一、百度百科
- Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆
二、索引过程
索引过程是Lucene提供的核心功能之一。下图说明了索引过程和使用的类

三、demo
3.1 创建文档
- 从一个文件中获取lucene文档
- 创建各种类型的是含有键作为名称和值作为内容被编入索引键值对字段。
- 新创建的字段添加到文档对象并返回给调用者的方法
/** * 从文件中获取文档 * * @param file * @return * @throws IOException */ private Document getDocument(File file) throws IOException { Document document = new Document(); Field contentField = new TextField("fileContents", new FileReader(file)); /** * Field.Store.YES表示把该Field的值存放到索引文件中,提高效率,一般用于文件的标题和路径等常用且小内容小的。 */ Field fileNameField = new TextField("fileName", file.getName(), Field.Store.YES); Field filePathField = new TextField("filePath", file.getCanonicalPath(), Field.Store.YES); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document; }
3.2 创建IndexWriter
-
IndexWriter 类作为它创建/在索引过程中更新指标的核心组成部分
-
创建一个 IndexWriter 对象
-
创建其应指向位置,其中索引是存储一个lucene的目录
-
初始化索引目录,有标准的分析版本信息和其他所需/可选参数创建 IndexWriter 对象
// 写索引 private IndexWriter indexWriter; /** * 实例化写索引 * * @param dir * 保存索引的目录 * @throws IOException */ public Indexer(String dir) throws IOException { Directory indexDir = new SimpleFSDirectory(Paths.get(dir)); /** * IndexWriterConfig实例化该类的时候如果是空的构造方法,那么默认 public IndexWriterConfig() { this(new * StandardAnalyzer()); } */Analyzer analyzer=new StandardAnalyzer(); //分词器
IndexWriterConfig conf = new IndexWriterConfig(analyzer); }
3.3 开始索引过程
/** * 索引文件 */ public void index(File file) throws Exception { System.out.println("被索引的文件为:" + file.getCanonicalPath()); Document document = getDocument(file); indexWriter.addDocument(document); }
-
.txt 文件过滤器
public class FileFilter implements java.io.FileFilter{ public boolean accept(File pathname) { return pathname.getName().toLowerCase().endsWith(".txt"); } }
- Indexer类以及测试
package com.shyroke.lucene; import java.io.File; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.TextField; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.IndexableFieldType; import org.apache.lucene.queries.function.valuesource.DualFloatFunction; import org.apache.lucene.store.Directory; import org.apache.lucene.store.SimpleFSDirectory; public class Indexer { // 写索引 private IndexWriter indexWriter; /** * 实例化写索引 * * @param dir * 保存索引的目录 * @throws IOException */ public Indexer(String dir) throws IOException { Directory indexDir = new SimpleFSDirectory(Paths.get(dir)); /** * IndexWriterConfig实例化该类的时候如果是空的构造方法,那么默认 public IndexWriterConfig() { this(new * StandardAnalyzer()); } */ Analyzer analyzer=new StandardAnalyzer(); //分词器 IndexWriterConfig conf = new IndexWriterConfig(analyzer); indexWriter = new IndexWriter(indexDir, conf); } /** * 索引文件 */ public void index(File file) throws Exception { System.out.println("被索引的文件为:" + file.getCanonicalPath()); Document document = getDocument(file); indexWriter.addDocument(document); } /** * 从文件中获取文档 * * @param file * @return * @throws IOException */ private Document getDocument(File file) throws IOException { Document document = new Document(); Field contentField = new TextField("fileContents", new FileReader(file)); /** * Field.Store.YES表示把该Field的值存放到索引文件中,提高效率,一般用于文件的标题和路径等常用且小内容小的。 */ Field fileNameField = new TextField("fileName", file.getName(), Field.Store.YES); Field filePathField = new TextField("filePath", file.getCanonicalPath(), Field.Store.YES); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document; } /** * 创建索引 * * @param dataFile 数据文件所在的目录 * @return 索引文件的数量 * @throws Exception */ public int CreateIndex(String dataFile, FileFilter filter) throws Exception { File[] files = new File(dataFile).listFiles(); for (File file : files) { /** * 被索引文件必须不能是 1.目录 2.隐藏 3. 不可读 4.不是txt文件, * 否则不被索引 */ if (!file.isDirectory() && !file.isHidden() && file.canRead() && filter.accept(file)) { index(file); } } return indexWriter.numDocs(); } /** * 关闭写索引 * * @throws IOException */ public void close() throws IOException { indexWriter.close(); } /** * 测试 * @param args */ public static void main(String[] args) { String indexDir="E:\lucene\index"; String dataDir="E:\lucene\data"; int indexFileCount=0; Indexer indexer=null; try { indexer=new Indexer(indexDir); long startTime=System.currentTimeMillis(); indexFileCount=indexer.CreateIndex(dataDir, new FileFilter()); long endTime=System.currentTimeMillis(); System.out.println("索引文件共花费:"+(endTime-startTime)+" 毫秒"); System.out.println("一共索引了"+indexFileCount+"个文件"); } catch (Exception e) { e.printStackTrace(); }finally { try { indexer.close(); } catch (IOException e) { e.printStackTrace(); } } } }
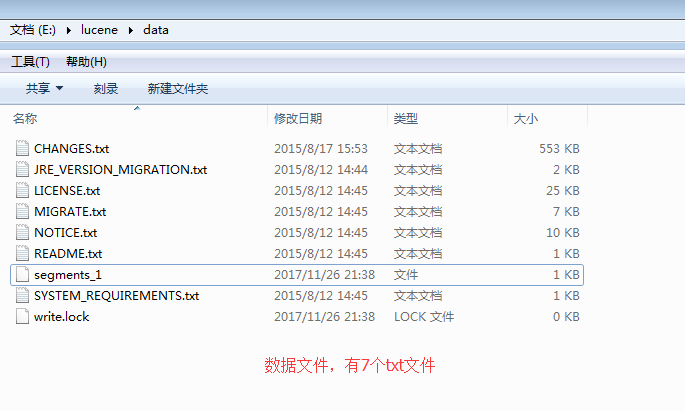
- 结果

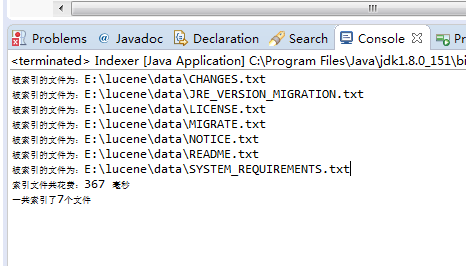
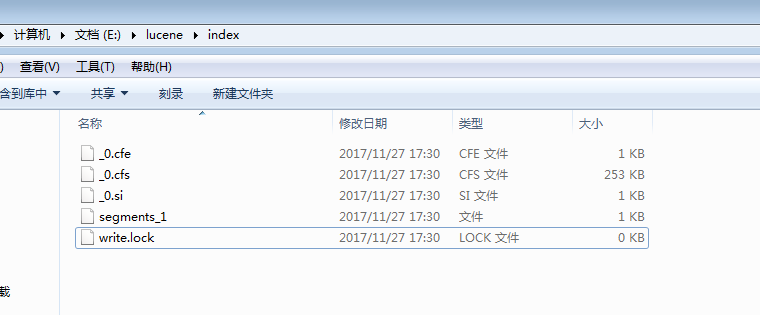
- 程序运行后,对data文件夹中的所有txt文件进行索引,生成的索引文件放于index文件夹中。