第一章 绪论
问题的提出
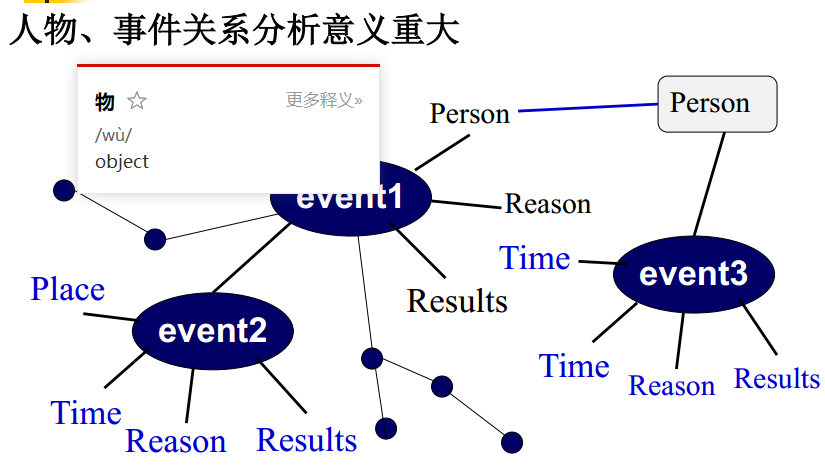

基本概念: NLU、 CL、 NLP



CL 计算语言学 侧重于: 基础理论和方法
NLU 自然语言理解 :模仿人类 自然语言处理方法 和 实现技术
NLP 自然语言处理 : 对语言文本进行处理和加工 包括对词法 句法 语义和语用等信息的识别 分类 提取 转换和僧成等各种处理方法和实现技术
研究内容、主要问题和困难









研究内容:
机器翻译:实现一种语言到另一种语言的自动翻译。
应用:文献翻译、网页辅助浏览等。
信息检索:信息检索也称情报检索,就是利用计算机系统从大量文档中找到符合用户需要的相关信息。
自动文摘:将原文档的主要内容或某方面的信息自动提取出来,并形成原文档的摘要或缩写。
观点挖掘。
应用:电子图书管理、情报获取等。
问答系统:通过计算机系统对人提出的问题的理解,利用自动推理等手段,在有关知识资源中自动求解答案并做出相应的回答。问答技术有时与语音技术和多模态输入/输出技术,以及人机交互技术等相结合,构成人机对话系统。
社区问答。
信息过滤:通过计算机系统自动识别和过滤那些满足特定条件的文档信息。
信息抽取:从制定文档中或者海量文本中抽取出用户感兴趣的信息。
实体关系抽取。
社会网络。
文档分类:也叫文本自动分类或信息分类,其目的就是利用计算机系统对大量的文档按照一定的分类标准(例如,根据主题或内容划分等)实现自动归类。
情感分类:应用:图书管理、情报获取、网络内容监控等。
文本编辑和自动校对:对文字拼写、用词、甚至语言、文档格式等进行自动检查、校对和编排。
应用:排版、印刷和书籍编撰等。
语言教学
文字识别
语音识别:将输入语音信号自动转换成书面文字。
应用:文字录入、人机通讯、语音翻译等等。
困难:大量存在的同音词、近因词、集外词、口音等等。
文语转换/ 语音合成:将书面文本自动转换成对应的语音表征。
应用:朗读系统、人机语音接口等等。
说话人识别/认同/验证:对一言语样品做声学分析、依次推断(确定或验证)说话人的身份。
应用:信息安全、防伪等等。
由于不同的研究方向所关注的侧重点不同,因此,一般将语音识别、语音合成和说话人识别等以语音信号为主要研究对方的语音技术独立出来,而其他以文本(词汇/句子/篇章等)为主要处理对象的研究内容作为自然语言处理的主体。
文字识别更多地涉及图像识别与理解的问题。信息检索与自然语言处理之间既有密切关联,又各自相对独立。




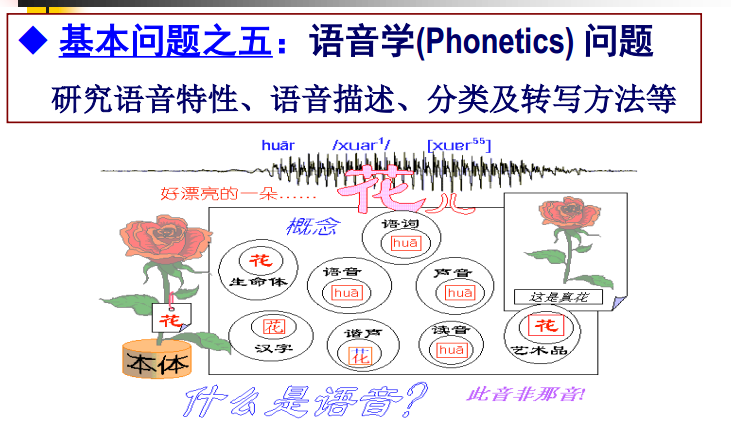
基本问题
形态学问题 : 研究词由有意义的基本单位——词素的构成问题。
句法问题 : 研究句子结构成分之间的相互关系和组成句子序列的规则。
语义问题 :研究如何从一个语句中词的意义,以及这些词在该语句中句法结构中的作用来推导出该语句的意义。
语用学问题: 研究在不同上下文中语句的应用,以及上下文对语句理解所产生的影响。从狭隘的语言学观点看,语用学处理的是语言结构中有形式体现的那些语境。相反,语用学最宽泛的定义是研究语义未能涵盖的那些意义。
语音学问题: 研究语音特性、语音描述、分类及转写方法等。

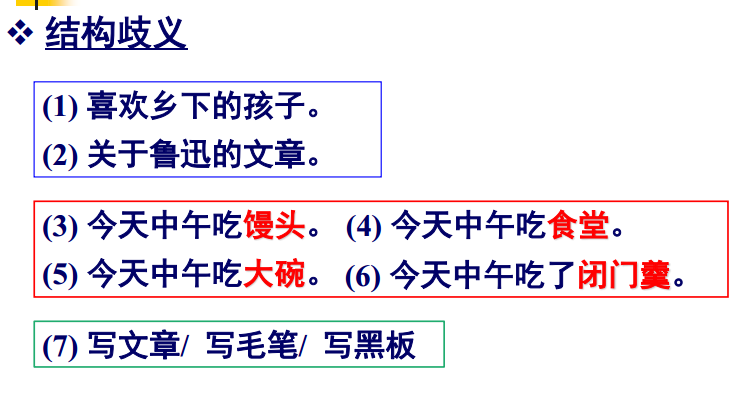






主要困难
大量歧义现象: 词法、词性、结构、语义、语音、多音字及韵律等歧义
大量未知语言现象:新词、人名、地名、术语等;新含义;新用法和新句型等
NLU所面临的挑战:
普遍存在的不确定性
未知语言现象的不可预测性
始终面临的数据不充分性
语言知识表达的复杂性
机器翻译中映射单元的不对等性
研究方法概要


基本研究方法
理性主义:通常通过一些特殊的语句或语言现象的研究来得到对人的语言能力的认识,而这些语句和语言现象在实际的应用中并不常见。
基本思路:基于规则的分析方法建立符号处理系统
知识库+推理系统 -> NLP系统
理论基础:Chomsky的文法理论
经验主义:偏重于对大规模语言数据中人们所实际使用的普通语句的统计。
思路:基于大规模真实预料(语言数据)建立计算方法
语料库 + 统计模型 -> NLP系统
理论基础:统计学、信息论、机器学习
以机器翻译为例
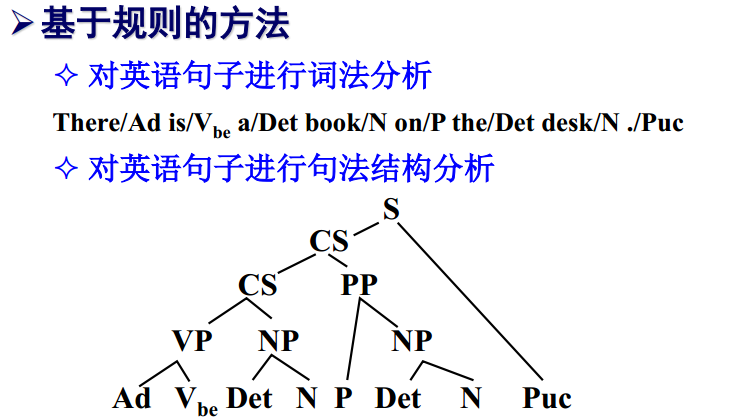
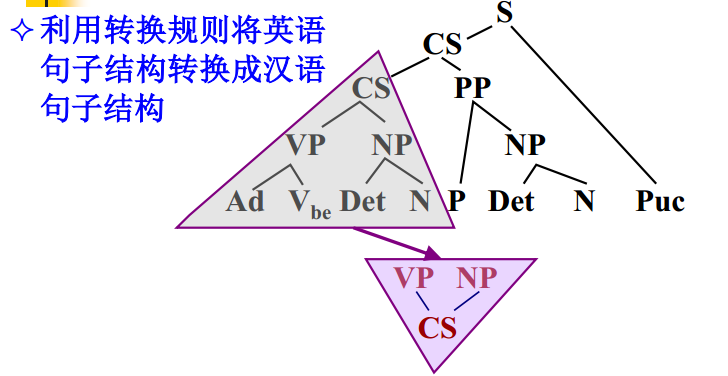


基于规则的方法
词法分析 结构分析 结构转换 生成翻译
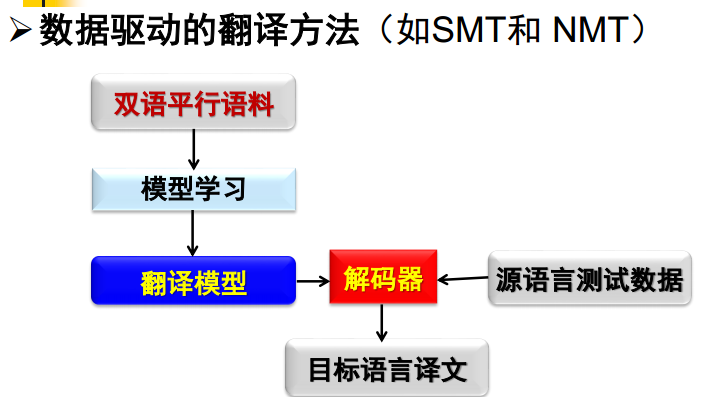
数据驱动的翻译方法(如SMT和NMT)
双语平行预料 模型学习 翻译模型 利用测试数据训练解码器 目标语言译文
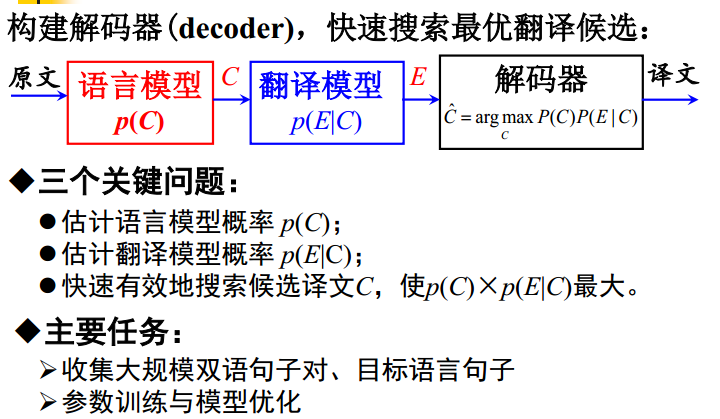
基于统计的方法
语言模型 翻译模型 贝叶斯公式
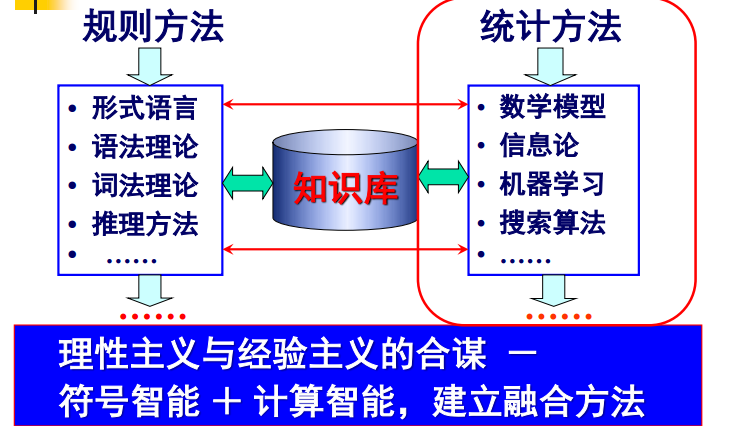
主要是 理性主义 经验主义
方法主要是 规则方法 统计方法
它们也可以相结合 就是 符号智能 + 计算智能 建立融合方法