直接报错
指定淘汰机制的方式:maxmemory-policy noeviction
设置Redis的最大内存:maxmemory
6.3 缓存的常见问题
缓存穿透:
问题出现的原因:查询的数据,Redis中没有,数据库也没有。
1:根据id查询时,如果id是自增的,将id的最大值放到Redis中,在查询数据库之前,直接比较一下id。
2:如果id不是整型,可以将全部的id放到set中,在用户查询之前,去set中查看一下是否有一个id。
3:获取客户端的ip地址,可以将ip的访问添加限制。
缓存击穿
问题:缓存中的热点数据,突然到期了,造成了大量的请求都去访问数据库,造成数据库宕机。
1.在访问缓存中没有的时候,直接添加一个锁,让几个请求去访问数据库,避免数据库宕机。
2.热点数据的生存时间去掉。
缓存雪崩
问题:当大量缓存同时到期时,最终大量的请求同时去访问数据库,导致数据库宕机。
将缓存中的数据的生存时间,设置为30~60分钟的一个随机时间。
缓存倾斜
问题:热点数据放在了一个Redis节点上,导致Redis节点无法承受住大量的请求,最终Redis宕机。
1.扩展主从架构,搭建大量的从节点,缓解Redis的压力。
2.可以在Tomcat中JVM缓存,在查看Redis之前,先去查询Tomcat中的缓存。