一、前言
Hive默认计算引擎时MR,为了提高计算速度,我们可以改为Tez引擎。至于为什么提高了计算速度,可以参考下图:
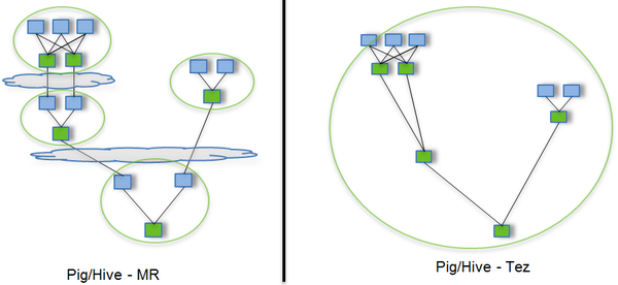
用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,上图中,绿色是Reduce Task,云状表示写屏蔽,需要将中间结果持久化写到HDFS。
Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
二、安装包准备
1)下载tez的依赖包:http://tez.apache.org
2)拷贝apache-tez-0.9.1-bin.tar.gz到hadoop102的/opt/module目录
[root@hadoop102 module]$ ls
apache-tez-0.9.1-bin.tar.gz
3)解压缩apache-tez-0.9.1-bin.tar.gz
[root@hadoop102 module]$ tar -zxvf apache-tez-0.9.1-bin.tar.gz
4)修改名称
[root@hadoop102 module]$ mv apache-tez-0.9.1-bin/ tez-0.9.1
三、在Hive中配置Tez
1)进入到Hive的配置目录:/opt/module/hive/conf
[root@hadoop102 conf]$ pwd
/opt/module/hive/conf
2)在hive-env.sh文件中添加tez环境变量配置和依赖包环境变量配置
[root@hadoop102 conf]$ vim hive-env.sh
添加如下配置
# Set HADOOP_HOME to point to a specific hadoop install directory
export HADOOP_HOME=/opt/module/hadoop-2.7.2
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/opt/module/hive/conf
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
export TEZ_HOME=/opt/module/tez-0.9.1 #是你的tez的解压目录
export TEZ_JARS=""
for jar in `ls $TEZ_HOME |grep jar`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar
done
for jar in `ls $TEZ_HOME/lib`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar
done
export HIVE_AUX_JARS_PATH=/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar$TEZ_JARS
3)在hive-site.xml文件中添加如下配置,更改hive计算引擎
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
四、配置Tez
1)在Hive的/opt/module/hive/conf下面创建一个tez-site.xml文件
[root@hadoop102 conf]$ pwd
/opt/module/hive/conf
[root@hadoop102 conf]$ vim tez-site.xml
添加如下内容
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name> <value>${fs.defaultFS}/tez/tez-0.9.1,${fs.defaultFS}/tez/tez-0.9.1/lib</value>
</property>
<property>
<name>tez.lib.uris.classpath</name> <value>${fs.defaultFS}/tez/tez-0.9.1,${fs.defaultFS}/tez/tez-0.9.1/lib</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.history.logging.service.class</name> <value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value>
</property>
</configuration>
五、上传Tez到集群
1)将/opt/module/tez-0.9.1上传到HDFS的/tez路径
[root@hadoop102 conf]$ hadoop fs -mkdir /tez
[root@hadoop102 conf]$ hadoop fs -put /opt/module/tez-0.9.1/ /tez
[root@hadoop102 conf]$ hadoop fs -ls /tez
/tez/tez-0.9.1
六、测试
1)启动Hive
[root@hadoop102 hive]$ bin/hive
2)创建LZO表
hive (default)> create table student(
id int,
name string);
3)向表中插入数据
hive (default)> insert into student values(1,"zhangsan");
4)如果没有报错就表示成功了
hive (default)> select * from student;
1 zhangsan
七、小结
1)运行Tez时检查到用过多内存而被NodeManager杀死进程问题:
Caused by: org.apache.tez.dag.api.SessionNotRunning: TezSession has already shutdown. Application application_1546781144082_0005 failed 2 times due to AM Container for appattempt_1546781144082_0005_000002 exited with exitCode: -103
For more detailed output, check application tracking page:http://hadoop103:8088/cluster/app/application_1546781144082_0005Then, click on links to logs of each attempt.
Diagnostics: Container [pid=11116,containerID=container_1546781144082_0005_02_000001] is running beyond virtual memory limits. Current usage: 216.3 MB of 1 GB physical memory used; 2.6 GB of 2.1 GB virtual memory used. Killing container.
这种问题是从机上运行的Container试图使用过多的内存,而被NodeManager kill掉了。
[摘录] The NodeManager is killing your container. It sounds like you are trying to use hadoop streaming which is running as a child process of the map-reduce task. The NodeManager monitors the entire process tree of the task and if it eats up more memory than the maximum set in mapreduce.map.memory.mb or mapreduce.reduce.memory.mb respectively, we would expect the Nodemanager to kill the task, otherwise your task is stealing memory belonging to other containers, which you don't want.
解决方法:
方案一:或者是关掉虚拟内存检查。我们选这个,修改yarn-site.xml
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
方案二:mapred-site.xml中设置Map和Reduce任务的内存配置如下:(value中实际配置的内存需要根据自己机器内存大小及应用情况进行修改)
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>