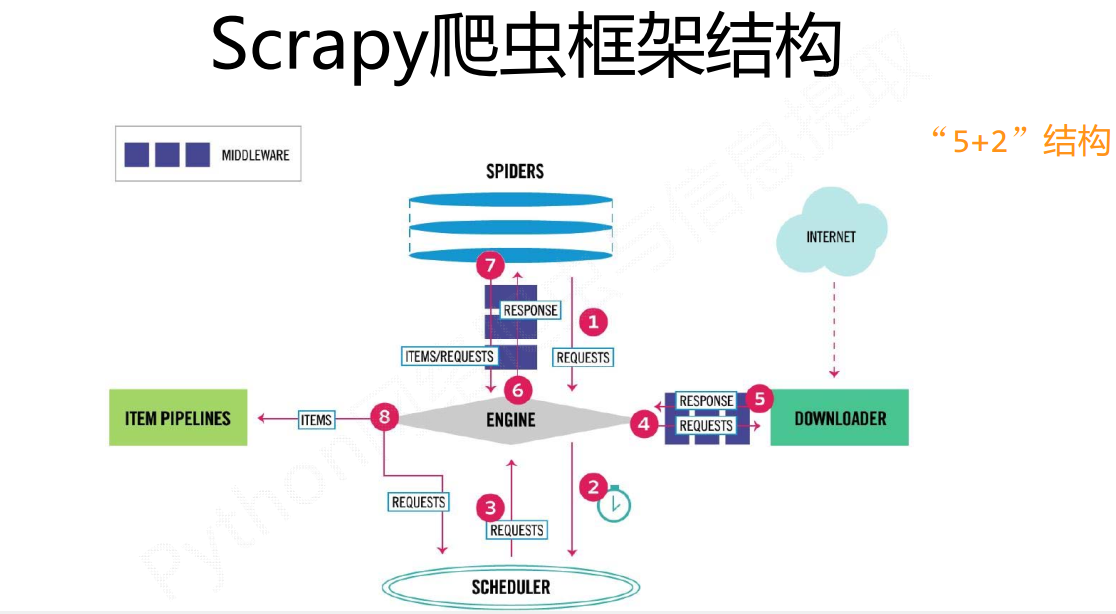
直接从数据流的角度来说比较容易理解:
·1、Spider创建一个初识url请求,把这个请求通过Engine转给Scheduler调度模块。然后Scheduler向Engine提供一个请求(这个请求是一个真实的url请求)
疑问点一:为什么Engine把请求发给Scheduler模块,然后又从Scheduler模块里面取出来,这不是多此一举么,这个Scheduler模块有作用么?
按照我的理解,scrapy把各个组件模块化,就是为了更加方便的配置,当然你把所有模块都写在一起,功能同样可以实现,只不过这就失去了这个框架的价值了,Scheduler就是为了存取请求,而Spider就是解析出新的请求和数据item。
疑问点二:为什么说Scheduler存的是真实的url请求
Spider里面的url不一定是我们需要的url,需要经过解析,生成我们所需要的真实url,然后通过Engine发送给Scheduler
2、第一步Engine已经得到了真实的url地址,然后Engine把这个请求request发送给Downloader模块
tips:我们主要到Engine发送请求给Downloader模块前,需要进过DownloaderMiddleware中间件,实际上这里可以对请求做一些修改,也就是添加User-Agent之类的参数,如果用过requests第三方包应该容易理解
3、Downloader模块把网页下载完成后会把结果返回给Engine
tips:这个过程同样会经过DownloaderMiddleware,所以很容易理解,我们可以在这里修改response相关信息
4、Engine得到数据之后,它会把数据发送给Spider进行解析得到item(数据)或者是request(新的请求)
tips:比如我们本来要获取的是图片信息,在得到的response中发现不止有图片信息(item),还有其他的连接(新的request)
5、Spider解析得到的item和request会有两种走向
a:如果是item,也就是已经得到了数据,那么就通过Engine把item发送到Itempipeline进行处理,这里主要是进行数据的清洗、查重、保存等操作。
b:如果生成的是request,照着之前的,通过Engine把真实请求request发送给Scheduler,然后Engine从Scheduler拿request,发给给Downloader下载,Downloader下载完通过Engine发送给Spider。。如此往复,直到没有新的request请求
有时候看到网上的教程那么长会觉得难,不想去学,真正去学的时候会发现,其实也就那样。好了,关于scrapy的数据流就到这。