
网站结构分析:
四个大标签:首页、公司、校园、言职
我们最终是要得到详情页的信息,但是从首页的很多链接都能进入到一个详情页,我们需要对这些标签一个个分析,分析出哪些链接我们需要跟进。
首先是四个大标签,鼠标点击进入后可以发现首页、公司、校园,这三个包含有招聘职位
1、首先是对首页的分析
首页正文部分包括:搜索栏(含热门搜索)、职业方向标签(java、php。。。)、热门职位、热门公司
搜索栏:搜索标签的岗位数量较少,我们要做全站数据爬取的话,不跟进这个标签
职业方向标签:这个标签指向的url都是lagou.com/zhaopin/.* (.*代表0个或多个任意字符)这种形式,岗位较全,需要跟进这些页面
热门职位:这个标签指向的url都是lagou.com/jobs/...这种形式,职业方向标签内详情页可能会有重复,同样不跟进
热门公司:这个标签指向的url都是lagou.com/gongsi/d+这种形式,点进去后可以看到详情页都包含在lagou.com/gongsi/j.*这种链接中,但实际上这个与上方四个大标签的公司标签也是重复的,所以这些页面也不在首页跟进
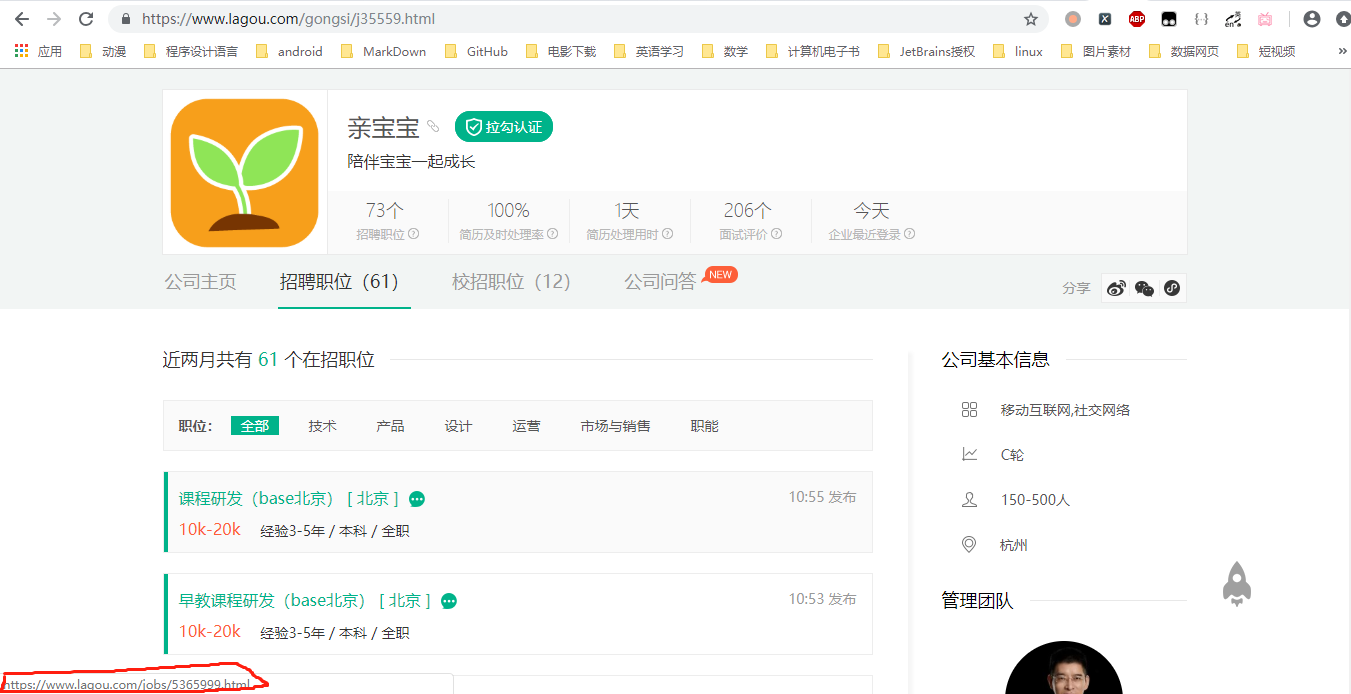
2、对大标签公司的分析
可以看到各个公司标签都包含在lagou.com/gongsi/这个链接下,每一个公司名类似lagou.com/gongsi/d+.html(d+代表一个或者多个数字)

进入其中一个公司页面,可以看到所有的招聘职位都在lagou.com/gongsi/jd+.html这样的页面下(d+代表一个或者多个数字),而岗位详情页类似lagou.com/jobs/d+.html
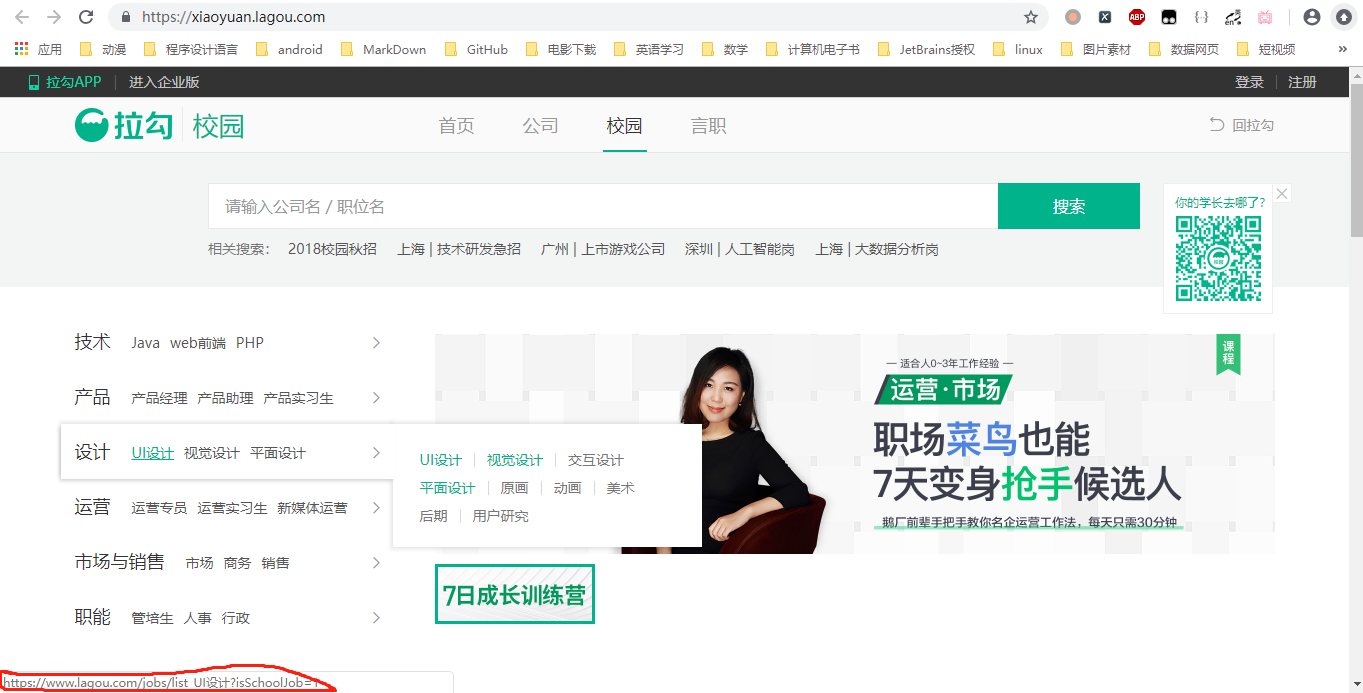
3、大标签校园的分析
可以看出来,这个和首页的结构比较类型,那我们就和首页一样,选取职业方向标签的url作为跟进的目标,可以看出每一个标签都是类似lagou.com/jobs/list_.* (.*代表0个或多个任意字符)
通过以上分析,我们就知道对于拉勾网来说,要想做到全站抓取,需要跟进哪些链接。