参考博客:
https://blog.csdn.net/oracle8090/article/details/80760233
https://www.cnblogs.com/ling1995/p/7339424.html(看我)
count(distinct id)的原理
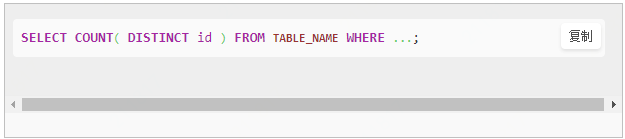
count(distinct id)从执行计划上面来看:只有一个reducer任务(即使你设置reducer任务为100个,实际上也没有用),所有的id都
会聚集到同一个reducer任务进行去重然后在聚合,这非常容易造成数据倾斜.
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: emp_ct
Statistics: Num rows: 42 Data size: 171 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: dept_num (type: int)
outputColumnNames: _col0
Statistics: Num rows: 42 Data size: 171 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Statistics: Num rows: 42 Data size: 171 Basic stats: COMPLETE Column stats: NONE
Reduce Operator Tree:
Group By Operator
aggregations: count(DISTINCT KEY._col0:0._col0)
mode: complete
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
运行示例:注意设置的reducer任务数量实际上是不生效的。
hive> set mapreduce.job.reduces=5;
hive>
> select count(distinct dept_num)
> from emp_ct;
Query ID = mart_fro_20200320233947_4f60c190-4967-4da6-bf3e-97db786fbc6c
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Start submit job !
Start GetSplits
GetSplits finish, it costs : 32 milliseconds
Submit job success : job_1584341089622_358496
Starting Job = job_1584341089622_358496, Tracking URL = http://BJHTYD-Hope-25-11.hadoop.jd.local:50320/proxy/application_1584341089622_358496/
Kill Command = /data0/hadoop/hadoop_2.100.31_2019090518/bin/hadoop job -kill job_1584341089622_358496
Hadoop job(job_1584341089622_358496) information for Stage-1: number of mappers: 2; number of reducers: 1
2020-03-20 23:39:58,215 Stage-1(job_1584341089622_358496) map = 0%, reduce = 0%
2020-03-20 23:40:09,628 Stage-1(job_1584341089622_358496) map = 50%, reduce = 0%, Cumulative CPU 2.74 sec
2020-03-20 23:40:16,849 Stage-1(job_1584341089622_358496) map = 100%, reduce = 0%, Cumulative CPU 7.43 sec
2020-03-20 23:40:29,220 Stage-1(job_1584341089622_358496) map = 100%, reduce = 100%, Cumulative CPU 10.64 sec
MapReduce Total cumulative CPU time: 10 seconds 640 msec
Stage-1 Elapsed : 40533 ms job_1584341089622_358496
Ended Job = job_1584341089622_358496
MapReduce Jobs Launched:
Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 10.64 sec HDFS Read: 0.000 GB HDFS Write: 0.000 GB SUCCESS Elapsed : 40s533ms job_1584341089622_358496
Total MapReduce CPU Time Spent: 10s640ms
Total Map: 2 Total Reduce: 1
Total HDFS Read: 0.000 GB Written: 0.000 GB
OK
3
Time taken: 43.025 seconds, Fetched: 1 row(s)
count(distinct id)的解决方案
该怎么解决这个问题呢?实际上解决方法非常巧妙:
我们利用Hive对嵌套语句的支持,将原来一个MapReduce作业转换为两个作业,在第一阶段选出全部的非重复id,在第二阶段再对
这些已消重的id进行计数。这样在第一阶段我们可以通过增大Reduce的并发数,并发处理Map输出。在第二阶段,由于id已经消重,
因此COUNT(*)操作在Map阶段不需要输出原id数据,只输出一个合并后的计数即可。这样即使第二阶段Hive强制指定一个Reduce Task,
极少量的Map输出数据也不会使单一的Reduce Task成为瓶颈。改进后的SQL语句如下:
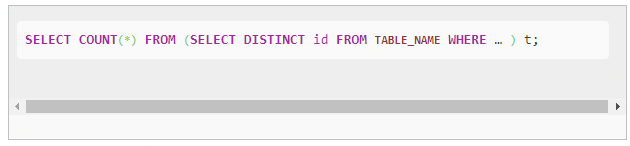
查看一下执行计划:
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-2 depends on stages: Stage-1
Stage-0 depends on stages: Stage-2
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: emp_ct
Statistics: Num rows: 42 Data size: 171 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: dept_num (type: int)
outputColumnNames: dept_num
Statistics: Num rows: 42 Data size: 171 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: dept_num (type: int)
sort order: +
Map-reduce partition columns: dept_num (type: int)
Statistics: Num rows: 42 Data size: 171 Basic stats: COMPLETE Column stats: NONE
Reduce Operator Tree:
Group By Operator
keys: KEY._col0 (type: int)
mode: complete
outputColumnNames: _col0
Statistics: Num rows: 21 Data size: 85 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazybinary.LazyBinarySerDe
Stage: Stage-2
Map Reduce
Map Operator Tree:
TableScan
Reduce Output Operator
sort order:
Statistics: Num rows: 21 Data size: 85 Basic stats: COMPLETE Column stats: NONE
value expressions: _col0 (type: int)
Reduce Operator Tree:
Group By Operator
aggregations: count(VALUE._col0)
mode: complete
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
具体看一下执行结果:注意看reducer任务的数量,第一个reducer任务是5个,第二个是1个.
hive> set mapreduce.job.reduces=5;
hive>
> select count(dept_num)
> from (
> select distinct dept_num
> from emp_ct
> ) t1;
Query ID = mart_fro_20200320234453_68ad3780-c3e5-44bc-94df-58a8f2b01f59
Total jobs = 2
Launching Job 1 out of 2
Number of reduce tasks not specified. Defaulting to jobconf value of: 5
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Start submit job !
Start GetSplits
GetSplits finish, it costs : 13 milliseconds
Submit job success : job_1584341089622_358684
Starting Job = job_1584341089622_358684, Tracking URL = http://BJHTYD-Hope-25-11.hadoop.jd.local:50320/proxy/application_1584341089622_358684/
Kill Command = /data0/hadoop/hadoop_2.100.31_2019090518/bin/hadoop job -kill job_1584341089622_358684
Hadoop job(job_1584341089622_358684) information for Stage-1: number of mappers: 2; number of reducers: 5
2020-03-20 23:45:02,920 Stage-1(job_1584341089622_358684) map = 0%, reduce = 0%
2020-03-20 23:45:23,533 Stage-1(job_1584341089622_358684) map = 50%, reduce = 0%, Cumulative CPU 3.48 sec
2020-03-20 23:45:25,596 Stage-1(job_1584341089622_358684) map = 100%, reduce = 0%, Cumulative CPU 7.08 sec
2020-03-20 23:45:32,804 Stage-1(job_1584341089622_358684) map = 100%, reduce = 20%, Cumulative CPU 9.43 sec
2020-03-20 23:45:34,861 Stage-1(job_1584341089622_358684) map = 100%, reduce = 40%, Cumulative CPU 12.39 sec
2020-03-20 23:45:36,923 Stage-1(job_1584341089622_358684) map = 100%, reduce = 80%, Cumulative CPU 18.47 sec
2020-03-20 23:45:40,011 Stage-1(job_1584341089622_358684) map = 100%, reduce = 100%, Cumulative CPU 23.23 sec
MapReduce Total cumulative CPU time: 23 seconds 230 msec
Stage-1 Elapsed : 46404 ms job_1584341089622_358684
Ended Job = job_1584341089622_358684
Launching Job 2 out of 2
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Start submit job !
Start GetSplits
GetSplits finish, it costs : 47 milliseconds
Submit job success : job_1584341089622_358729
Starting Job = job_1584341089622_358729, Tracking URL = http://BJHTYD-Hope-25-11.hadoop.jd.local:50320/proxy/application_1584341089622_358729/
Kill Command = /data0/hadoop/hadoop_2.100.31_2019090518/bin/hadoop job -kill job_1584341089622_358729
Hadoop job(job_1584341089622_358729) information for Stage-2: number of mappers: 5; number of reducers: 1
2020-03-20 23:45:48,353 Stage-2(job_1584341089622_358729) map = 0%, reduce = 0%
2020-03-20 23:46:05,846 Stage-2(job_1584341089622_358729) map = 20%, reduce = 0%, Cumulative CPU 2.62 sec
2020-03-20 23:46:06,873 Stage-2(job_1584341089622_358729) map = 60%, reduce = 0%, Cumulative CPU 8.49 sec
2020-03-20 23:46:08,931 Stage-2(job_1584341089622_358729) map = 80%, reduce = 0%, Cumulative CPU 11.53 sec
2020-03-20 23:46:09,960 Stage-2(job_1584341089622_358729) map = 100%, reduce = 0%, Cumulative CPU 15.23 sec
2020-03-20 23:46:35,639 Stage-2(job_1584341089622_358729) map = 100%, reduce = 100%, Cumulative CPU 20.37 sec
MapReduce Total cumulative CPU time: 20 seconds 370 msec
Stage-2 Elapsed : 54552 ms job_1584341089622_358729
Ended Job = job_1584341089622_358729
MapReduce Jobs Launched:
Stage-1: Map: 2 Reduce: 5 Cumulative CPU: 23.23 sec HDFS Read: 0.000 GB HDFS Write: 0.000 GB SUCCESS Elapsed : 46s404ms job_1584341089622_358684
Stage-2: Map: 5 Reduce: 1 Cumulative CPU: 20.37 sec HDFS Read: 0.000 GB HDFS Write: 0.000 GB SUCCESS Elapsed : 54s552ms job_1584341089622_358729
Total MapReduce CPU Time Spent: 43s600ms
Total Map: 7 Total Reduce: 6
Total HDFS Read: 0.000 GB Written: 0.000 GB
OK
3
Time taken: 103.692 seconds, Fetched: 1 row(s)
这个解决方案有点类似于set hive.groupby.skew.indata参数的作用!
实际测试:
select count(distinct dept_num) from emp_ct select count(*) from ( select distinct dept_num from emp_ct )