联合主键问题
SQLAlchemy提供了联合主键支持,但是Django至今都没有支持。
Django只支持单一主键,但对于本次基于Django测试的表就只能增加一个单一主键
了。
原因,请参看 https://code.djangoproject.com/wiki/MultipleColumnPrimaryKeys 。Django 到目前为
止也没有提供这种Composite primary key
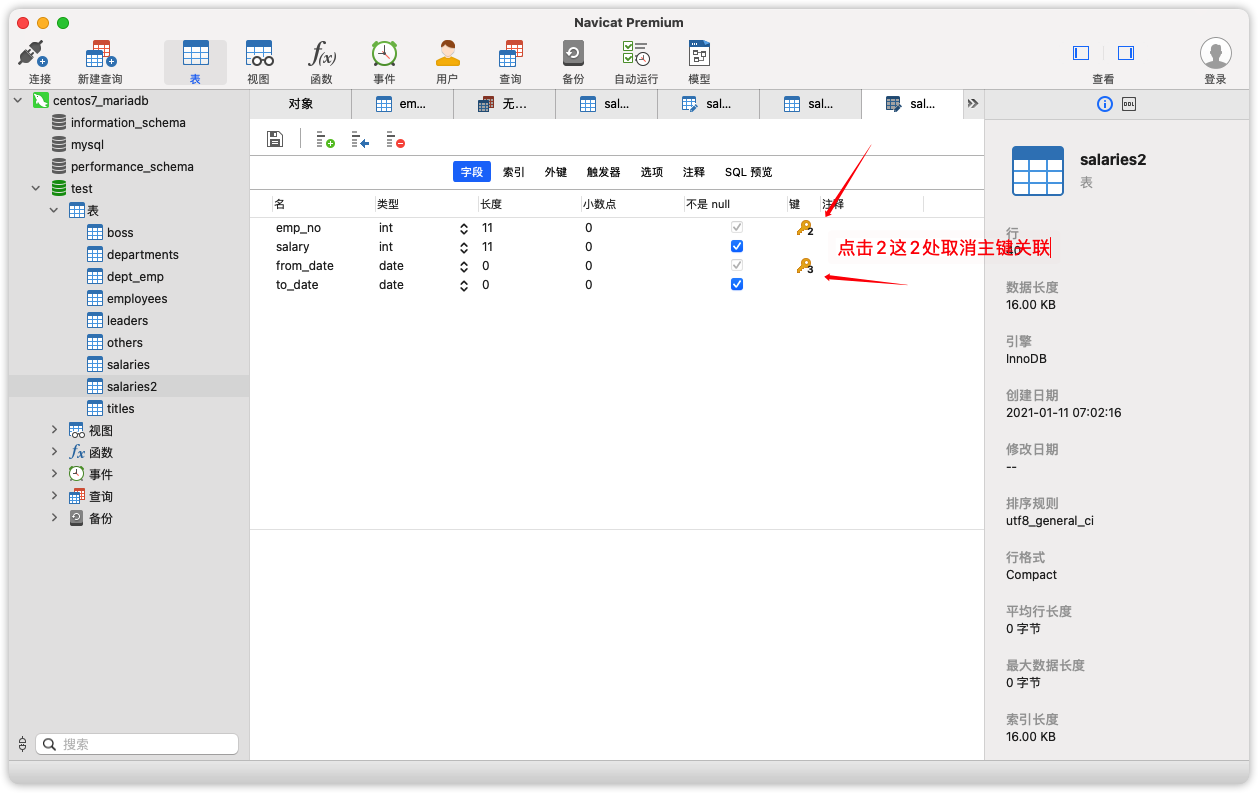
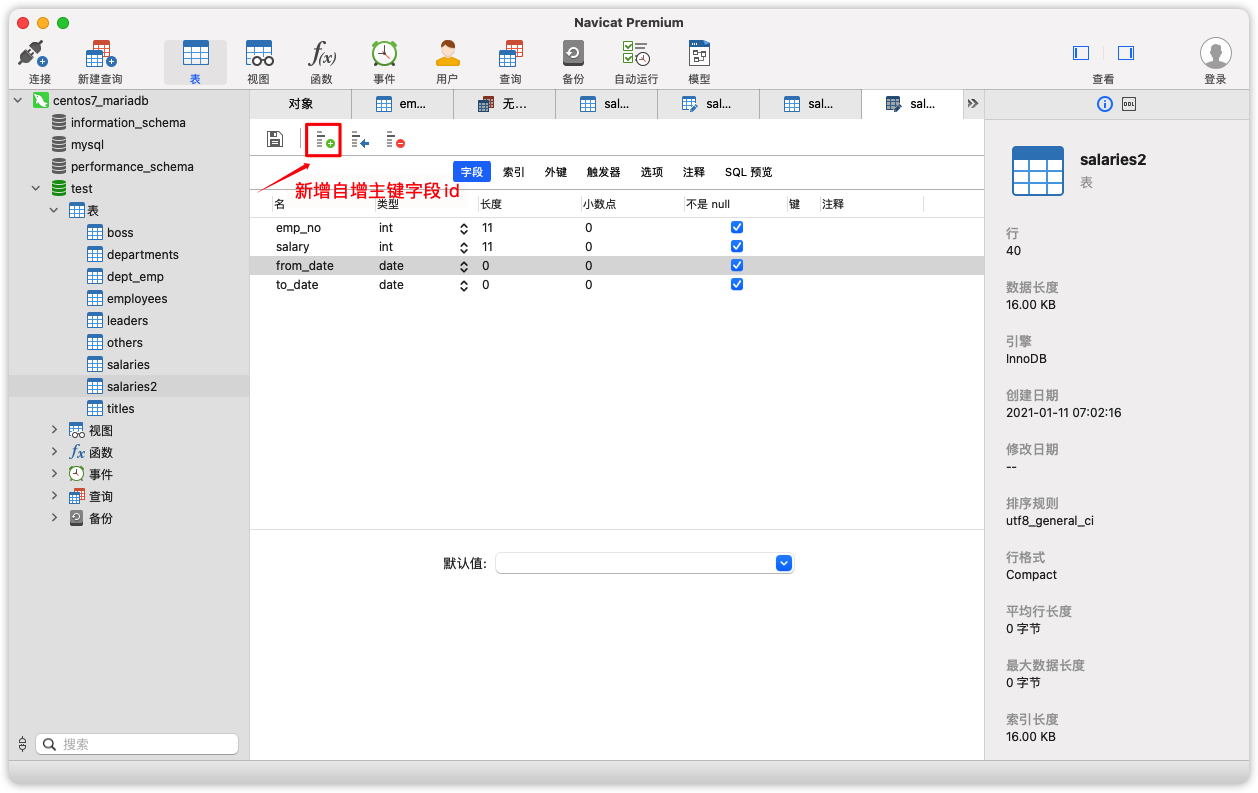
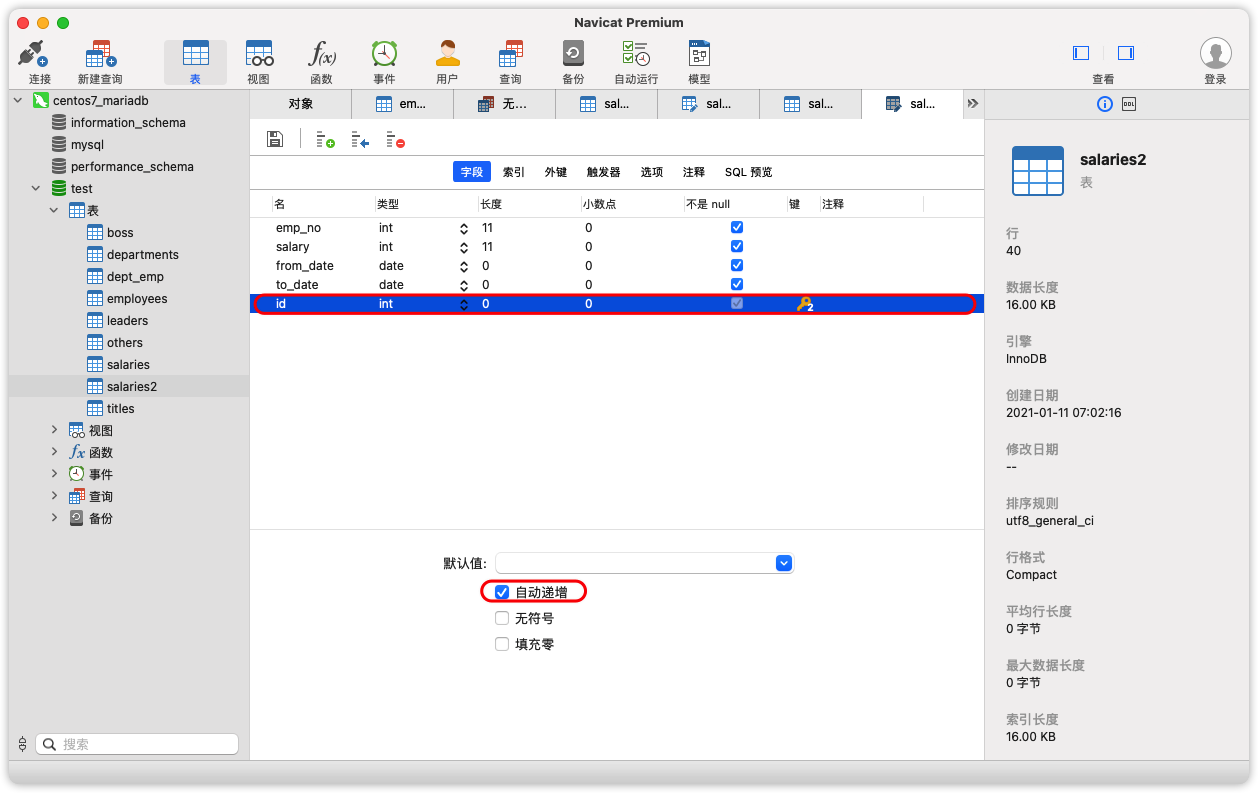
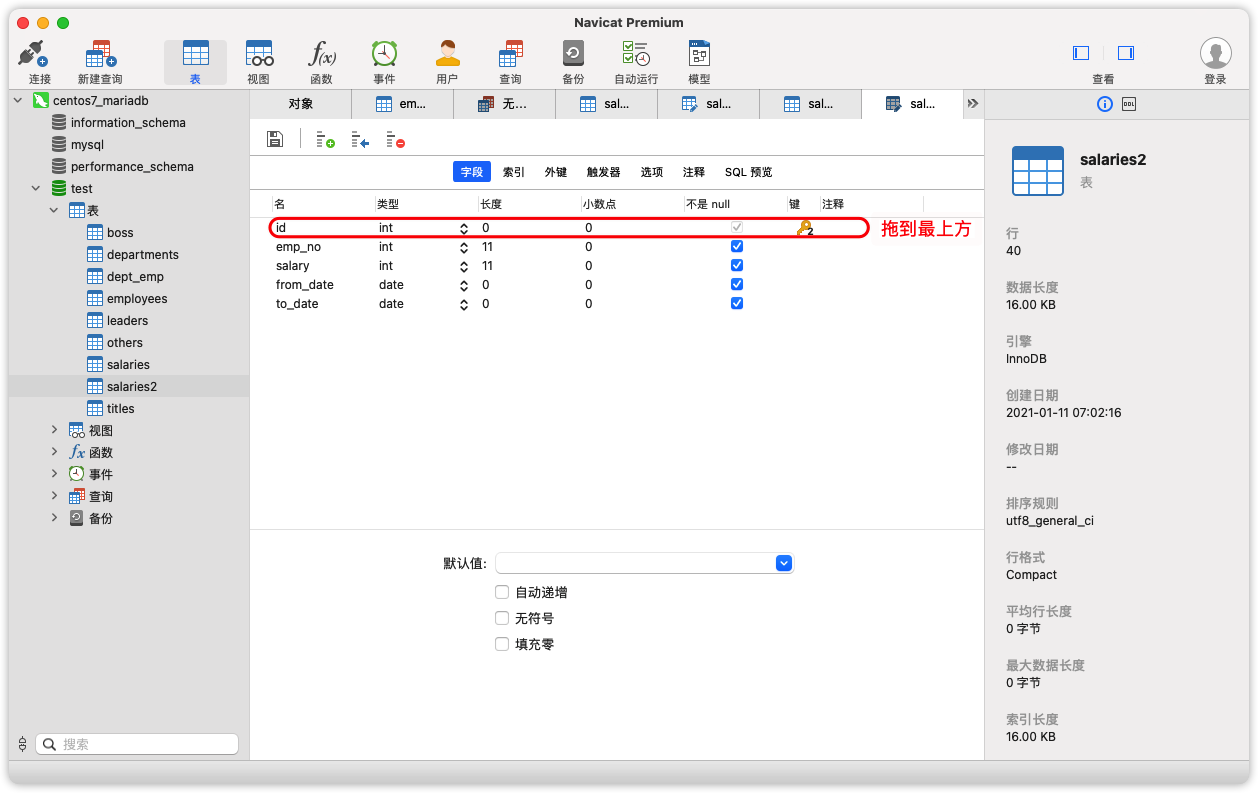
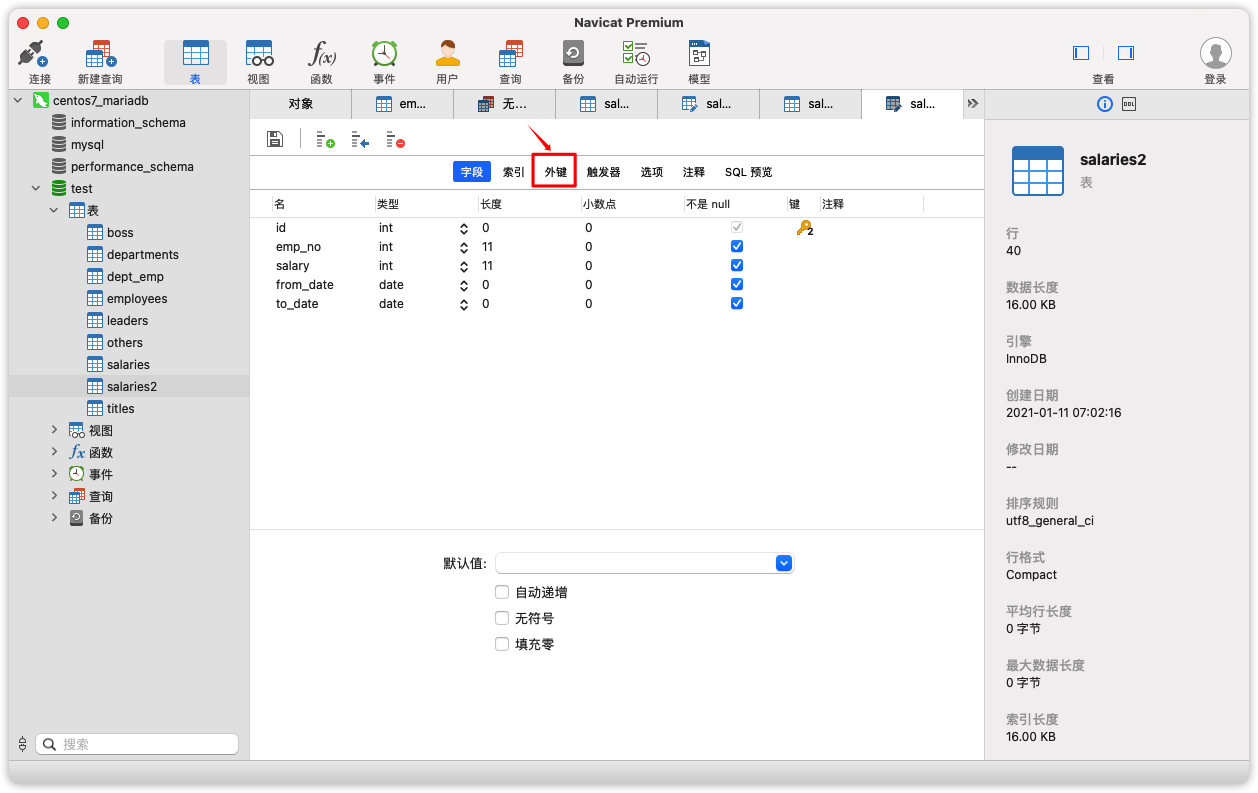
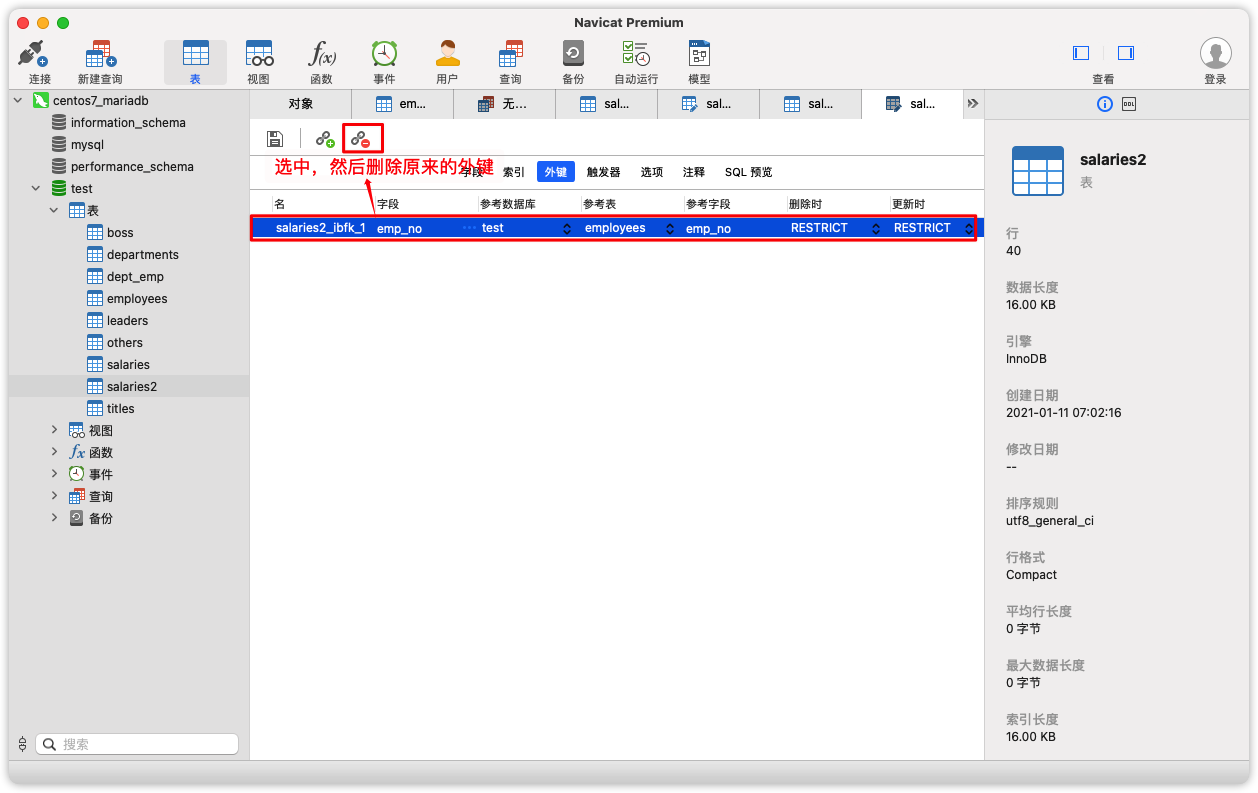
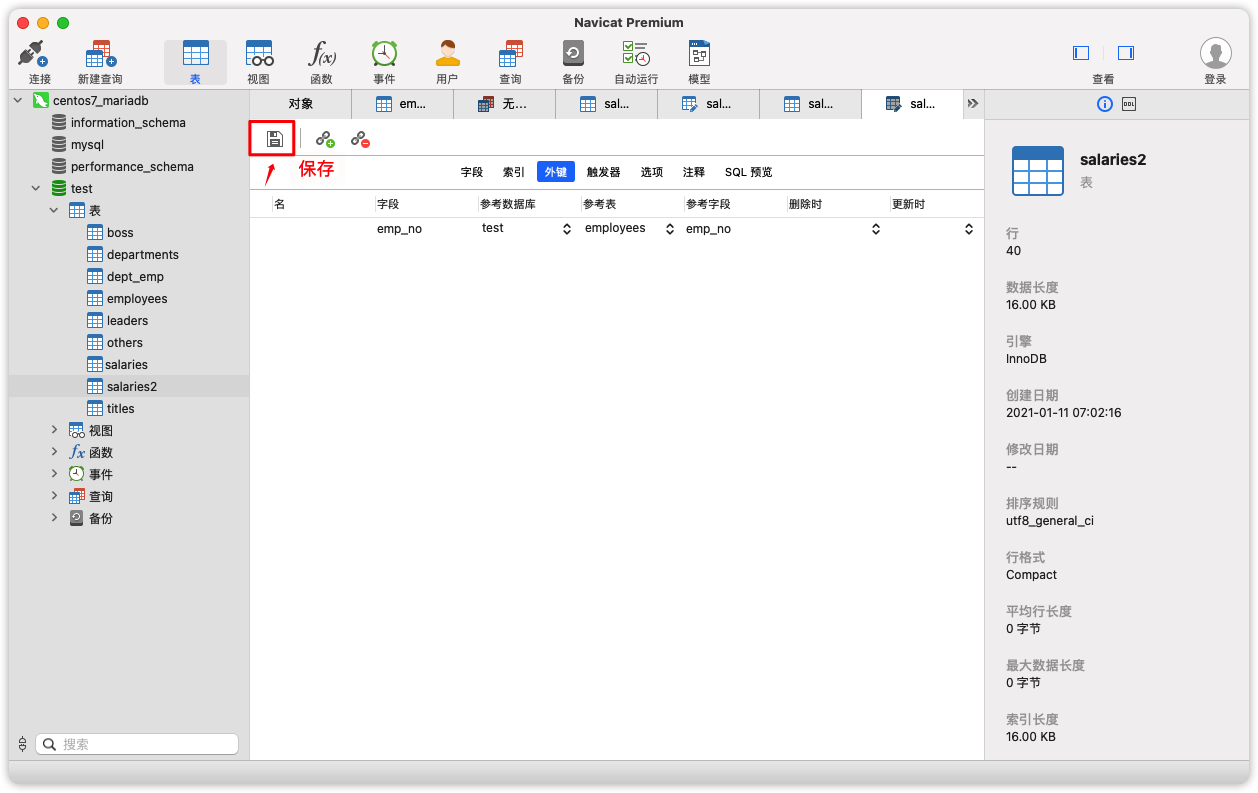
Django不能直接添加自己的2个字段的联合主键,我们手动为表创建一个自增id主键。操作顺序如下:
-
取消表所有联合主键,并删除所有外键约束后保存,成功再继续
-
为表增加一个id字段,自增、主键。保存,如果成功,它会自动填充数据
-
重建原来的外键约束即可
具体操作如下:


models构建模型
class Salary(models.Model): class Meta: db_table = 'salaries' id = models.AutoField(primary_key=True) # 如果觉得如果觉得salary_set不好用,可以使用related_name ↓ print(emgr.get(pk=10004).salary_set.all()) 可替换为 print(emgr.get(pk=10004).salaries.all()) # emp_no = models.ForeignKey(to='Employee', on_delete=models.CASCADE, null=False, db_column='emp_no', related_name='salaries') emp_no = models.ForeignKey(to='Employee', on_delete=models.CASCADE, null=False, db_column='emp_no') salary = models.IntegerField(null=False) from_date = models.DateField(null=False) to_date = models.DateField(null=False) def __repr__(self): return "<Salary: {} {} {}>".format(self.emp_no_id, self.from_date, self.salary) __str__ = __repr__
特殊属性
如果增加了外键约束后,Django会对一端和多端增加一些新的类属性
print(*Employee.__dict__.items(), sep=' ') # 一端,Employee类中多了一个类属性 # ('salary_set', <django.db.models.fields.related_descriptors.ReverseManyToOneDescriptor object at 0x000001303FB09B38>) print(*Salary.__dict__.items(), sep=' ') # 多端,Salary类中也多了一个类属性 # ('emp_no_id', <django.db.models.query_utils.DeferredAttribute object at 0x000001303FB09828>) # ('emp_no', <django.db.models.fields.related_descriptors.ForwardManyToOneDescriptor object at 0x000001303FB09860>) 指向Employee类的一个实例
从一端往多端查 <Employee_instance>.salary_set
从多端往一端查 <Salary_instance>.emp_no
注意: 多出来的2个属性,只有用到类似get方法取到具体对象时候才能用,如果是类似filter方法取到的集合对象不能用这2个属性
查询
一对多查询
print(emgr.get(pk=10004).salary_set.all()) # 查询工号为10004的员工的所有工资,因为有了salary_set的存在,所有可以直接在Employee表中完成查询 print(smgr.filter(emp_no=10004)) # 直接利用关连键emp_no查找 print(emgr.get(pk=10004).salaries.all()) # 利用related_name关联名字 print(emgr.get(pk=10004).salary_set.values('emp_no', 'from_date', 'salary')) # 投影(注意事项get方法,只有单个对象不是set集合才能用salary_set属性) print(smgr.filter(salary__gt=50000).values('emp_no').annotate(c=Count('id')).values('emp_no', 'c')) # 查询工资大于50000的员工 print(smgr.filter(salary__gt=50000).values('emp_no').annotate(c=Count('id')).values('emp_no').emp_no_id.values('name')) # 查询工资大于50000的工资员工名称 emp_nos = smgr.filter(salary__gt=50000).values('emp_no').distinct() print(emgr.filter(emp_no__in=[d.get('emp_no') for d in emp_nos]).values('first_name'))
如果觉得salary_set不好用,可以使用related_name
class Salary(models.Model): emp_no = models.ForeignKey('Employee', on_delete=models.CASCADE, null=False, db_column='emp_no', related_name='salaries') print(empmgr.get(pk=10004).salaries.all())
去重distinct
print(smgr.values('emp_no').distinct()) # 查询所有有薪水的工号(直接投影过滤,然后利用distinct去重)
raw的使用(不太推荐)
如果查询非常复杂,使用Django不方便,可以直接使用SQL语句
# 工资大于50000的所有员工的姓名 sql = """ SELECT DISTINCT employees.emp_no,employees.first_name FROM employees Join salaries ON employees.emp_no=salaries.emp_no WHERE salaries.salary > 50000 """ emps = emgr.raw(sql) print(type(emps)) print(list(emps)) # 员工工资记录里超过70000的人的工资和姓名 sql = """ select e.emp_no, e.first_name, e.last_name, s.salary from employees e join salaries s on e.emp_no = s.emp_no where s.salary > 70000 """ s = emgr.raw(sql) for x in s: # print(x.__dict__) print(x.name, x.salary)
还有一些多对多的查询,差不太多。