投票法(voting)是集成学习里面针对分类问题的一种结合策略。基本思想是选择所有机器学习算法当中输出最多的那个类。
分类的机器学习算法输出有两种类型:一种是直接输出类标签,另外一种是输出类概率,使用前者进行投票叫做硬投票(Majority/Hard voting),使用后者进行分类叫做软投票(Soft voting)。 sklearn中的VotingClassifier是投票法的实现。
硬投票
硬投票是选择算法输出最多的标签,如果标签数量相等,那么按照升序的次序进行选择。下面是一个例子:
from sklearn import datasets from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import VotingClassifier iris = datasets.load_iris() X, y = iris.data[:,1:3], iris.target clf1 = LogisticRegression(random_state=1) clf2 = RandomForestClassifier(random_state=1) clf3 = GaussianNB() eclf = VotingClassifier(estimators=[('lr',clf1),('rf',clf2),('gnb',clf3)], voting='hard') #使用投票法将三个模型结合在以前,estimotor采用 [(name1,clf1),(name2,clf2),...]这样的输入,和Pipeline的输入相同 voting='hard'表示硬投票 for clf, clf_name in zip([clf1, clf2, clf3, eclf],['Logistic Regrsssion', 'Random Forest', 'naive Bayes', 'Ensemble']): scores = cross_val_score(clf, X, y, cv=5, scoring='accuracy') print('Accuracy: {:.2f} (+/- {:.2f}) [{}]'.format(scores.mean(), scores.std(), clf_name))
data[:,1:3] : iris.data第一个维度的所有,第二个维度的第1,2个
结果如下:
Accuracy: 0.90 (+/- 0.05) [Logistic Regrsssion] Accuracy: 0.93 (+/- 0.05) [Random Forest] Accuracy: 0.91 (+/- 0.04) [naive Bayes] Accuracy: 0.95 (+/- 0.05) [Ensemble] 实际当中会报:DeprecationWarning
软投票
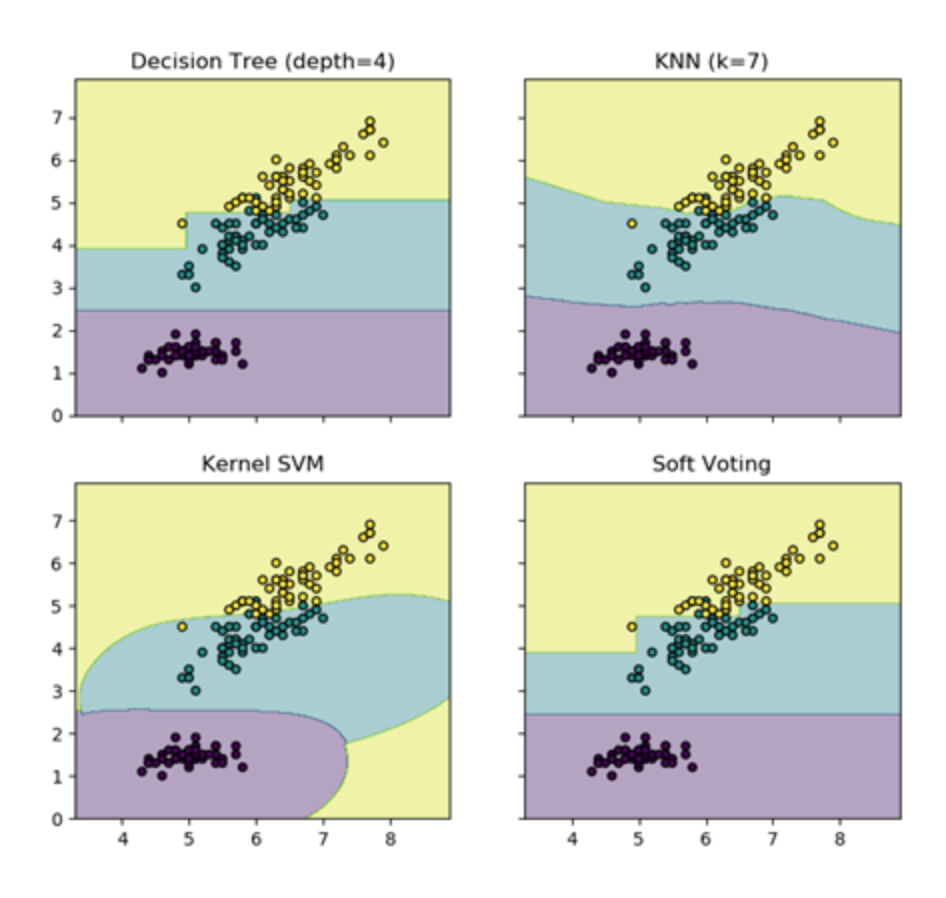
软投票是使用各个算法输出的类概率来进行类的选择,输入权重的话,会得到每个类的类概率的加权平均值,值大的类会被选择。
from itertools import product import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC from sklearn.ensemble import VotingClassifier iris = datasets.load_iris() X = iris.data[:,[0,2]] #取两列,方便绘图 y = iris.target clf1 = DecisionTreeClassifier(max_depth=4) clf2 = KNeighborsClassifier(n_neighbors=7) clf3 = SVC(kernel='rbf', probability=True) eclf = VotingClassifier(estimators=[('dt',clf1),('knn',clf2),('svc',clf3)], voting='soft', weights=[2,1,1]) #weights控制每个算法的权重, voting=’soft' 使用了软权重 clf1.fit(X,y) clf2.fit(X,y) clf3.fit(X,y) eclf.fit(X,y) x_min, x_max = X[:,0].min() -1, X[:,0].max() + 1 y_min, y_max = X[:,1].min() -1, X[:,1].max() + 1 xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01)) #创建网格 fig, axes = plt.subplots(2, 2, sharex='col', sharey='row', figsize=(10, 8)) #共享X轴和Y轴 for idx, clf, title in zip(product([0, 1],[0, 1]), [clf1, clf2, clf3, eclf], ['Decision Tree (depth=4)', 'KNN (k=7)', 'Kernel SVM', 'Soft Voting']): Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) #起初我以为是预测的X的值,实际上是预测了上面创建的网格的值,以这些值来进行描绘区域 Z = Z.reshape(xx.shape) axes[idx[0], idx[1]].contourf(xx, yy, Z, alpha=0.4) axes[idx[0], idx[1]].scatter(X[:, 0],X[:, 1], c=y, s=20, edgecolor='k') axes[idx[0], idx[1]].set_title(title) plt.show()
numpy.meshgrid()——生成网格点坐标矩阵。
结果如下: