过拟合现象,即模型的训练误差远⼩于它在测试集上的误差。虽然增⼤训练数据集可能会减轻过拟合,但是获取额外的训练数据往往代价⾼昂。本节介绍应对过拟合问题的常⽤⽅法:权重衰减(weight decay)。
一、方法
权重衰减等价于 范数正则化(regularization)。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较⼩,是应对过拟合的常⽤⼿段。我们先描述 范数正则化,再解释它为何⼜称权重衰减。
范数正则化在模型原损失函数基础上添加 范数惩罚项,从⽽得到训练所需要最⼩化的函数。 范数惩罚项指的是模型权重参数每个元素的平⽅和与⼀个正的常数的乘积。以3.1节(线性回归)中的线性回归损失函数:
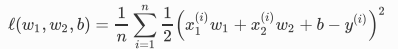
为例,其中 (w_1,W_2) 是权重参数, (b) 是偏差参数,样本 (x_1^{i},x_2^{i}) 的输⼊为 ,标签为 (y^{i}),样本数为 (n) 。将权重参数⽤向量 (w = [w1,w2]) 表示,带有 (L_2) 范数惩罚项的新损失函数为
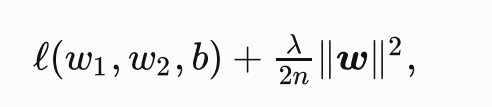
二、实现
( 一 )导包
%matplotlib inline
import torch
import torch.nn as nn
import numpy as np
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
n_train, n_test, num_inputs = 20,100,200
true_w, true_b = torch.ones(num_inputs,1) * 0.01,0.05
features = torch.randn((n_train + n_test, num_inputs))
labels = torch.matmul(features,true_w) + true_b
labels += torch.tensor(np.random.normal(0,0.01,size=lables.size()),dtype=torch.float)
train_features, tensorst_features = featuresatures[:n_train,:],features[n_train:, :]
train_labels, test_labels = labels[:n_train],labels[n_train:]
( 二 )定义随机初始化模型参数的函数。该函数为每个参数都附上梯度。