上周简要介绍了一下AlexNet,这周来聊一聊RCNN。
2013年提出的RCNN结合了启发式的区域推荐(Select Search)、CNN特征提取器(AlexNet)和传统的图像分类器(SVM),在07-12年的VOC数据集上以压倒性的优势将旧霸主DPM远远甩在身后,详细数据可见原文(https://arxiv.org/abs/1311.2524)。
一、模型架构
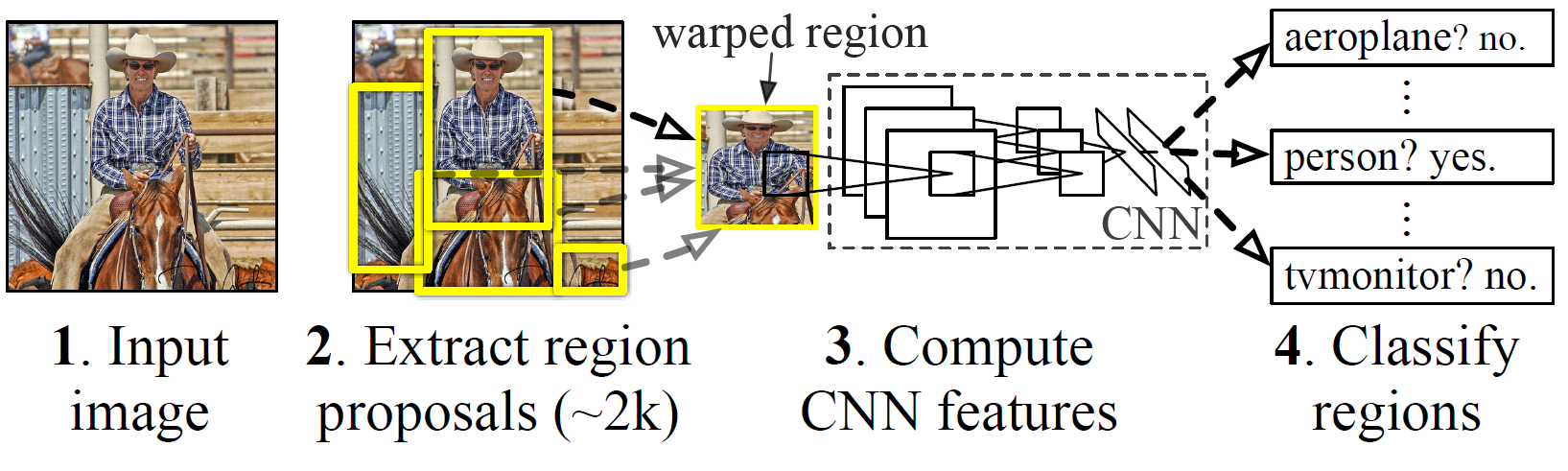
如上图,RCNN的结构大致可以分为三个部分:区域推荐(Select Search)、特征提取(AlexNet)、图像分类器(SVM)。
区域推荐
RCNN中的区域推荐使用的是selsect search,其核心思想是,将图像划分成许多小区域(图像分割算法),然后通过相邻小区域之间的“相似性”,将相似度较高的区域合并成一个大区域-region proposal(可以类比机器学习中的聚类算法),然后将该大区域用作后续的特征提取。
此处使用的图像分割,使用的是经典的Felzenszwalb算法(应该是2004年提出来的,GithHub上有相关的实现代码:https://github.com/AlpacaDB/selectivesearch),这里先挖个坑,因为我自己也没有细看Felzenszwalb算法的实现源码,后续希望自己能补上吧(传说中的迭代学习啊~)。
区域间的“相似性”则是通过将原始图像使用不同的编码方式(RGB、Lab、HSV等等)的通道值Concat后,选择性的将部分通道值合并,最后映射到八通道的颜色空间,然后在这八通道空间上计算不同区域之间的距离(纹理距离,颜色距离等)。
最后将上述计算出的区域距离与一定的合并条件(合并后的区域的形状要合理)结合,并计算加权距离,选取加权值在一定范围内的区域进行合并。在合并的同时会对合并后的区域进行打分(合并程度低的,以及合并时出现次数多的区域,得分会较高),最后根据需求,选取适当分数的合并区域用于后续的特征提取。(我这里讲的比较模糊,后续带我有空把相关原理和代码细看之后再补上吧/(ㄒoㄒ)/~~处处给自己挖坑╯︿╰)
特征提取
特征提取这块,用到的就是我们耳熟能详的AlexNet(后期也使用过VGG16),这也是我在上一篇博客中介绍AlexNet的原因。
此处将区域推荐网络生成的region proposal提取出来,将宽/高值缩放到指定尺寸(不固定宽高比,也就是说在缩放之后图像很可能会产生变形和扭曲),最后送到AlexNet中提取特征。
这里的AlexNet使用Caffe CNN库进行了预训练,之后使用提取出的region proposal进行Fine-Tune。
图像分类器
使用SVM对提取出的特征进行分类,为每一个类别训练一个二值分类器(分类器输出0/1,表示是否属于这个类)。在训练分类器时,将真值框作为正类模型,将IOU在0.3以下的region proposal作为负例。
SVM(支持向量机)是一种二分类模型,它是基于高维数据比低维数据更易线性可分的原理,使用核方法将原始数据映射到高维空间,然后求解在高维空间的分离超平面(这里给自己挖个坑,以后有机会要把SVM具体的公式推导和代码写一写 ●ˇ∀ˇ●)。
最后的最后,模型对SVM分类后的区域进行了边框回归,使预测区域更准确。
二、模型总结
创新:
1、采用了CNN作为特征提取器,将早期的“人工提取特征”变成模型“自动提取特征”,极大的解放了研究人员和工程师,使得人们可以把精力专注于设计更加优秀的模型,而不用为大量的特征提取工作烦恼。
2、引入了在大样本上预训练模型,然后在小样本上进行Fine-Tune的模式,也就是我们耳熟能详的“迁移学习”,使得模型在数据量不足的情况下也能够有很好的泛化性能(迁移学习,我的最爱啊~(* ̄0 ̄)ノ)
缺点:
1、每个region proposal都要进行卷积计算,导致特征的多次重复提取,浪费计算资源,降低计算速度(FastRCNN改成在CNN特征图生成之后再进行区域选择,改进了此问题)
2、select search需要事先提取多个region proposal,对存储空间需求大(FasterRCNN中使用RPN改进了此问题)
3、RCNN对region proposal输入CNN之前进行了缩放,使图像发生了变形,不利于特征的提取(FastRCNN中使用ROI改进了此问题)