大数定律
当数据量很大的时候可以用频率表示概率,
在试验不变的条件下,重复试验多次,随机事件的频率近似于它的概率。偶然中包含着某种必然。
中心极限定理
样本的平均值约等于总体的平均值。
不管总体是什么分布,任意一个总体的样本平均值都会围绕在总体的整体平均值周围,并且呈正态分布。
除以n和n-1 中心极限定理
一.中心极限定理
下图形象的说明了中心极限定理
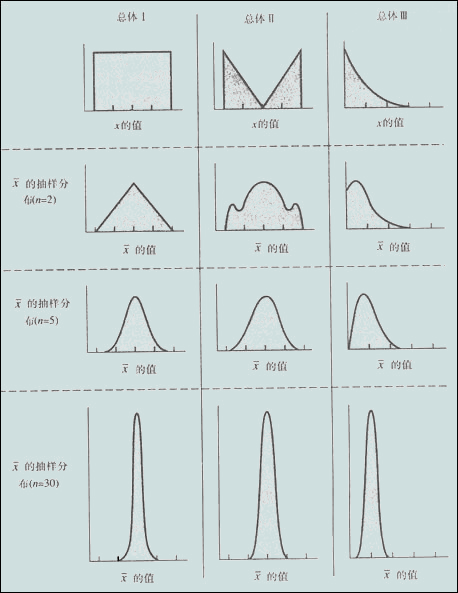
当样本量N逐渐趋于无穷大时,N个抽样样本的均值的频数逐渐趋于正态分布,其对原总体的分布不做任何要求,意味着无论总体是什么分布,其抽样样本的均值的频数的分布都随着抽样数的增多而趋于正态分布,如上图,这个正态分布的u会越来越逼近总体均值,并且其方差满足a^2/n,a为总体的标准差,注意抽样样本要多次抽取,一个容量为N的抽样样本是无法构成分布的。
二.中心极限定理和大数定律的区别
下面援引一段知乎上的回答:https://www.zhihu.com/question/48256489/answer/110106016
大数定律是说,n只要越来越大,我把这n个独立同分布的数加起来去除以n得到的这个样本均值(也是一个随机变量)会依概率收敛到真值u,但是样本均值的分布是怎样的我们不知道。
中心极限定理是说,n只要越来越大,这n个数的样本均值会趋近于正态分布,并且这个正态分布以u为均值,sigma^2/n为方差。
综上所述,这两个定律都是在说样本均值性质。随着n增大,大数定律说样本均值几乎必然等于均值。中心极限定律说,他越来越趋近于正态分布。并且这个正态分布的方差越来越小。直观上来讲,想到大数定律的时候,你脑海里浮现的应该是一个样本,而想到中心极限定理的时候脑海里应该浮现出很多个样本。
中心极限定理是说一定条件下,当变量的个数趋向于无穷大时,变量总体趋向于正态分布。而大数定律是当重复独立试验次数趋于无穷大时,平均值(包括频率)具有稳定性。两者是完全不同的
最大似然估计: 是利用已知的样本的结果,在使用某个模型的基础上,反推最有可能导致这样结果的模型参数值。
举个通俗的例子:假设一个袋子装有白球与红球,比例未知,现在抽取10次(每次抽完都放回,保证事件独立性),假设抽到了7次白球和3次红球,在此数据样本条件下,可以采用最大似然估计法求解袋子中白球的比例(最大似然估计是一种“模型已定,参数未知”的方法)。当然,这种数据情况下很明显,白球的比例是70%。
说的通俗一点啊,最大似然估计,就是利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值(模型已知,参数未知)。
基本思想
当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使得从模型中抽取该n组样本观测值的概率最大,而不是像最小二乘估计法旨在得到使得模型能最好地拟合样本数据的参数估计量。
似然函数
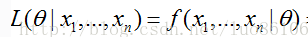
对数似然函数
当样本为独立同分布时,似然函数可简写为L(α)=Πp(xi;α),牵涉到乘法不好往下处理,于是对其取对数研究,得到对数似然函数l(α)=ln L(α)=Σln p(xi;α)
求解极大似然
同样使用多元函数求极值的方法。
例如:一个麻袋里有白球与黑球,但是我不知道它们之间的比例,那我就有放回的抽取10次,结果我发现我抽到了8次黑球2次白球,我要求最有可能的黑白球之间的比例时,就采取最大似然估计法: 我假设我抽到黑球的概率为p,那得出8次黑球2次白球这个结果的概率为:
P(黑=8)=p^8*(1-p)^2,
现在我想要得出p是多少啊,很简单,使得P(黑=8)最大的p就是我要求的结果,接下来求导的的过程就是求极值的过程啦。
可能你会有疑问,为什么要ln一下呢,这是因为ln把乘法变成加法了,且不会改变极值的位置(单调性保持一致嘛)这样求导会方便很多~
同样,这样一道题:设总体X 的概率密度为
已知: X1,X2..Xn是样本观测值,
已知: X1,X2..Xn是样本观测值,
求:θ的极大似然估计
这也一样啊,要得到 X1,X2..Xn这样一组样本观测值的概率是
这也一样啊,要得到 X1,X2..Xn这样一组样本观测值的概率是
P{x1=X1,x2=X2,...xn=Xn}= f(X1,θ)f(X2,θ)…f(Xn,θ)
然后我们就求使得P最大的θ就好啦,一样是求极值的过程,不再赘述。