安装docx模块
pip3 install python-docx
读取word整文
from docx import Document doc=Document("./a.docx") for p in doc.paragraphs: print(p.text)
简单实例1
# word_1.py # 导入库 from docx import Document from docx.shared import Pt from docx.shared import Inches from docx.oxml.ns import qn # 新建空白文档 doc1 = Document() # 新增文档标题 doc1.add_heading('如何使用 Python 创建 Word',0) # 创建段落描述 doc1.add_paragraph('我们平时使用 Word 用来做文章的处理,可能没想过它可以用 Python 生成,下面我们就介绍具体如何操作……') # 创建一级标题 doc1.add_heading('安装 python-docx 库',1) # 创建段落描述 doc1.add_paragraph('现在开始我们来介绍如何安装 python-docx 库,具体需要以下两步操作:') # 创建二级标题 doc1.add_heading('第一步:安装 Python',2) # 保存文件 doc1.save('word1.docx')
查看效果
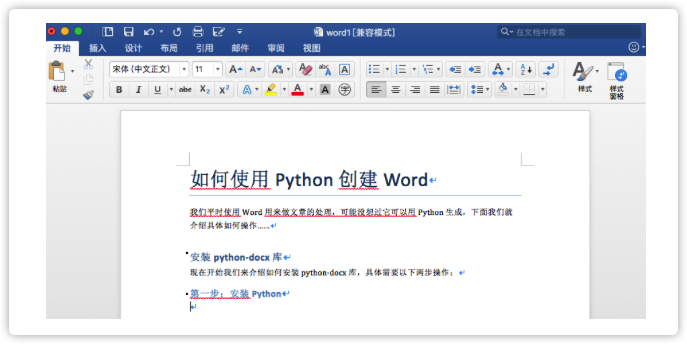
简单实例2
对“表扬信.docx”文档进行修改,需要修改的地方已在图中标记出。
- 第一个箭头处,首行缩进2字符
- 第二个箭头处,对段落进行左缩进2字符,并添加“向小z同学学习!”
- 第三个和第四个箭头处,进行右对齐,并右缩进2cm
- 赵东来,修改为小z
- 陆亦可,修改为大Z
- 她,修改为他
- 狗粮,修改为猫粮

代码如下
from docx import Document from docx.shared import Cm from docx.enum.text import WD_ALIGN_PARAGRAPH import re document=Document(r"g:CSPython Scripts表扬信.docx") # 首先对段落格式进行修改,docx默认标题也属于段落,因此“表扬信”是第一段 paragraphs=document.paragraphs paragraphs[2].paragraph_format.first_line_indent=Cm(0.74) paragraphs[3].paragraph_format.left_indent=Cm(0.74) paragraphs[4].paragraph_format.alignment=WD_ALIGN_PARAGRAPH.RIGHT paragraphs[4].paragraph_format.right_indent=Cm(2) paragraphs[5].paragraph_format.alignment=WD_ALIGN_PARAGRAPH.RIGHT paragraphs[5].paragraph_format.right_indent=Cm(2) # 对文本进行修改 # 修改第二段 paragraphs[1].text="小Z同学:" # 将第三段陆亦可替换为大Z,她替换为他。通过python的正则表达式,可以很简单地实现文本的替换和查找。 text=re.sub('陆亦可','大Z',paragraphs[2].text) text=re.sub('她','他',text) paragraphs[2].text=text # 在第四段后面加上 paragraphs[3].add_run("向小z同学学习!") # 修改表格里面的内容 tables=document.tables tables[0].cell(1,0).text="猫粮" tables[0].cell(2,0).text="猫粮" tables[0].cell(3,0).text="猫粮" # 插入一张图片,图片宽度设置为11.8cm document.add_picture('fun.jpg', width=Cm(11.8)) document.save()
修改后效果

简单实例3
from docx import Document import time import re # 读取模板文件 doc_zh = Document("/auto/data/综合平台应用层点检早报.docx") doc_wl = Document("/auto/data/物流平台应用层点检报告.docx") # 变量定义 today_time = time.strftime("%Y/%m/%d", time.localtime()) today_time2 = time.strftime("%Y%m%d", time.localtime()) # time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) file_name_zh = "综合平台应用层点检早报_" + today_time2 file_name_wl = "物流平台应用层点检报告_" + today_time2 # 修改word paragraphs_zh = doc_zh.paragraphs paragraphs_zh[6].text = re.sub('日期',today_time,paragraphs_zh[6].text) paragraphs_wl = doc_wl.paragraphs paragraphs_wl[11].text = re.sub('日期',today_time,paragraphs_wl[11].text) # 保存文件 doc_zh.save("/auto/data_finish/" + file_name_zh + ".docx") doc_wl.save("/auto/data_finish/" + file_name_wl + ".docx") print("word_auto finish") # for p in doc.paragraphs: # print(p.text)