一、日志收集系统原理说明:
1.filebeat安装在产生日志的服务器,它是轻量级的日志收集器,对服务器资源的消耗几乎可以忽略
2.filebeat收集的日志发送到redis队列,redis主要作用是缓冲,因logstash的传输能力有限,如果各个服务器 filebeat传输的日志量过大有可能产生堵塞导致信息丢失或者服务崩溃,另外logstash也比较消耗服务器资源

二、服务器规划
1.准备了两台服务器,两台服务器都是16核64G,系统盘100G另挂一个500G的数据盘 (可以说是土豪级的配置了)
110.1.2.81 安装 elasticsearch、logstash、kibana、nginx(主要kibana没有权限管理,要使用nginx添加访问权限)
110.1.2.82 安装 redis
filebeat 安装在业务服务器上
三、安装及配置
1.版本这里elk及filebeat统一选择 5.6.10 ,redis 4.0.9,很多地方都说elk要求是统一版本
2.安装没什么说的,官网下载对应的包: 官网地址

3.filebeat安装配置
filebeat安装很简单,我这里是Ubuntu系统,下载的是 5.6.10版本
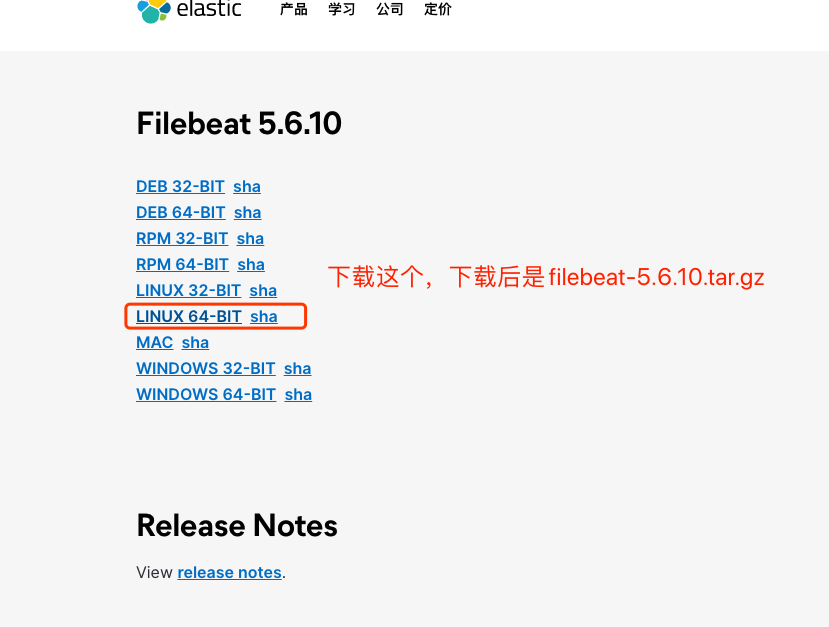
下载之后解压,我这里放在了 /usr/servers/ 文件夹下,并且重命名为 filebeat,编辑filebeat.yml配置文件,启动即可
启动命令:
#切换到filebeat目录 cd /usr/servers/filebeat #启动 在后台启动加 & ./filebeat &
*********到了关键的配置文件讲解了*******
这里是filebeat采集日志文件后存入redis队列,然后由logstash去redis消费
filebeat配置:
#=========================== Filebeat prospectors =============================
filebeat.prospectors:
#这里每个 input_type 对应一个日志文件收集 这里配置了两个一个是管理后台的(guanyu-platform)一个是小程序的(guanyu-server-minapp)
- input_type: log
enabled: true
#日志文件路径,支持通配符,如 /root/* 或 /root/test-*.log
paths:
- /root/server/logs/guanyu-platform-*.log
#这里是关键,后面logstash要根据 fields.log_type 判断不同的文件来创建不同的索引(index)
fields:
log_source: guanyu-platform_prod
log_type: guanyu-platform_prod
- input_type: log
enabled: true
paths:
- /root/server/logs/guanyu-server-minapp-*.log
fields:
log_source: guanyu-server-minapp_prod
log_type: guanyu-server-minapp_prod
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
#这里配置是说日志输出到redis, host、port、password、db都没啥说的
output.redis:
hosts: ["110.1.2.82"]
port: 6379
password: 123456
db: 0
#这里key是关键,key是default_list,看官网含义就是不设置固定的key,而是所有的key根据下面条件动态匹配!
key: "default_list"
keys:
#第一条含义:如果source包含 "guanyu-platform" ,则存到redis里key是guanyu-platform_prod
- key: "guanyu-platform_prod"
when.contains:
source: "guanyu-platform"
- key: "guanyu-server-minapp_prod" # send to debug_list if `message` field contains DEBUG
when.contains:
source: "guanyu-server-minapp"
4.redis安装网上搜个按步骤安装就行
filebeat启动之后,这是redis里就可以看到发送过来的队列了:
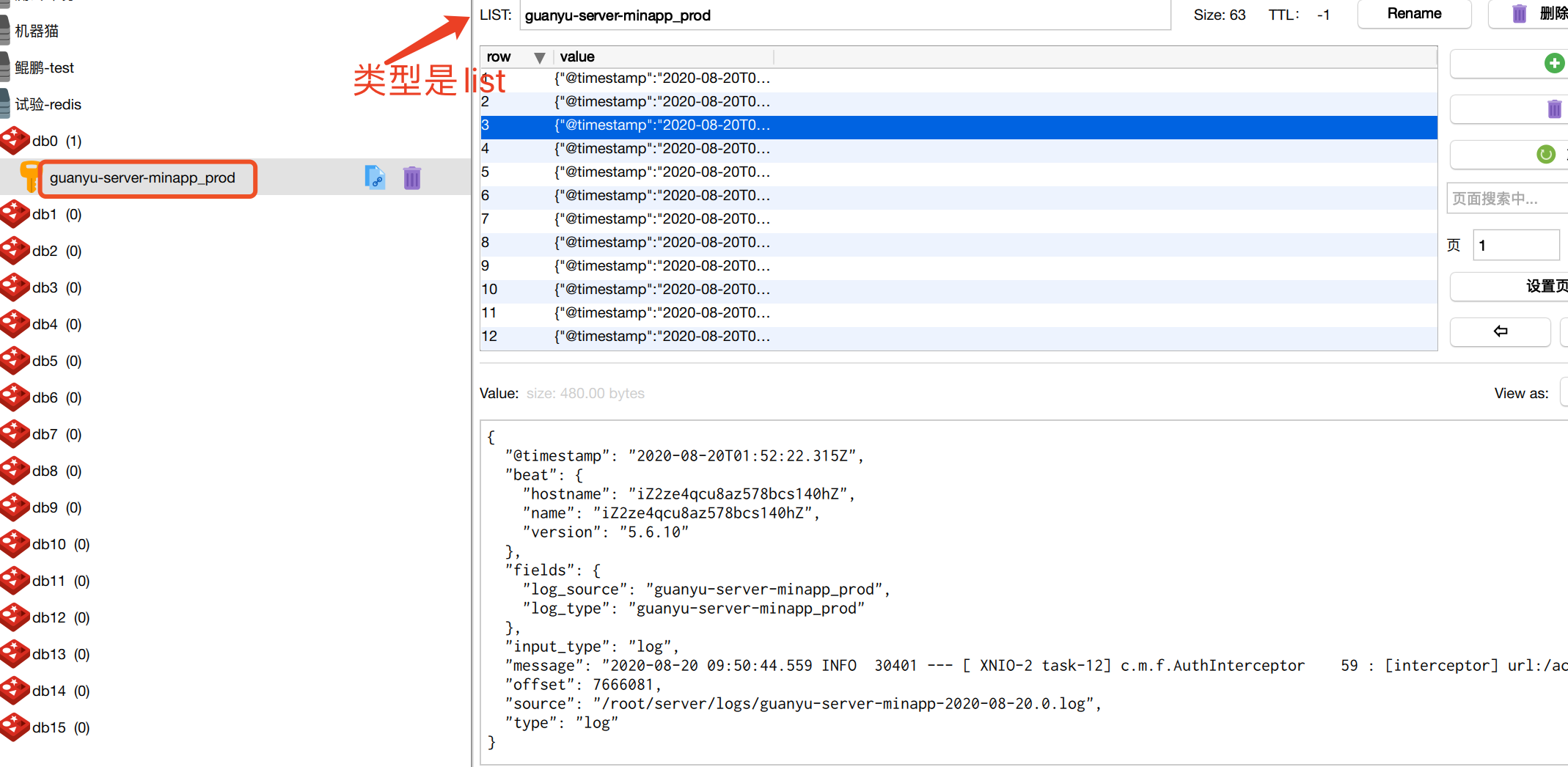
5.logstash安装与配置
logstash安装基本和filebeat相同,官网下载安装包,解压到某个目录( 我这里放在了 /usr/servers/logstash )
主要说下配置,我这里专门建了一个目录 /usr/servers/conf.d 文件名 total.conf
启动命令:
#启动命令
/usr/servers/logstash/bin/logstash -f /usr/servers/conf.d/
配置文件:
input { redis { port => "6379" host => "110.1.2.82" password => "123456" data_type => "list" key => "guanyu-server-minapp_prod" } redis { port => "6379" host => "110.1.2.82" password => "123456" data_type => "list" key => "guanyu-platform_prod" } redis { port => "6379" host => "110.1.2.82" password => "123456" data_type => "list" key => "middleplatform-log_prod" } redis { port => "6379" host => "110.1.2.82" password => "123456" data_type => "list" key => "shell-middleplatform_test" } redis { port => "6379" host => "110.1.2.82" password => "123456" data_type => "list" key => "corn-middleplatform_test" } } output { if [fields][log_type] == "guanyu-server-minapp_prod" { elasticsearch { hosts => "110.1.2.81:9200" index => "guanyu-server-minapp_prod-%{+YYYY.MM.dd}" action => "index" } } if [fields][log_type] == "guanyu-platform_prod" { elasticsearch { hosts => "110.1.2.81:9200" index => "guanyu-platform_prod-%{+YYYY.MM.dd}" action => "index" } } if [fields][log_type] == "middleplatform_prod" { elasticsearch { hosts => "110.1.2.81:9200" index => "middleplatform_prod-%{+YYYY.MM.dd}" action => "index" } } if [fields][log_type] == "shell-middleplatform_test" { elasticsearch { hosts => "110.1.2.81:9200" index => "shell-middleplatform_test-%{+YYYY.MM.dd}" action => "index" } } if [fields][log_type] == "corn-middleplatform_test" { elasticsearch { hosts => "110.1.2.81:9200" index => "corn-middleplatform_test-%{+YYYY.MM.dd}" action => "index" } } }
说明:
1、input是从redis读取,除了redis连接信息基本配置,就是key的设置,每个key对应一个redis配置,date_type这里设置为list
date_type官网是这样解释的 Value can be any of: list, channel, pattern_channel Specify either list or channel. If redis\_type is list, then we will BLPOP the key. If redis\_type is channel, then we will SUBSCRIBE to the key. If redis\_type is pattern_channel, then we will PSUBSCRIBE to the key.
2、output是日志输出位置,这里是输出到elasticsearch,且根据[fields][log_type]值不同建立不同的索引。[fields][log_type] 是在filebeat收集时设置的,可以看上面第3步filebeat配置。
6.elasticsearch的安装与配置
安装基本与filebeat和logstash一样,注意下载相同的版本即可
elasticsearch配置比较简单,主要有以下:
#数据 存放地址 path.data: /mnt/sdc/data/elasticsearch # # Path to log files: #日志存放地址 path.logs: /var/log/elasticsearch # # ---------------------------------- Network ----------------------------------- # # 设置允许访问的IP,0.0.0.0代表任何IP均可访问 # network.host: 0.0.0.0 # # 设置端口号,及跨域 # http.port: 9200 http.cors.enabled: true http.cors.allow-origin: "*"
7.kibana安装与配置
安装也是下载包解压(有什么依赖则需提前安装),配置文件如下:
# Kibana is served by a back end server. This setting specifies the port to use. server.port: 5601 # Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values. # The default is 'localhost', which usually means remote machines will not be able to connect. # To allow connections from remote users, set this parameter to a non-loopback address. server.host: "0.0.0.0" # The URL of the Elasticsearch instance to use for all your queries. elasticsearch.url: "http://110.1.2.81:9200"
四、使用
1.kibana访问地址 IP+5601
2.创建索引: management -> index patternns -> create index pattern 如下图:
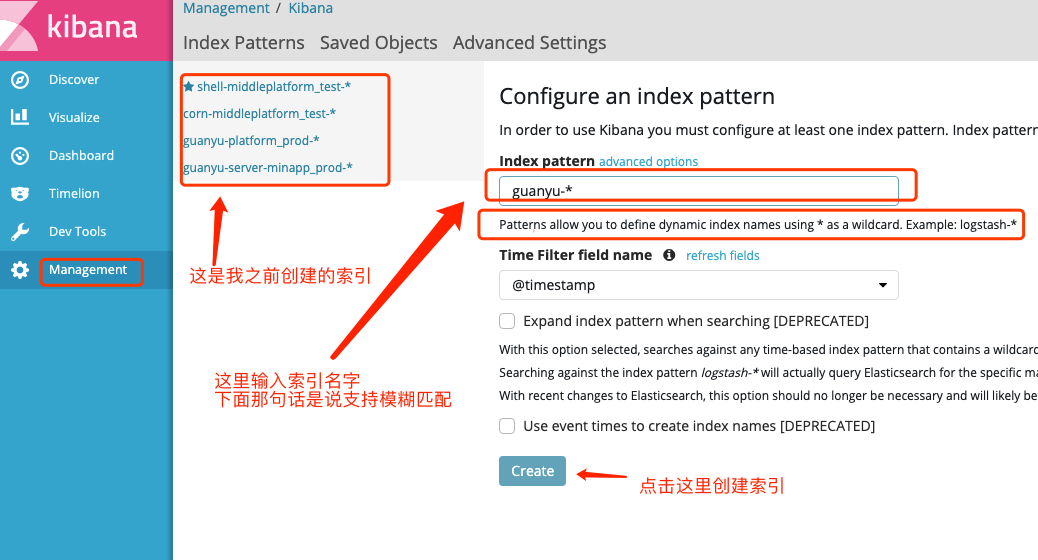
注意:索引必须是已存在的,否则会有红色警告
3.查看索引 -> discover
a、首先右上角选择时间段,默认的是 last 15 minutes,你可以快速选择当天、昨天、过去30天等(quick),也可以设置具体时间段(absolute)
b、选择索引,你可能会创建多个索引,每次只能选择查看一个
c、添加筛选条件(可选),即 add a filter,这个还是比较有用的。
看下图,这是不是比你自己打开日志文件方便多了
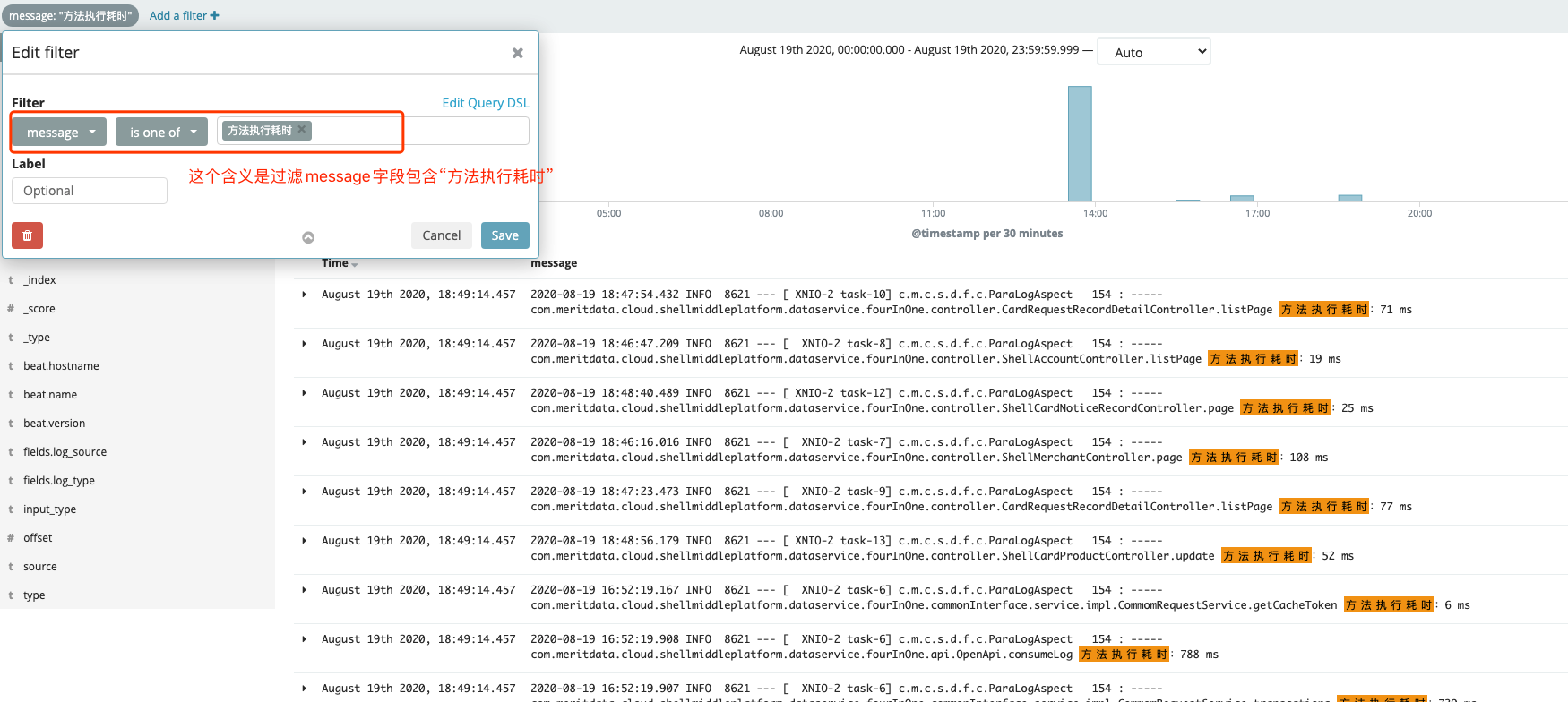
d、我们的日志内容一般存在message字段里,在 available fields 里把message add 进去,它是我们实际要看的
e、也可以按time排序(正序、倒序)
以上初步实现日志的收集和查看,包括搜索
----------------------------------------------------------------------------
有个问题就是kibana没有权限控制,即只要知道IP+端口号就可以访问,不需要用户名和密码,这个可以用nginx实现用户名和密码访问,后面补充