摘要
这篇文章主要总结文本中的对抗样本,包括器中的攻击方法和防御方法,比较它们的优缺点。
最后给出这个领域的挑战和发展方向。
1 介绍
对抗样本有两个核心:一是扰动足够小;二是可以成功欺骗网络。
所有DNNs-based的系统都有受到对抗攻击的潜在可能。
很多NLP任务使用了DNN模型,例如:文本分类,情感分析,问答系统,等等。

以上是一个对抗攻击实例。除此之外,对抗样本还会毒害网络环境,阻碍对恶意信息[21]-[23]的检测。
除了对比近些年的对抗攻击和防御方法,此外,文章还会讲CV和NLP中该领域的方法(包括评价方法)为何不通用,以及测试和验证的重要性。
本文结构:首先在第二节中给出一些关于对抗性例子的背景知识。在第三节中,回顾了文本分类和其他实际NLP任务的对抗性攻击。第五节和第六节主要介绍了以防御为中心的研究,一是对文本中已有的防御方法的研究,二是从另一个角度研究如何提高DNNs的鲁棒性。本文的讨论和结论见第七和第八节。
2 背景
对抗样本的表达
文本中的对抗攻击和对抗防御的样本的分类
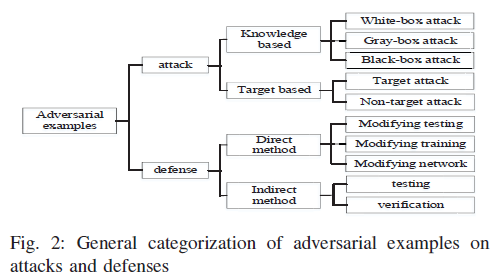
1. 对抗攻击的分类
以文本分类问题为例。
黑盒。不需要了解网络结构或只了解一点点。
白盒。完全理解目标模型,包括架构,各种参数和权重。
黑盒和白盒的方法都不能改变训练数据和模型。
定向攻击。对抗样本的目标是被成功分到类别t(既定的类别)。主要是来增加类别t的置信度。
不定向攻击。目标只是将样本分到错误的类别(这个类别不特定)。目标是欺骗模型,主要是降低真实类别的置信度。
2. 防御对抗攻击方法的分类
主要的两种方法、总结如下:
为了保护基于DNN的系统免受对抗攻击,评估这些系统在最坏情况下的鲁棒性,这导致了两种防御方向。
一种是通过修改测试、训练或模型来直接防御对抗性攻击。直接法上常用的方法有对抗性样本的检测、对抗性训练和损失函数的变化。
二是通过提高DNNs的鲁棒性,包括测试和验证方法。
评价标准
1. 图像中的评价方法
在图像中,几乎所有最近关于对抗性攻击的研究都采用Lp距离作为距离度量来量化对抗性实例的不可感知性和相似性。Lp距离的广义项为:

△x表示扰动。这个方程是一组距离的定义其中p可以是0 1∞等等。特别是L0 [28] - [30] L2[30] -[33]和L∞[7],[8]、[33]-[36]是对抗性图像中最常用的三种规范。
L0距离计算修改前后改变的像素数。它看起来像编辑距离,但它可能不能直接在文本中工作。因为文本中单词改变的结果是不同的。有些与原文相似,有些则相反,尽管它们之间的距离是相同的。
L2距离是欧几里德距离。最初的欧几里德距离是欧几里德空间中一点到另一点的直线。当图像、文本等映射到它时,欧几里得空间就变成了度量空间,用来计算以向量表示的两个对象之间的相似性。
L∞距离表示最大变化量,如下:
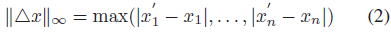
虽然L∞距离被认为是一些工作中使用的最优距离度量,但在文本中可能会失败。修改后的单词可能不存在于预先训练好的字典中,因此它们被认为是未知单词,它们的单词向量也是未知的。因此,L∞距离很难计算。
因此,文本中需要可用的评价标准,但和图像领域是大有不同的。
2. 文本度量
为了克服对抗性文本中的度量问题,本文提出了一些度量方法,并对其中五个已在相关文献中得到证明的度量方法进行了描述。
欧几里得距离
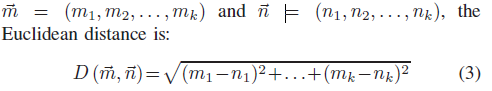
相比文本欧氏距离更多地用于度量对抗性图像[30]-[33],叫做L2范数或L2距离。
余弦相似度
余弦相似度也是一种基于词向量的语义相似度计算方法,通过两个向量夹角的余弦值来计算。与欧氏距离相比,余弦距离更关注两个向量方向的不同。两个向量的方向越一致,相似性越大。对于给定的两个字向量~m和~n,余弦相似度为
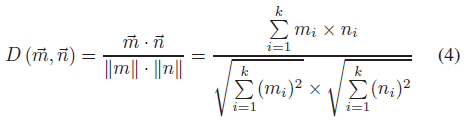
但是限制是单词向量的维数必须相同。
Jaccard相似性系数。对于两个给定的集合A和B,它们的Jaccard相似系数为:
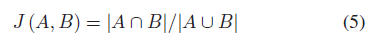
0 ≤ J(A,B) ≤ 1,J(A,B)的值越接近1,它们就越相似。在文本中,交集A∩B是指例子中相似的词,并集A∪B是所有词(without duplication)。
单词移动距离(WMD)
WMD[39]是Earh Mover's Distance(EMD)[40]的一种变化。它可以用来衡量两个文本文档之间的差异,依赖于从一个文档的嵌入词到另一个文档的移动距离。换句话说,WMD可以量化文本之间的语义相似性。同时,欧氏距离也用于WMD的计算。
编辑距离
编辑距离是通过将字符串转换为另一个字符串来度量最小修改量的一种方法。它越高,就越不相似。它可以应用于计算生物学和自然语言处理。Levenshtein距离[41]也称为编辑距离,在[24]的工作中使用插入、删除、替换操作。(leetcode有一道类似的题之后再仔细看下)
这些度量方法用于不同的情况。向量上采用欧氏距离、余弦距离和WMD。在文本中,对抗样本和干净样本应该转化为向量。然后用这三种方法计算它们之间的相似度。Jaccard相似系数和编辑距离可以直接用于不需要形式转换的文本输入。
文本数据集
为了使需要数据的人更容易访问数据,文章收集了一些近年来应用于NLP任务的数据集。
下载地址:
1http://www.di.unipi.it/ gulli/AG corpus of news articles.html
2https://wiki.dbpedia.org/services-resources/ontology
3http://snap.stanford.edu/data/web-Amazon.html
4 https://sourceforge.net/projects/yahoodataset/
5https://www.yelp.com/dataset/download
6http://www.cs.cornell.edu/people/pabo/movie-review-data/
7http://mpqa.cs.pitt.edu/
8http://ai.stanford.edu/ amaas/data/sentiment/
9https://nlp.stanford.edu/projects/snli/
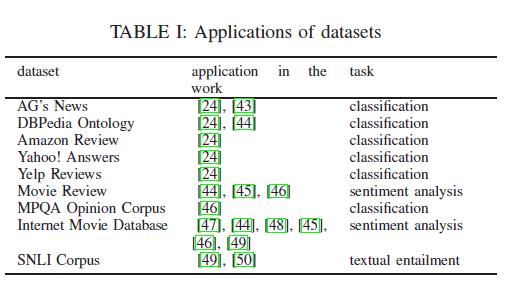
表I是数据的应用。研究工作中使用的其他数据集列在附录X中。
描述
AG’s News1: 由一个名为ComeToMyHead的学术新闻搜索引擎从2000多个新闻源中收集了超过100万篇文章的新闻集。所提供的db版本和xml版本可以下载用于任何非商业用途。
DBPedia Ontology2:包含来自各种Wikimedia项目中创建的信息的结构化内容。它有超过68个类,2795个不同的属性,现在这个数据集中包含了400多万个实例。
Amazon review 3:从1995年6月到2013年3月,Amazon review数据集拥有近3500万条评论,包括产品和用户信息、评分和纯文本评论。它被200多万种产品中的600多万用户收集,并被分为33个类,大小从KB到GB不等。
Yahoo! answer 4:语料库包含400万个问题及其答案,可以方便地在问答系统中使用。此外,还可以用一些主类构造主题分类数据集。
Yelp Reviews5:提供的数据由Yelp提供,以使研究人员或学生能够开发学术项目。它包含470万条用户评论,其中包含json文件和sql文件的类型。
Movie Review(MR)6:这是一个有标记的数据集,涉及情感极性、主观评分和带有主观地位或极性的句子。可能因为它是由人类标记的,所以这个数据集的大小比其他数据集要小,最大为几十MB。
MPQA Opinion Corpus7: 多视角问答(Multi-Perspective Question answer, MPQA),语料库收集了各种各样的新闻来源,并为观点或其他私有状态进行注释。MITRE公司为人们提供了三种不同的版本。版本越高,内容越丰富。
Internet Movie Database (IMDB)8: IMDBs是从互联网上抓取的,包括5万条正面和负面的评论,平均评论长度近200字。它通常用于二元情绪分类,包括比其他类似数据集更丰富的数据。IMDB还包含附加的未标记数据、原始文本和已处理的数据。
SNLI Corpus9:斯坦福自然语言推理(SNLI)语料库是一个人工标注数据的集合,主要用于自然语言推理(NLI)任务。有近50万对句子是人类在一定的语境中写成的。关于这个语料库的更多细节可以在Samuel等人的研究中看到。
对抗样本的性能评价
研究人员通常通过准确率或错误率来评估他们对目标模型的攻击。
正确率:输入正确识别率。正确率越低,对抗性的例子越有效。
此外,一些研究人员更喜欢利用攻击前后的准确性差异,因为它可以更直观地显示攻击的效果。这些标准也可以用来抵御对抗性样本。
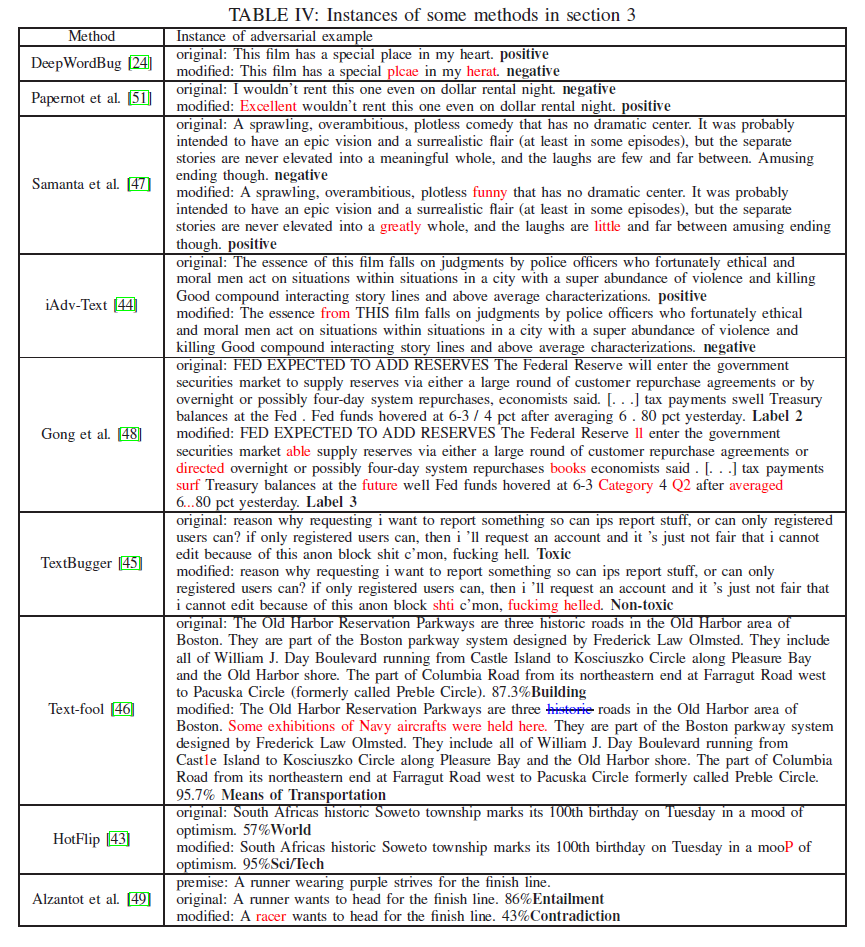
3 文本分类中的对抗攻击
由于对抗性攻击的目的是使DNNs行为失当,因此可以从广义上将其视为一个分类问题(正确或错误的判断)。近年来,文本中具有代表性的对抗性攻击大多与分类任务有关。在本节中,我们根据分类的类型将文本中现有的大多数对抗性攻击分为三个部分。下面给出了每种攻击方法的技术细节和相应的注释。
A.分类的非目标攻击
非目标攻击,攻击者不关心分类错误的结果。
1)基于图像的方法
研究人员提出图像中的方法是否可以用于测试。一些研究人员已经尝试过这种方法,并取得了更好的结果。提出了基于梯度的快速梯度符号法(FGSM)[8]算法。(看一下)
Papernot等人的[51]是第一个研究文本对抗式问题,在RNN上产生对抗性输入序列。作者利用计算图形展开来计算关于嵌入单词序列输入的正向导数(即雅可比矩阵)。然后用FGSM对雅可比矩阵张量进行评估,找出对抗性扰动。同时,为了解决这一过程中修改后的单词嵌入的映射问题,他们设置了一个专门的字典来选择单词,用于替换原来的单词。这种替换操作的约束条件是,被替换的单词与原单词之间的差异符号最接近FGSM的结果。虽然对抗性的输入序列可以使得长短时记忆(LSTM)[53]模型行为不规范,输入序列的单词是随机选择的,可能存在语法错误。
Samanta等人提出的[47]方法也基于FGSM类对位输入序列[51]。但它们之间的区别在于产生对抗样本的方式(即三个修改策略。Samanta等人引入了插入、替换和删除),尽可能地保留输入的语义。这些修改的前提是计算重要或突出的单词,如果去掉这些单词,将会对分类结果产生很大的影响。作者利用FGSM的概念对一个词的贡献进行评价,然后根据贡献的递减顺序对目标词进行排序。
除了删除策略外,高排名单词的插入和替换都需要额外的辅助。因此,作者为实验中的每个单词建立了一个候选池,包括同义词、拼写错误和特殊类型的关键字。但是,它会消耗大量的时间,并且实际输入文本中最重要的单词可能没有候选池。
2)基于优化的方法
与其他方法不同,Sato等人利用[44]对文本进行输入嵌入空间操作,重构对偶实例,对目标模型进行误分类。该方法的核心思想可以看作是一个优化问题。他们寻找总体参数W下损失函数最大化的方向向量的权值为:
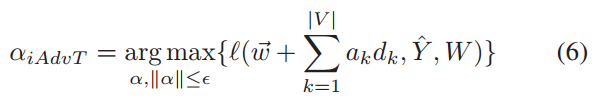
![]() 为每个输入对其字嵌入向量~w产生的扰动。d~是嵌入空间中从一个词到另一个词的方向向量。上式难以计算,作者使用下式替换:
为每个输入对其字嵌入向量~w产生的扰动。d~是嵌入空间中从一个词到另一个词的方向向量。上式难以计算,作者使用下式替换:
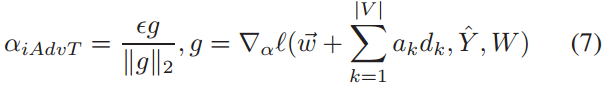
iAdvT的损失函数定义基于ℵiAdvT,作为一个优化问题,共同最小化整个训练数据集D的目标函数,公式如下:
 (重点看一下)
(重点看一下)
与Miyato等人的[54]相比,iAdv-Text 将扰动的方向限制为在预定义的词汇表中寻找一个替换词,而不是一个未知的单词来替换原来的单词。因此,它通过对抗性训练提高了对抗性例子的解释力。同时,作者还利用余弦相似度来选择更好的扰动。同样的,Gong等人[48]在嵌入空间中寻找对偶扰动,但他们的方法是基于梯度的。虽然WMD被作者用来衡量干净样本和对抗样本之间的相似性,但是生成的结果的可读性似乎有点差。
3)基于单词重要性的方法
与之前的白盒方法[51]、[47]不同,很少关注带有对抗性文本的黑盒攻击。Gao等人[24]提出了一种新的算法DeepWordBug在黑盒场景中使DNNs行为失当。他们提出的两个阶段的过程是确定哪些重要的令牌需要更改,并分别创建可以逃避检测的不易察觉的扰动。第一阶段的计算过程如下
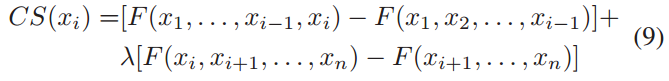
其中xi是输入的第i个单词,F是评估置信度得分的函数。然后,类似的修改(如交换、替换、删除和插入)被应用于操作重要的token,以生成更好的对抗样本。同时,为了保持这些例子的可读性,作者使用了编辑距离。Li等人提出了一种攻击框架TextBugger,用于生成对抗样本,在黑盒和白盒设置下触发基于深度学习的文本理解系统。他们遵循一般步骤来捕捉对分类有重要意义的重要单词,然后在其上进行精雕细琢。在白盒设置中,使用雅可比矩阵计算每个单词的重要性,如下所示
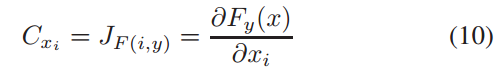 (雅可比矩阵看一下)
(雅可比矩阵看一下)
其中F y(·)表示类y的置信度值,通过插入、删除、交换、替换等操作,单词的细微变化分别为字符级和单词级。在黑箱设置中,将文档分割成序列,并对目标模型进行了探索,筛选出与原预测标签不同的句子。这些奇数序列根据它们的置信度按相反的顺序排序。然后用删除法计算重要字,计算方法如下:(过程看一下)
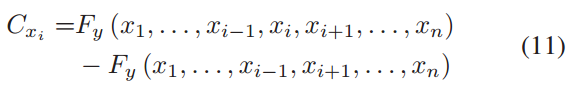
最后的修改过程与白盒设置相同。
B.分类的目标攻击
对于目标攻击,攻击者有目的地控制输出的类别,使其成为他们想要的。生成的对抗样本依然和干净样本具有相近的语义信息。
1)基于图像的方法
与[51]、[47]不同,Liang等人首先证明了FGSM不能直接应用于文本。因为文本的输入空间是离散的,而图像数据是连续的。连续图像具有对微小扰动的容忍度,而文本则没有这种特性。相反,作者使用FGSM来确定在文本输入上插入、删除和修改什么、在哪里以及如何插入、删除和修改。他们在不同的场景下进行了两种攻击,并使用自然语言水印[55]技术使生成的对抗样本损害了它们的实用价值。
在白盒场景中,定义了热训练短语和热样本短语(???)的概念。这两个对象都是利用反向传播算法计算算例的代价梯度得到的。前者阐明了应该插入什么,而后者暗示了在哪里插入、删除和修改。
在黑盒场景中,作者借鉴fuzzing技术的思想[56],获得了热训练短语和热样本短语。一个假设是目标模式可以探测。将实例输入到目标模型中,每次都用等距空格代替原词。修改前后分类结果的差异为每个单词的偏差。它越大,对应的词对它的分类就越重要。因此,在每个训练样本的偏差最大的单词集合中,热门训练短语是最常见的单词。热样本短语是每个测试样本中偏差最大的单词。
2)基于梯度的方法
类似于一像素攻击[9], Ebrahimi等人提出了一种类似的方法HotFlip。HotFlip是一种文本中的白盒攻击,它依赖于一个原子翻转操作来基于梯度计算将一个token替换为另一个token。作者将样本表示为输入空间中的一个热向量。翻转操作可以表示为:
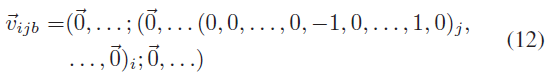
式(12)表示在一个样本中,第i个单词的第j个字符由a变为b,这两个字符分别位于字母表的a-th和b-th位置。计算沿该向量方向导数的变化量,得到损失增加最大的J(a, y),公式如下:
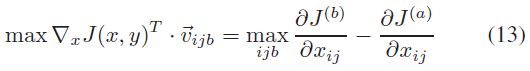
![]()
HotFlip还可以用于字符级插入、删除和字级修改。虽然HotFlip在字符级模型上表现良好,在严格的约束下,只有少数成功的对抗样本可以通过一两次翻转生成。
3)基于优化的方法
考虑到基于梯度的方法在黑盒情况下的局限性[23,[43,147,51],Alzantot等[49]提出了一种基于种群的优化方法,通过遗传算法[57],[58]生成语义相似的反例。(看一下)
作者在输入中随机选择单词,并在GloVe嵌入空间中利用欧氏距离计算其最近邻[59]。根据语言模型[16](???)的得分,对不适应环境的近邻进行过滤。因此,只保留得分最高的高排名单词。从剩余的单词中选择能够最大化目标标签概率的替代品。与此同时,上述操作被多次执行得到一代。如果某代后修改后的例子的预测标签不是目标标签,则通过每次随机选择两个样本作为父代生成下一代。然后同样的过程在下一代身上重复。该优化过程是为了利用遗传算法寻找成功的攻击。在这个方法中。在序列中随机选择要替换的单词充满了不确定性。这些替换可能没有意义,即使目标标签已经改变。
4)分类对抗攻击概述
上述分类攻击在最近的研究中要么是比较流行的攻击,要么是具有代表性的攻击。表二总结了它们的一些主要属性,文献中的实例在附录IX.
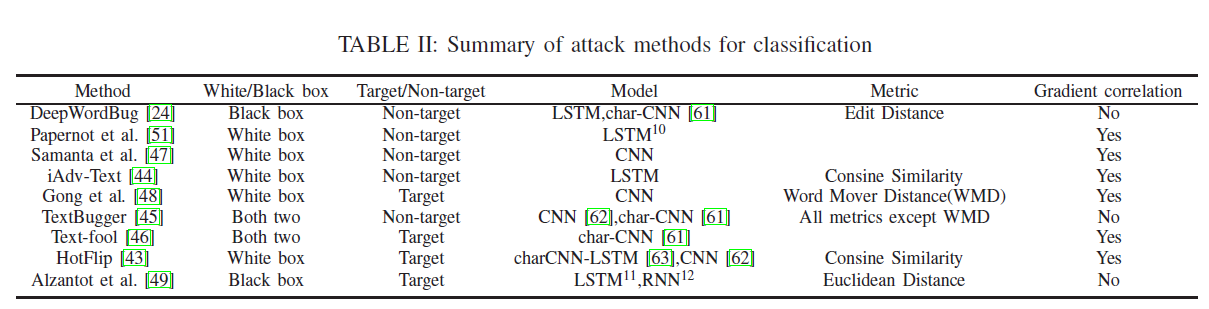
我们可以看到,这些攻击大多是基于梯度的,或者与梯度有关。基于梯度的方法在图像处理中得到了广泛的应用,也可以在文本中应用。但基于梯度的方法存在一些不足。它们只能在白盒场景中使用。在黑盒攻击中,对抗性攻击主要依赖于对抗性实例的可转移性。另一个限制是梯度掩蔽[65](看一下)在某些情况下会使梯度失效,导致基于梯度的方法失败。尽管这种方法被证明是一种失败的防御,但是基于梯度的方法并没有我们想象的那么有效。
4 其他类别中的对抗攻击
A. 阅读理解系统
为了了解阅读理解系统是否能够真正理解语言,Jia等[66]在不改变真实答案或误导人类的情况下,在段落中插入对抗性干扰来测试系统。他们提取了问题中的名词和形容词并用反义词替换了它们。同时,根据GloVe嵌入空间中最近的字改变命名实体和编号[59]。修改后的问题转化为陈述句作为对抗性干扰,然后连接到原段的末尾。这个过程由作者调用ADDSENT。另一个过程ADDANY也用于随机选择要加工的一些单词的任何序列。相比之下,ADDSENT、ADDANY不考虑语法性,需要多次查询模型。这两种方法都可以很好地欺骗阅读理解系统,因为它们都是正确的。
B.自然语言推理(NLI)模型
除阅读理解系统外,Minervini等人[50]还将对抗样本的生成视为一个优化问题。但是他们在NLI中加入了一些一阶逻辑(FOL)的约束,得到了可以打破这些约束的对抗样本。他们将不一致损失最大化,以通过使用以下的语言模型搜索替换集S:
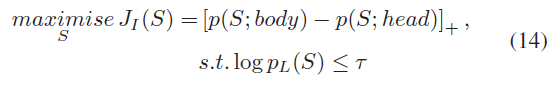
![]()
T:生成序列的困惑度的阈值
X1,..., Xn: S中规则到序列的一组通用量化变量。
S = {X1→s1,……,Xn→sn}: 一个{X1,…,Xn}的映射
p (S;body)和p (S;head): 给定规则的概率,用相应的句子Si替换Xi后,生成的序列可以帮助作者发现NLI系统的薄弱环节。(这个方法看一下,相减是做啥)
C.神经机器翻译(NMT)
NMT是另一种被对抗攻击的系统,Belinkov等人曾做过这种尝试。他们设计了基于自然和合成语言错误的黑盒方法来生成对抗样本。
自然语言发生的错误包括打字错误、拼写错误或其他语法上相反的例子,然后在语法上对抗样本被随机地或根据键盘输入类型修改。在三种不同的NMT系统69和701上进行了实验,结果表明,这些样本也可以有效地欺骗目标系统。Ebrahimi等人也做了类似的工作,通过使用可微的字符串编辑操作对字符级NMT进行对抗性攻击。对抗样本的生成方法与他们之前的工作[|43]相同。与Belinkov等人[68]相比,作者证明,在大多数情况下,黑盒对抗样本比白盒要弱得多。
(每个类型的经典方法再看一下,感觉不是很理解)
D.使用语法控制的释义网络(SCPNS)进行攻击
Iyyer等人[72]利用SCPNS生成对抗样本。这个模型是为了在不降低输入语义质量的情况下生成对抗样本。一般的过程主要依赖于SCPNS的编解码器架构。给出一个序列和相应的目标语法结构,用双向LSTM模型对其进行编码,再用LSTM模型进行解码。这个过程通过对编码状态[73]和复制机制[74]的增强了soft attention。然后,修改了对解码器的输入,目的是结合目标语法结构来生成对抗样本。
句法对抗句不仅可以欺骗预先训练好的模型,而且可以提高模型对句法变异的鲁棒性。作者还使用了众包实验来证明生成的结果的有效性。
E.用于度量模型鲁棒性的对抗样本
为了度量模型的鲁棒性,除了攻击之外,还可以使用对抗样本来度量DNN模型的鲁棒性。Blohm等人[751]通过生成对抗样本来找出他们设计的机器阅读理解模型的局限性。这些对抗样本的范畴包括不同情景下的词级和句级。通过与人类行为的比较,实验结果表明,其他一些属性(例如:为通过排序的合理性来排除答案)应该添加到该模型中,以提高其性能。
5 文本中对对抗攻击的防御
防守比进攻难,在这方面的工作很少。
造成这种情况有两个原因:一是对于复杂的优化问题,如对抗性问题,不存在一个好的理论模型。
另一个是,大量的可能输入可能产生目标输出,具有很高的可能性。因此,真正的自适应防御方法是困难的。
一般来说,有以下几种防御方法:
A. 对抗样本检测
对抗对抗攻击的一种防御策略是检测输入数据是否被修改。
Gao等[24使用的ar autocorrector是Python在输入前自动更正的0.3.0包。Li等人利用上下文感知拼写检查服务,做了类似的工作,但实验结果表明,这种方法在字符级修改上是有效的,在单词级操作上只有一定的用处。因为字级和词级在修饰策略上存在较大的差异。另一方面,这种拼写检查方法也不适用于基于其他语言的对抗样本。
B. 对抗训练
将对抗样本与相应的原始样本混合作为训练数据集来训练模型。通过这种方法可以在一定程度上检测出对抗性实例,但对抗性训练方法并不总是有效。在文本中,通过对抗性训练[24],有一些针对攻击的有效工作,[43],[45]。然而,它在[49]的工作中失败了,主要是由于产生对抗样本的方法不同。前者的修改是插入、替换、删除和替换,后者采用遗传算法。
过度拟合可能是对抗训练方法不总是有用的另一个原因,而且可能只对其相应的攻击有效。Tram er等[84]在图像域中已经证实了这一点,但在文本中还有待证明。
c.针对对抗样本进行模型增强
提高模型的鲁棒性是另一种方法。Goren等[85]为了提高对Web检索设置中文档小扰动的排序鲁棒性,形式化分析、定义并量化了基于线性学习到排序的关联排序函数的鲁棒性概念。他们将分类鲁棒性的概念[7][86]应用于排序函数,并定义了点态鲁棒性、成对鲁棒性和方差猜想等相关概念。量化排序函数的鲁棒性,肯德尔s -τ距离[87]和变化作为归一化措施。最后,实证结果支持了作者对两个排序函数家族的分析的有效性[88],[89]。
(概念看一下)
D.总结防御方法
虽然上述方法在各自的工作中取得了较好的效果,但也存在一定的局限性。拼写检查策略在单词级和句子级的对抗样本中是无用的。对抗性训练存在着过度拟合的问题,在面对新的攻击方法时,对抗性训练将失效。模型增强可能是未来主要的防御策略,但仍在探索中。损失函数的选择和模型结构的修改等存在很多困难。
6 测试和验证是防御对抗攻击的关键领域
测试和验证技术帮助我们从另一个角度处理问题。通过它,人们可以很好地了解基于DNNs的系统的安全性和可靠性,并决定是否采取措施来解决安全问题或其他事情。下面介绍的这些方法还没有在文本中应用,但是发现缺陷和提高健壮性的思想可以作为参考。
A. 针对对抗样本的测试方法
从两个方面对DNNs的测试技术进行综述:测试标准和测试用例生成。
1)测试用例生成: Pei等人设计了一个白盒框架DeepXplore,利用神经元覆盖率的度量来测试真实世界的DNN,并利用差分测试来捕捉多个DNN之间对应输出的差异。为了获得较高的神经元覆盖率,他们生成了对抗样本。通过这种方式,DeepXplore可以触发模型的大多数逻辑,无需人工操作就可以发现不正确的行为。它在先进的深度学习系统中表现良好,发现了数千个导致系统崩溃的角落案例。DeepXplore的局限性在于,如果所有的DNN都做出了错误的判断,那么就很难知道哪里出了问题以及如何解决它。
Wicker等人[921]提出了一种基于特征引导的方法来测试DNNs在黑盒场景中对抗样本的恢复能力。他们将对抗样本的生成过程看作是基于蒙特卡罗树搜索(MCTS)算法的渐近最优策略的二人回合随机对策。在这个策略中,有一个奖励的概念,即在游戏过程中积累对抗样本。通过这些发现,作者可以评估对抗例子的鲁棒性。(重点看一下)
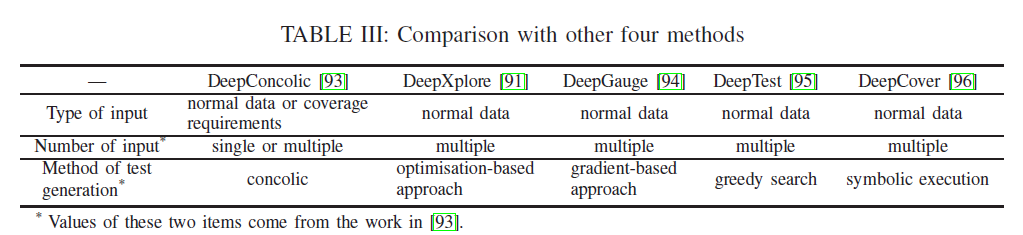
Sun等[93]还提出了深度共线来评估已知DNNs的鲁棒性,这是首次尝试将传统的共线测试方法应用于这些网络。DeepConcolic迭代地使用具体的执行和符号分析来生成测试套件,以达到高覆盖率,并通过健壮的oracle发现了对抗样本。与表3的其他测试方法91、94-196相比,在输入数据方面,DeepConcolic可以从单个输入开始,达到更好的覆盖率,或者使用覆盖率要求作为输入。在性能方面,DeepConcolic可以实现比DeepXplore更高的覆盖率,但运行速度比它慢。
2)测试标准:与单神经元覆盖率不同,Ma等[94]提出了一种多粒度测试覆盖率标准,用于测量准确度和检测错误行为。他们利用[8],28],30,[34]四种方法生成对抗性试验数据,探索模型新的内部状态。覆盖率的增加表明,覆盖率越大,检查缺陷的可能性就越大。Budnik等人也做了类似的工作。通过对抗性案例生成方法,探索被测模型的输出空间。为了解决神经元覆盖的局限性,Kim等[98]提出了一种新的测试充分性准则,称为深度学习系统(SADL)测试DNNs的Surprise Adequacy。 ???
该方法测量输入与训练数据之间的不同行为,是充分性准则的基础。实验结果表明,该方法可以判断输入是否为对抗样本。另一方面,它还可以通过再训练提高DNNs对对抗样本的准确性。
B. 针对对抗样本的验证方法
研究人员认为,测试不足以保证DNN的安全性,特别是在对抗样本等不寻常输入的情况下。正如Edsger W. Dijkstra曾经说过的,测试显示的是bug的存在,而不是bug的缺失。因此,需要对DNNs的验证技术来研究对抗环境下更有效的防御方法。Pulina等人[991]是第一个为神经网络开发小型验证系统的人。此后,相关工作相继出现。但机器学习模型对对抗样本的鲁棒性验证仍处于起步阶段。相关方面的研究较少。我们将其分为基于搜索、全局最优化和超近似方法三个方面。
1) Global optimisation approach
Katz等[101]提出了一种基于可满足性模理论(SMT)求解器的新型DNNs验证系统Reluplex[102]。他们将验证转化为带有整流线性单元(ReLU)激活函数的线性优化问题[103]。在ACAS Xu网络上,Reluplex可以找到具有局部对抗性鲁棒性的对抗性输入,但是在全局变异体的大型网络上失败了。
对于ReLU网络,部分研究将验证问题视为混合整数线性规划(MILP)问题,如Tjeng等[104]。他们从最小抗扰失真[105]和抗扰测试精度[106]两个方面评估了抗扰样本的鲁棒性。他们的工作比具有高对抗性测试精度的Reluplex更快,但同样的限制是,将其扩展到大型网络仍然是一个问题。
与现有的基于求解器的方法(如SMT)不同,Wang等[107]提出了ReluVal方法,该方法利用区间算法[108]来保证DNNs在对抗样本存在时的正确操作。他们反复对输入间隔进行分区,以确定相应的输出间隔是否违反了安全属性。相比之下,该方法比Reluplex方法更有效,在寻找对抗性输入方面表现良好。
2) Search based approach
Huang等人[109]提出了一种新的验证框架,该框架也基于SMT来验证神经网络结构。它依赖于搜索空间的离散化和对各层输出的分析来搜索对抗性扰动,但作者发现SMT理论在实际中只适用于小网络。另一方面,这个框架受到许多假设的限制,其中的一些功能是不清楚的与其他工作不同,Narodytska等[1101]验证了二值化神经网络(BNNs)的安全性。他们利用反例导向搜索为了研究模型的鲁棒性和均衡性,他们提出了一种基于精确布尔编码的程序,并与现代SAT求解器进行了比较。通过Gen和Ver两种编码结构判断模型的输入是否为对抗样本。它可以很容易地为MNIST数据集中95%的经过考虑的图像找到对抗样本。但这种方法也适用于中等规模的BNN网络,而不是大型网络。
3) Over-approximation approach
Gehr等113介绍了一种抽象变压器,它可以得到具有ReLU的卷积神经网络中各层的输出,包括ully连接层。作者对该方法进行了评估,验证了预训练防御网络[114]DNNs的鲁棒性。结果表明,可以有效地防止FGSM攻击。他们还在小型和大型网络上与Reluplex进行了一些比较。在验证性能和时间消耗方面,Reluplex的性能比它差。
Weng等[115]设计了两种算法,分别通过线性逼近和局部Lipschitz常数的边界求出最小对抗性失真的下界。该方法可应用于防御工程,特别是对抗训练,以评价其有效性。
(这一章的内容感觉很多不是特别了解)
7 讨论
A. 对抗性文本的一般观察
在某些方法中使用拼写错误的单词的原因:使用拼写错误的单词的动机类似于图像,它的目的是用无法识别的干扰来欺骗目标模型。一些方法倾向于进行字符级修改操作,这将严重导致拼写错误。在书面语言中,人类对这种情况的反应非常强烈。
黑盒场景中的可转移性:当无法访问目标模型(包括探测目标模型)时,训练一个替代模型并利用对抗样本的可转移性。Szegedy等人[7]首先发现,由神经网络生成的对抗性例子也可能使另一个模型在不同的数据集上表现不佳。这反映了对抗样本的可转移性。因此,在替代模型中产生了对抗样本用于攻击目标模型,而模型和数据集都是不可访问的。除此之外,构建具有高可转移性的对抗样本是评价黑盒攻击有效性的前提,也是评价广义攻击的关键指标[117]。所有的对抗样本都面临着这样的挑战。
B. 存在的问题
对抗攻击和防御的困难:这个问题有很多原因,其中一个主要原因是没有一种直接的方法来评估提议的工作,无论是攻击还是防御。也就是说,在最近的文章中没有令人信服的基准。在一个场景中,一个好的攻击方法可能在另一个场景中失败,或者新的防御方法很快就会以超出防御者预期的方式被击败。虽然有一些文章是可以证明是健全的,但是在处理对抗样本的问题时,仍然需要严谨的理论支持。
攻击或防御性能评价问题:近年来,大多数研究都是通过成功率或准确性来评价攻击或防御性能。只有少数工作[24],[45]考虑规模和效率,即使他们只是列出了攻击所消耗的时间。目前还不清楚数据集的规模、消耗的时间和对抗攻击的成功率之间是否存在关系。如果存在这样的关系,这三个方面的权衡可能是未来工作的一个研究重点。防御也有类似的情况。
C. 挑战
没有一种生成对抗样本的通用方法:由于近年来对抗样本在文本中的应用成为一个前沿,对抗攻击的方法相对较少,更不用说防御了。这种方法不存在的另一个原因是语言问题。几乎所有最近的方法都使用英语数据集,生成的对抗示例对于使用中文[118]或其他语言数据集的系统可能是无用的。因此,没有一种通用的方法来生成对抗样本。但在我们的观察中,许多方法主要遵循两步的过程来生成对抗样本。第一步是找出对分类结果有重要影响的关键词,然后进行相应的修改,得到对抗样本。
缺乏文本对抗样本研究的标准和工具箱:人们提出了各种研究文本对抗攻击和防御的方法,但都没有标准。研究人员使用不同的数据集(II-D)在他们的工作中,导致比较这些方法的优点和缺点的困难。同时,这也影响了度量方法的选择。目前,还没有一个确切的说法,说明哪种度量方法在某种情况下更好,以及为什么它比其他度量方法更有用。虽然在Textbugger[45]中已经进行了比较,但本工作中的度量方法可能适用于它,在其他工作中可能无效。
另一方面,它也缺少一个开源工具箱(例如。AdvBox[119]和cleverhans[120]在图像中)用于文本对抗样本研究。这两个工具箱集成了现有的具有代表性的生成对抗图像的方法。人们可以很容易地通过他们做一些进一步的研究,这减少了重复的时间消耗,促进了该领域研究的发展。
8 结论和未来方向
本文对文本中DNNs的对抗攻击和防御进行了综述。尽管DNNs在各种NLP上都有很高的性能,但其本身就容易受到对抗性例子的攻击,这引起了人们的高度关注。这篇文章综合了几乎现有的对抗性攻击和一些防御措施,重点放在最近的工作。从这些工作中,我们可以看出,对抗性攻击的威胁是真实存在的,防御手段是很少的。现有的工作大多有其局限性,如应用场景、约束条件和方法本身存在的问题。应更多地注意对抗样本的问题,这仍然是设计相当健壮的模型来抵抗对抗攻击的一个悬而未决的问题。
我们可以对反对抗样本做的进一步研究可能是:作为一个攻击者,可以像在图像[31]中一样考虑设计通用扰动来捕获更好的对抗样本。任何文本上的普遍对抗性扰动都能使模型发生高概率的行为失当。此外,更多奇妙的普遍扰动可以欺骗多模型或任何文本上的任何模型。另一方面,增强对抗性实例的可移植性的工作对于更实际的后箱攻击是有意义的。相反,防御者更倾向于彻底修补DNNs的这一漏洞,但这并不比重新设计一个网络容易,也是一项长期而艰巨的任务,需要许多人的共同努力。目前,防御者可以利用从图像区域到文本的方法来提高DNNs的鲁棒性,如对抗性训练[114]、添加额外的层[121]、优化交叉熵函数[122]、[123]或者削弱对抗性例子的可移植性。
(图像里对抗样本经典的方法要看看,尝试移植到NLP)