背景:一些场景下是需要用到分组数据的,比如刚工作那会儿,有一次的需求是统计某个网点的各个职员关于一项任务的推广情况。又比如我要统计每个部门的人数有多少。这些都需要用到分组数据,分组数据就要使用group by
那group by 用法简单来说可以分为两种,一种是直接分组不添加限制条件,第二种就是加上限制条件
测试数据如下:官方给的一份测试数据
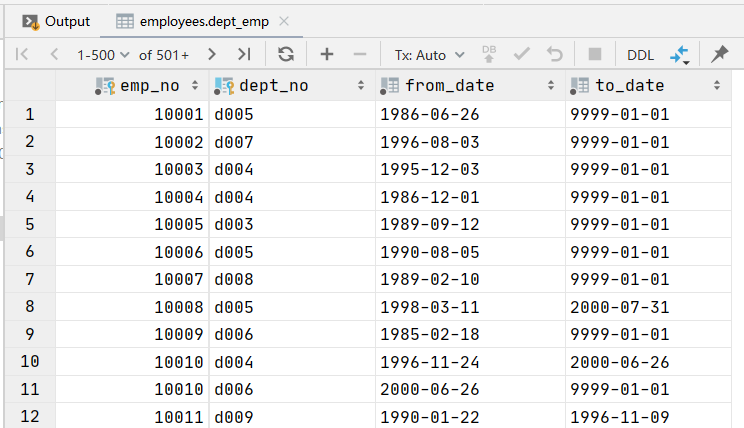
查询每个部门的人数
--统计人数要用count()函数 ,查询每个部门的人数就要以部门作为分组对象,将部门编号放在group by后面
select count(*) from dept_emp group by dept_no;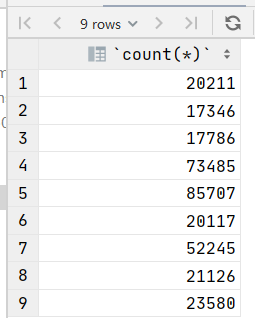
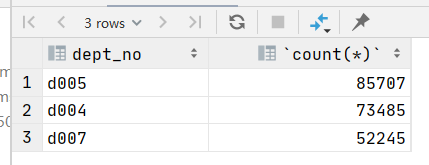
如果我要查询部门人数大于3万的各部门的人数。这时对部门增加了限制,就要用到限制条件,此时要用having 而不是where。也就是说与group by搭配使用的时having不是group by
-- 增加限制条件时,having要放在分组后面,部门人数大于3万的表达式为count(dept_no)>30000
select count(*) from dept_emp group by dept_no having count(dept_no)>30000;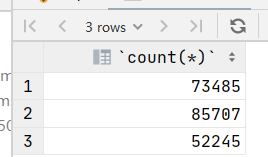
使用order by分组时需要注意以下几点:
- GROUP BY 子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。
- 如果在 GROUP BY 子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
- GROUP BY 子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在 SELECT 中使用表达式,则必须在GROUP BY 子句中指定相同的表达式。不能使用别名。
- 除聚集计算语句外, SELECT 语句中的每个列都必须在 GROUP BY 子句中给出。
- 如果分组列中具有 NULL 值,则 NULL 将作为一个分组返回。如果列中有多行 NULL 值,它们将分为一组。
- GROUP BY 子句必须出现在 WHERE 子句之后, ORDER BY 子句之前。
与group by配合的关键字还有一个 with rollup ,意思是汇总,将所有分组的数据汇总在一起
比如:和第一个例子比较,发现多了第十行,第十行就是汇总的数据
select dept_no,count(*) from dept_emp group by dept_no with rollup ;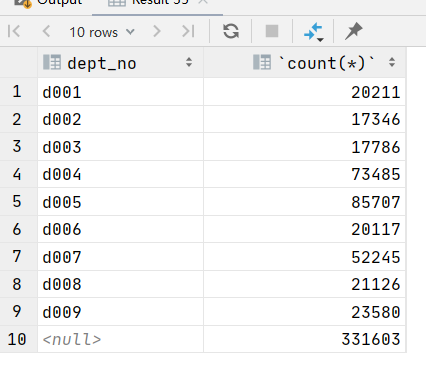
如果分组和排序一起用的时候怎么用呢,比如在第二例子上进行修改。如果我要查询部门人数大于3万的各部门的人数,结果降序排列。
select dept_no, count(*) from dept_emp group by dept_no having count(dept_no)>30000 order by count(dept_no) desc ;