今天完成spark实验7:Spark机器学习库MLlib编程实践。
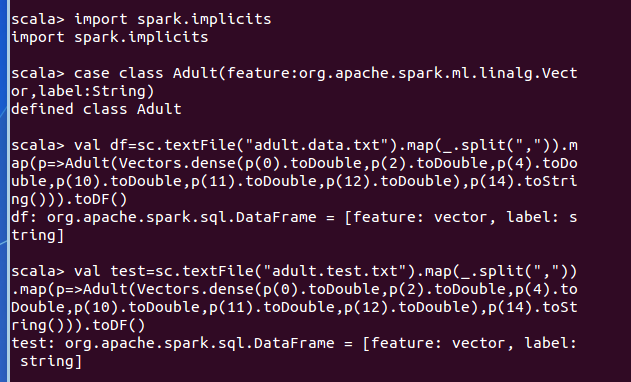
1、数据导入
从文件中导入数据,并转化为 DataFrame。
//导入需要的包
import org.apache.spark.ml.feature.PCA
import org.apache.spark.sql.Row
import org.apache.spark.ml.linalg.{Vector,Vectors}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.{Pipeline,PipelineModel}
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer,HashingTF, Tokenizer}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.classification.LogisticRegressionModel
import org.apache.spark.ml.classification.{BinaryLogisticRegressionSummary, LogisticRegression}
import org.apache.spark.sql.functions;
import org.apache.spark.sql.functions;
//获取训练集测试集(需要对测试集进行一下处理,adult.data.txt 的标签是>50K 和<=50K, 而 adult.test.txt 的标签是>50K.和<=50K.,这里是把 adult.test.txt 标签中的“.”去掉了)
2、进行主成分分析(PCA)
对 6 个连续型的数值型变量进行主成分分析。PCA(主成分分析)是通过正交变换把一组相关变量的观测值转化成一组线性无关的变量值,即主成分的一种方法。PCA 通过使用 主成分把特征向量投影到低维空间,实现对特征向量的降维。请通过 setK()方法将主成分数量设置为 3,把连续型的特征向量转化成一个3维的主成分。
构建 PCA 模型,并通过训练集进行主成分分解,然后分别应用到训练集和测试集
![]()
报错:
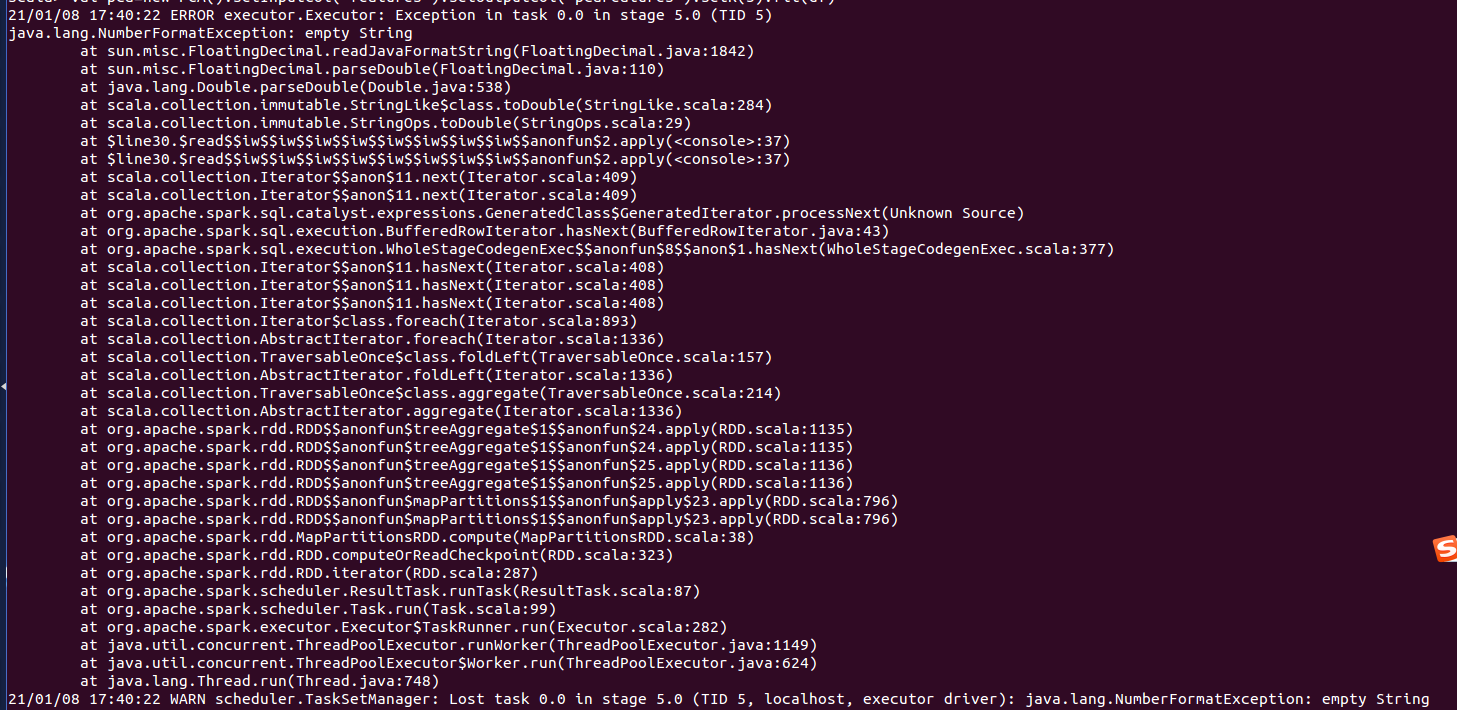
未解决,求教。


3、训练分类模型并预测居民收入
在主成分分析的基础上,采用逻辑斯蒂回归,或者决策树模型预测居民收入是否超过 50K;对 Test 数据集进行验证。
训练逻辑斯蒂回归模型,并进行测试,得到预测准确率
scala> val labelIndexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel").fit(result)
labelIndexer: org.apache.spark.ml.feature.StringIndexerModel = strIdx_6721796011c5
scala> labelIndexer.labels.foreach(println)
<=50K
>50K
scala> val featureIndexer = new VectorIndexer().setInputCol("pcaFeatures").setOutputCol("indexedFeatures").fit(result) featureIndexer: org.apache.spark.ml.feature.VectorIndexerModel = vecIdx_7b6672933fc3
scala> println(featureIndexer.numFeatures)
3
scala> val labelConverter = new IndexToString().setInputCol("prediction").setOutputCol("predictedLabel").setLabels(labelIndexer. labels)
labelConverter: org.apache.spark.ml.feature.IndexToString = idxToStr_d0c9321aaaa9
scala> val lr = new LogisticRegression().setLabelCol("indexedLabel").setFeaturesCol("indexedFeatures").setMaxIter( 100)
lr: org.apache.spark.ml.classification.LogisticRegression = logreg_06812b41b118
scala> val lrPipeline = new Pipeline().setStages(Array(labelIndexer, featureIndexer, lr, labelConverter))
lrPipeline: org.apache.spark.ml.Pipeline = pipeline_b6b87b6e8cd5
scala> val lrPipelineModel = lrPipeline.fit(result)
lrPipelineModel: org.apache.spark.ml.PipelineModel = pipeline_b6b87b6e8cd5
scala> val lrModel = lrPipelineModel.stages(2).asInstanceOf[LogisticRegressionModel]
lrModel: org.apache.spark.ml.classification.LogisticRegressionModel = logreg_06812b41b118
scala> println("Coefficients: " + lrModel.coefficientMatrix+"Intercept: "+lrModel.interceptVector+"numClasses: "+lrModel.numClasses+"numFeatures: "+lrModel.numFeatures)
Coefficients: -1.9828586428133616E-7 -3.5090924715811705E-4 -8.451506276498941E-4 Intercept: [-1.4525982557843347]numClasses: 2numFeatures: 3
scala> val lrPredictions = lrPipelineModel.transform(testdata)
lrPredictions: org.apache.spark.sql.DataFrame = [features: vector, label: string ... 7 more fields]
scala> val evaluator = new MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction")
evaluator: org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator = mcEval_38ac5c14fa2a
scala> val lrAccuracy = evaluator.evaluate(lrPredictions)
lrAccuracy: Double = 0.7764235163053484
scala> println("Test Error = " + (1.0 - lrAccuracy))
Test Error = 0.22357648369465155
4、超参数调优
利用 CrossValidator 确定最优的参数,包括最优主成分PCA 的维数、分类器自身的参数等。
scala> val pca = new PCA().setInputCol("features").setOutputCol("pcaFeatures")
pca: org.apache.spark.ml.feature.PCA = pca_b11b53a1002b
scala> val labelIndexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel").fit(df)
labelIndexer: org.apache.spark.ml.feature.StringIndexerModel = strIdx_f2a42d5e19c9
scala> val featureIndexer = new VectorIndexer().setInputCol("pcaFeatures").setOutputCol("indexedFeatures") featureIndexer: org.apache.spark.ml.feature.VectorIndexer = vecIdx_0f9f0344fcfd
scala> val labelConverter = new IndexToString().setInputCol("prediction").setOutputCol("predictedLabel").setLabels(labelIndexer.l abels)
labelConverter: org.apache.spark.ml.feature.IndexToString = idxToStr_74967420c4ea
scala> val lr = new LogisticRegression().setLabelCol("indexedLabel").setFeaturesCol("indexedFeatures").setMaxIter(1 00)
lr: org.apache.spark.ml.classification.LogisticRegression = logreg_3a643c15517d
scala> val lrPipeline = new Pipeline().setStages(Array(pca, labelIndexer, featureIndexer, lr, labelConverter))
lrPipeline: org.apache.spark.ml.Pipeline = pipeline_4ff414fedeed
scala> val paramGrid = new ParamGridBuilder().addGrid(pca.k, Array(1,2,3,4,5,6)).addGrid(lr.elasticNetParam, Array(0.2,0.8)).addGrid(lr.regParam, Array(0.01, 0.1, 0.5)).build()
paramGrid: Array[org.apache.spark.ml.param.ParamMap] = Array({ logreg_3a643c15517d-elasticNetParam: 0.2,pca_b11b53a1002b-k: 1, logreg_3a643c15517d-regParam: 0.01 }, { logreg_3a643c15517d-elasticNetParam: 0.2, pca_b11b53a1002b-k: 2, logreg_3a643c15517d-regParam: 0.01 }, { logreg_3a643c15517d-elasticNetParam: 0.2, pca_b11b53a1002b-k: 3, logreg_3a643c15517d-regParam: 0.01 }, { logreg_3a643c15517d-elasticNetParam: 0.2, pca_b11b53a1002b-k: 4, logreg_3a643c15517d-regParam: 0.01 }, { logreg_3a643c15517d-elasticNetParam: 0.2, pca_b11b53a1002b-k: 5, logreg_3a643c15517d-regParam: 0.01 }, { logreg_3a643c15517d-elasticNetParam: 0.2, pca_b11b53a1002b-k: 6, logreg_3a643c15517d-regParam: 0.01 }, { logreg_3a643c15517d-elasticNetParam: 0.2, pca_b11b53a1002...
scala> val cv = new CrossValidator().setEstimator(lrPipeline).setEvaluator(new MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction")).se tEstimatorParamMaps(paramGrid).setNumFolds(3)
cv: org.apache.spark.ml.tuning.CrossValidator = cv_ae1c8fdde36b
scala> val cvModel = cv.fit(df)
cvModel: org.apache.spark.ml.tuning.CrossValidatorModel = cv_ae1c8fdde36b
scala> val lrPredictions=cvModel.transform(test)
lrPredictions: org.apache.spark.sql.DataFrame = [features: vector, label: string ... 7 more fields]
scala> val evaluator = new MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction")
evaluator: org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator = mcEval_c6a4b78effe0
scala> val lrAccuracy = evaluator.evaluate(lrPredictions)
lrAccuracy: Double = 0.7833268290041506
scala> println("准确率为"+lrAccuracy)
准确率为 0.7833268290041506
scala> val bestModel= cvModel.bestModel.asInstanceOf[PipelineModel]
bestModel: org.apache.spark.ml.PipelineModel = pipeline_4ff414fedeed
scala> val lrModel = bestModel.stages(3).asInstanceOf[LogisticRegressionModel]
lrModel: org.apache.spark.ml.classification.LogisticRegressionModel = logreg_3a643c15517d
scala> println("Coefficients: " + lrModel.coefficientMatrix + "Intercept: "+lrModel.interceptVector+ "numClasses: "+lrModel.numClasses+"numFeatures: "+lrModel.numFeatures)
Coefficients: -1.5003517160303808E-7 -1.6893365468787863E-4 ... (6 total)Intercept: [-7.459195847829245]numClasses: 2numFeatures: 6
scala> val pcaModel = bestModel.stages(0).asInstanceOf[PCAModel]
pcaModel: org.apache.spark.ml.feature.PCAModel = pca_b11b53a1002b
scala> println("Primary Component: " + pcaModel.pc)
Primary Component: -9.905077142269292E-6 -1.435140700776355E-4 ... (6 total)
0.9999999987209459 3.0433787125958012E-5 ...
-1.0528384042028638E-6 -4.2722845240104086E-5 ...
3.036788110999389E-5 -0.9999984834627625 ...
-3.9138987702868906E-5 0.0017298954619051868 ...
-2.1955537150508903E-6 -1.3109584368381985E-4 ...
可以看出,PCA 最优的维数是 6。