基于IT 健康分析的智能运维新趋势
随着 IT 技术的发展与普及,各类信息化系统正日趋成为工业制造领域不可或缺的基础能力,推动着业务部门、工厂产线的高效运行,因此对信息化系统的高质量运维,是工业制造企业保持高效生产的关键。传统上,企业 IT 运维是通过系统指标的变化,例如处理器 / 内存使用率、磁盘吞吐量等,由人工判断系统是否存在问题与隐患。随着企业信息化系统日趋多样, 加之软硬件平台不再紧密耦合,单一系统可能存在多个厂商的硬件与服务,因此信息化系统的复杂程度正呈指数化增长,给工业制造企业的 IT 部门带来了巨大的挑战。
虽然许多企业已经部署了自动化的运维监控系统,并基于专家规则对异常指标进行告警,但这种借助经验构建的系统,无法让运维人员通过告警信息即时进行原因分析。而通过专家后期采集、分析整套系统的数据,又往往需要很长时间。同时,由于技术能力的差异,专家对监控指标的分析结论也会有差别, 为系统异常的及时甄别与处理埋下隐患。
在英特尔与南京基石数据技术有限责任公司(以下简称 “基石数据”)看来,要根本解决这一问题,需要从运维生态入手,
针对设备日志、运行数据等时序数据建模,建立 “IT 健康分析” 系统来发现存在的系统隐患,进而推送给运维部门或者专门的优化部门进行优化改进,并能够通过经验积累实现自我优化。
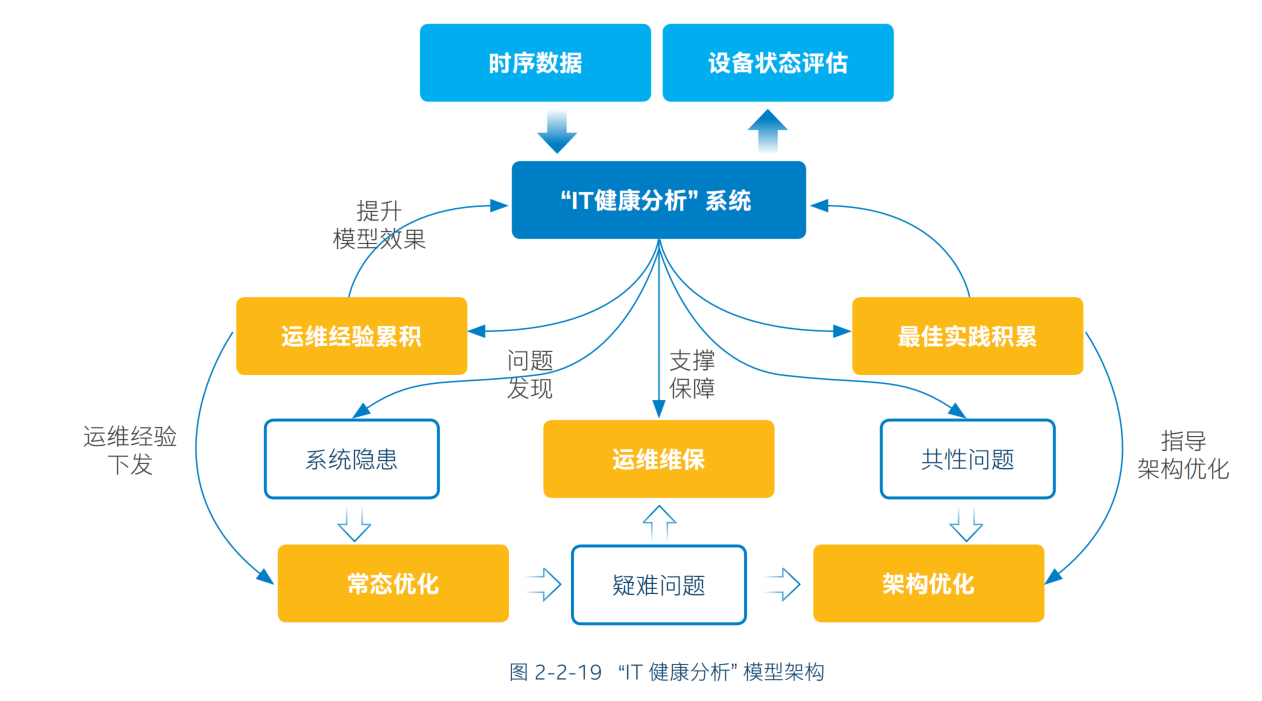
如图 2-2-19 所示,借助基于时序数据构建的 “IT 健康分析”系统,企业一方面可以及时发现系统隐患,并通过常态优化或架构优化来予以修复;另一方面,模型也可对信息化系统的运维维保进行支撑,并通过运维经验和最佳实践的积累,来不断自我完善和优化。而要构建这样的系统,工业制造企业需要解决三个方面的问题。
- 引入高精度、高效率的智能分析模型作为系统核心,减少运维系统对人力,尤其是对专家的依赖;
- 为智能分析模型提供强有力的硬件基础设施,特别是高性能计算力的输入;
- 以合理的系统架构设计,保证充分的计算、分析能力能 “ 下放” 到运维一线。
基于以上分析,英特尔与基石数据首先引入 AI、大数据等技术, 通过机器学习、深度学习方法来建立智能模型,对复杂的时序指标数据进行分析并判别系统的运行状态。基于海量数据训练出的智能分析模型,不仅有着更胜于专家系统的准确率和效率, 更能大幅减少运维工作所需的人力,提高运维效率。一项统计数据表明,通过智能模型来预测系统状态变化,工作可以在秒级内完成,且分析准确率超过 98%。
为了使 “IT 健康分析” 系统和智能分析模型发挥更大效能,英特尔为之提供了多种先进软硬件产品与框架,为智能分析模型的训练推理过程提供强劲算力和工具。同时,新方案还引入了“云边协同” 的新架构,一方面,通过就近部署智能分析模型, 提升运维能力的实时性;另一方面,利用云端的专家知识库, 对发现的问题进行闭环管理,展开问题溯源与优化方案编制, 并将优化方案反馈回现场。
现在,这一全新的系统方案正广泛地在 “ 数据库健康状态评估”、“网络安全风险预警” 等实际场景中开展实践,并取得了良好的应用效果。
基石数据以机器健康模型,提升企业数据库运维效率
■ 项目背景
作为 IT 系统的核心组件之一,数据库的健康对于企业信息化系统的高效运行至关重要。传统上,运维工程师需要通过数据库管理系统 (Database Management System,DBMS)等工具,以人工方式对数据库进行统一的管理、控制和调配。但这种方式既繁琐又缺乏效率,尤其当企业信息化系统变得更为复杂,且与业务紧密关联时,配置优化效果将直接影响企业生产的效率。以产线自动化监控系统为例,通过高清摄像头采集的产线图像需要在数据库中暂存后再送至后端处理,在这种高吞吐量的场景中,如何设置数据库的缓存机制,如何在阻塞发生前启动相关 Session 的处理等,都会直接影响该产线的生产效率和产品品质。

基石数据推出的机器健康模型能有效应对以上挑战。这一模型利用数据库丰富的时序化监控数据,例如连接状态、处理器 / 内存使用率、磁盘读写时延、缓存大小、等待时间等,通过机器学习或深度学习的方法进行训练,并得到合理的数据库健康预测得分,进而帮助运维人员制定相应策略。
同时,这一健康预测方法,也是英特尔与基石数据合作开展的 “IT 健康分析” 系统在数据库智能运维领域的重要落地,部署在边缘的数据库健康预测系统所得到的预测结果,可以与云端的 D-Smart 运维知识自动化系统形成交互,对方案实施迭代优化。
■ 基石数据机器健康模型方案描述
基石数据机器健康模型方案基本架构如图 2-2-20 所示,贴近电网管线、电力生产等一线部署的机器健康模型,由数据预处理、模型训练 & 验证以及预测系统几部分组成,可以使用训练数据,通过特定算法训练模型,并利用测试数据对模型效果进行验证,迭代优化模型。最终的预测结果将传送到位于云端的 D-Smart 运维知识库,并可以对接内外部专家系统、厂商支撑、系统优化团队以及专门的 IT 系统健康管理团队,根据预测结果对数据库状况进行分析,开展进一步优化。
机器健康模型会对数据库当前的健康状态进行评价打分,并预测未来一段时间内的健康得分。因此如图2-2-21所示,模型的输入数据X包括了会话连接状态、处理器/内存使用率、磁盘读写时延、缓存大小等具有时序特征的数据库监控数据,输出Y则是数据库的健康得分,包括当前分数和未来时间的预测分。分数为百分制,如96分。模型需要通过健康得分(标签)来调整优化模型的参数,因此模型采用的是监督学习的方法。

模型首先从一线数据中获得供训练和测试使用的数据集,这些数据已经预先打好标签,并按照 80%:20% 的训练与测试比例进行划分。如图2-2-22所示,方案中针对数据库运维的健康模型使用了7类68个维度的指标,并预先设定了各个指标的健康度得分。由此,系统可以得到一组以时间序列排列的数据库健康得分数据。

在获取数据集之后,系统首先进行缺失值处理。数据集中的缺失值会带来噪声,从而对最后的预测结果造成偏差,因此方案采用了平均值填充或上下值填充的方式来予以处理。前者是将均值填入缺失值,后者是将前一个值或后一个值填入缺失值, 不同缺失值填充方法会对预测结果造成差异,一般建议每行数据如果缺失率小于0.6则填充平均值。示例代码如下:

特征选择是数据预处理环节中的重要步骤,进行合理的特征选择可以降低维度,查找和选择最有用的特征,提高模型的可解释性。另外,特征选择还能减少不必要的计算量,加快训练速度,同时降低模型方差,提高泛化效果。
在特征选择过程中,首先需要查找高度相关的特征,在机器学习方法中,这类特征可能会导致模型在测试集上的泛化能力下降。其次是计算特征的重要性。示例代码如下:

在使用梯度下降一类的机器算法中,如果能保证不同特征的取值在相同或相近的范围内,比如都处于 0-1 之间,那么梯度下降算法会收敛的很快。因此在数据预处理的最后,方案对数据进行了特征缩放处理。
经过预处理的数据集需要选择合适的算法进行训练,方案根据数据库时序数据的特点选择多种算法进行了比较,包括支持向量回归(Support Vactor Regression,SVR)算法、RNN- LSTM 算法,GBDT 算法、XGBoost 算法以及随机森林算法等。通过验证比较表明,在时序化的数据库健康预测环境中, XGBoost 以及随机森林算法的预测准确度和效率较高。
在上述过程中,机器健康模型选择了英特尔® 至强® 可扩展处理器来为整个训练推理过程提供强劲算力。这一系列的处理器不仅集成了更多的内核和线程,对微架构也进行了全面升级优化,并配备了更快、效率更高的高速缓存来提升处理效能。同时,其集成的英特尔® DL Boost 技术,对 INT8 数值类型数据有着更好的支持,可大幅提升方案的模型推理速度。
■ 方案成效
通过在多个电力系统生产环境中的实际部署,验证了采用XGBoost 或随机森林算法的机器健康模型可对数据库健康状况进行有效预测。如图 2-2-23 所示,上图是模型预测结果, 下图是实际情况,两者的均方误差(Mean Squared Error, MSE)为 0.28,而在采用 XGBoost 算法的情况下,均方误差可进一步缩减到 0.218。同时,得益于基于英特尔 ® 架构的处理器的强大算力,两种算法的训练时间均在数秒内,满足了工业制造企业预测实时性的要求。

利用机器健康模型,及以其为核心的 “IT 健康分析” 系统,基石数据针对某电力企业省级公司的 20 多套系统进行了IT 健康分析巡检,仅在一个多月时间里,就发现问题 143 个,并全部完成溯源工作。同时,利用预测结果,用户还通过系统配置 调整、SQL 调整、参数调整等方法,提升了系统性能,使一体化电量与线损系统、数据管理服务、结构化数据中心等与业 务息息相关的核心信息化系统的健康分,由不足 80 分上升至90 分以上,获得了从管理层到生产一线的一致好评。