word2vec简介
word2vec是把一个词转换为向量,变为一个数值型的数据。
主要包括两个思想:分词和负采样
使用gensim库——这个库里封装好了word2vector模型,然后用它训练一个非常庞大的数据量。
自然语言处理的应用
拼写检查——P(fiften minutes)>P(fiftenminutes),然后依据这些进行纠错
关键词检索
文本挖掘
文本分类——体育类?新闻类?
机器翻译——通过之前学习到的信息进行概率分析
客服系统——人工客服
复杂对话系统——微软小冰,长时间的交流
语言模型
我 今天 下午 打 篮球
P(s)=p(w1,w2,w3,...,wn)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
P(s)被称为语言模型,即用来计算一个句子概率的模型。
p(wi|w1,w2,...,wi-1)=p(w1,w2,...,wi-1,wi)/p(w1,w2,...,wi-1)
即预测一个词,这个词和之前所有的词都相关。
导致的问题:
1.数据过于稀疏——一个词和之前相关的词的数量较少
2.参数空间太大——数据过于稀疏造成。
解决办法:
1.假设下一个词的出现依赖它前面的一个词:
p(s)=p(w1)p(w2|w1)p(w3|w1,w2)..p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w2)...p(wn|wn-1)
2.假设下一个词的出现依赖它前面的两个词:
p(s)=p(w1)p(w2|w1)p(w3|w1,w2)..p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|wn-1,wn-2)
这样的解决办法称为:n-gram模型,指定n为2,表示当前词与之前的两个词有关。
n-gram模型
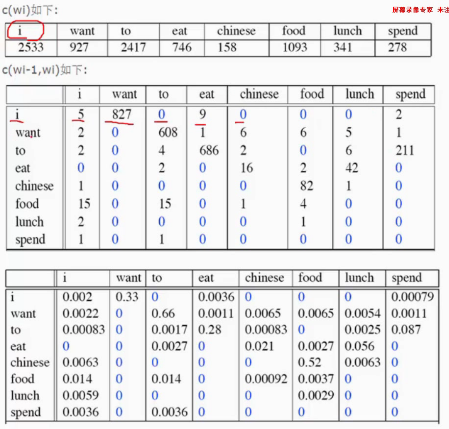
通过这个表计算p(I want chinese food)=p(want|I)*p(chinese|want)*p(food|chinese)
第一个表是统计文章中每个词出现的频率;
第二个表是统计每个词与其他词一起出现的概率(n=1),比如当i时,第二个词也出现i有5词,第二次出现want有827个词,第二次出现to有0词;
第三个表求的是近似概率,p(want|I)=p(I,want)/p(I)=827/2533=0.33
那么p(I want chinese food)=p(want|I)*p(chinese|want)*p(food|chinese)就可以根据第三个表求出来。
这个模型的复杂度为:

N表示语料库的大小,n表示n-gram中的n,与前几个词有关。我们一半选择n为2和3就可以了,当n太大的时候就很难计算了,虽然现在的计算机能力能够计算n为10的情况,但是没有必要花这么的计算量提高比较小的性能,一半n为2和3就够用了。
词向量
无论是一句话还是一篇文章,都是一个词一个词组成的,这是基本单位,怎么让机器认识他们呢?
1.one-hot转换方式,有多少个词就有多少个位数,词对应位置就是1,其余位为0,但是这样缺少词与词之间的关系;
2.word2vec,这是我们现在用的比较好的模型。
这是word2vec的样子:

其空间结构如下:

我们可以看到had,has,have意思相近,其向量空间的位置也相近 ,need和help经常一起出现的,也会挨的比较相近。
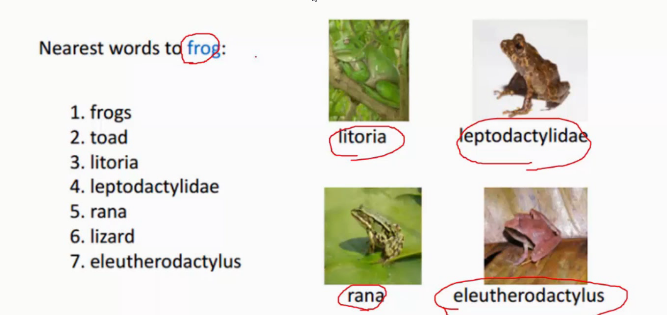
现在我们想知道谁和青蛙挨的比较近:
比如说,‘今天的菜比较便宜’和‘今天的菜比较贱’其实表达的都是一个含义,在语言中许多相近的词,需要让计算机知道这是说的一回事儿。
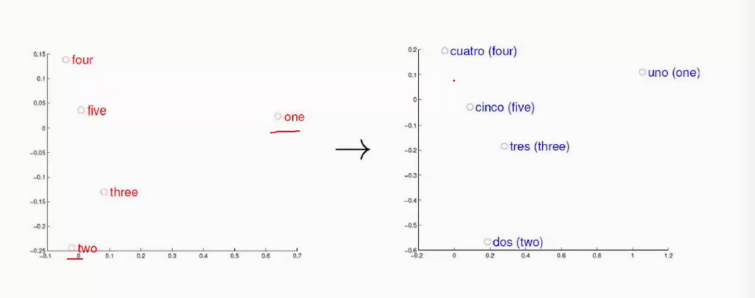
下边左边是英语的数字右边是西班牙语的数字,构造出来的空间结构也是相似,这说明word2vec构造出来的模型与语言无关,而是与具体的逻辑有关。
神经网络模型
词向量模型与神经网络模型有什么关系呢?
我们把神经网络模型分成四部分:
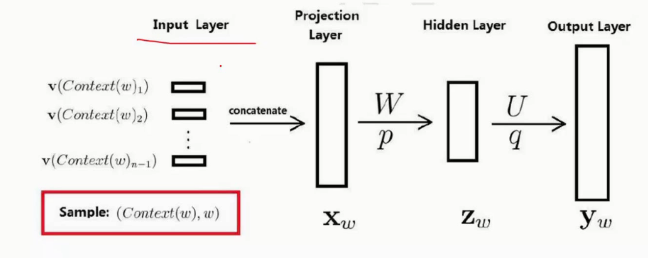
比如我输入:‘我’,‘今天’,‘下午’,‘打’然后预测后一个词是什么
如上图所示,
input layer表示的输入层,
第二个是projection layer,即投影层,我们要把输入的词首尾相连组合在一起,这里和传统神经网络不一样,我们这里我们要求出来神经网络每个层之间的参数和输入,传统的神经网络只要求神经网络层之间的参数即可。
第三个是隐藏层
最后一个是输出层

根据最后的输出进行优化。
神经网络模型的优点:

网咖和网吧是同一个词,对于N-gram模型会统计词频,因为词频不一样,所以导致结果不一样,而使用神经网络模型之后,我们发现网咖和网吧在向量空间非常的相近,所以会被认为是一样的。

在神经网络模型看来,狗和猫都是一样的,都是动物再跑,所以会把他们加起来。
Hierarchical softmax
即分层的softmax。
首先对于神经网络的实现有两种形式:
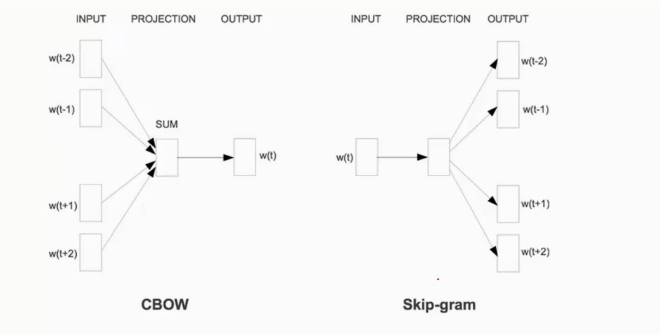
CBOW模型,即continuous bag of words模型,输入的是上下文词,预测的是当前一个词,
设为一个似然函数,希望这个函数越大越好:
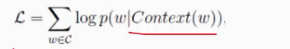
设计这个网络需要用到哈夫曼树
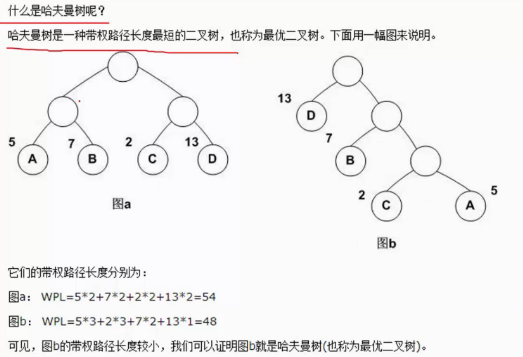
b图把权值最大的放在前边,比如我们整体的语料库有1万个词,我们要在输出层预测一万个词的所有的概率,普通神经网络中我们同等对待他们。但是我们常用的词就那么那么多,我们可以着重关注词频出现次数较多的词,我们在分层softmax中,首先进行一个判断,一个二分类问题(使用sigmoid函数),逐一的进行判断。
Skip-gram模型,输入是当前的词,预测的是这个词的上下文词。
CBOW模型实例
二分类问题就是使用logistic回归。
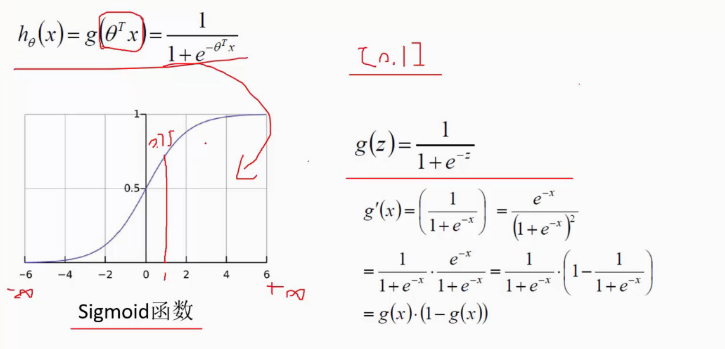
我们用这个的二分类来判断分层softmax中往左子树走还是往右子树走的概率。
首先看一下哈夫曼树中分层softmax的概念:

举个例子:
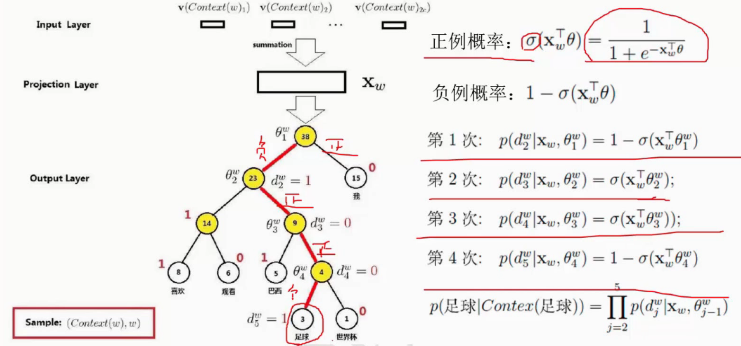
通过上下文,我们想通过神经网络输出‘足球’,我们可以把高频词往上移动,每个节点都是二分类问题。我们预测‘足球’会走途中红线的路径。第一层的softmax往左走,第二层,往右走,第三次右走,第四次是往左走。最后我们要把所有的概率乘在一起。
CBOW求解目标
要求接的内容包括两个部分:输入向量怎么改变,神经网络中的参数怎么改变
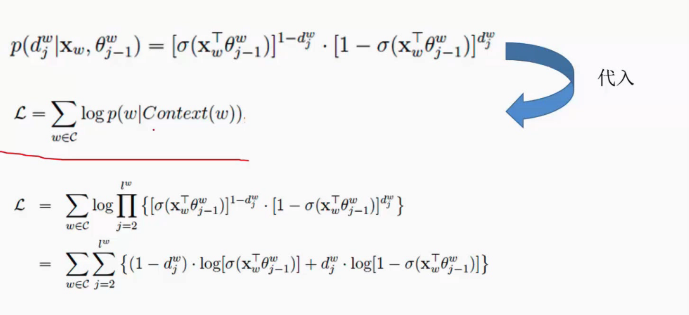
要优化的目标是L似然函数,和logisitic计算类似。
梯度上升求解
既然是求一个最大值的问题,那么就可以用梯度上升进行求解。
分成两部分,分别计算θ和x的更新。下边是它们的更新公式:


负采样模型
即使我们使用哈夫曼树进行解决这个问题,依然面临着问题:当语料库非常大的时候,一些不太常用的词会排到非常后的位置。时间复杂度依然非常的高,为此提出了一个新的解法,即负采样模型——Negative Sampling
给一个上下文,预测对了就是这样一个词,预测错了就不是这个词。
当我们预测‘足球’,我们正样本就是‘足球’,负样本就是非足球的所有词,负样本非常的多。

我们从负样本中进行采样,然后进行最大化即可。

词频越大,越容易被随机采样到。
使用Gensim库构造词向量
Gensim是一个比较好的开源库。
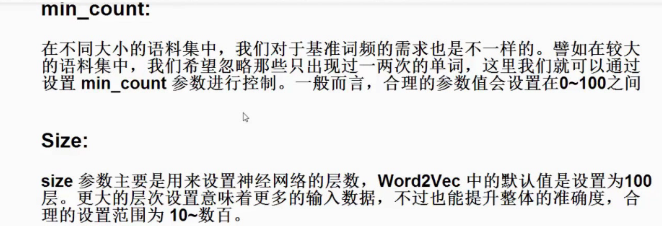
model=word2vec.Word2Vec()中有两个参数常用参数
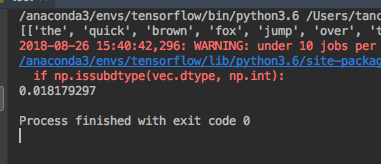
from gensim.models import word2vec import logging logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s') raw_sentences=['the quick brown fox jump over the lazy dogs','yoyoyo you go home now to sleep']#输入两句话 sentences=[s.split() for s in raw_sentences]#分词 print(sentences) #sentences表示用来进行训练的文本,min_count控制某些出现次数较低的词 model=word2vec.Word2Vec(sentences,min_count=1) #输出'dog'和'you'的相似度 print(model.similarity('dogs','you'))
维基百科中文数据处理
维基百科里边有很大的数据,这个网站里又他们收集到的数据,正常我们下载下来的数据都是繁体的,包含大量的信息,比如包括一系列的文章。维基百科和百度百科是类似的,知识百度百科的东西我们无法下载下来。下载格式为:xml.bz2。
网站:https://dumps.wikimedia.org/zhwiki/
但是我们下载下来的内容是繁体的,opencc工具可以用来将繁体转换成中文的。
如果不想用维基百科,用其他的语料库也是可以的,比如用小说等都是可以的。
Gensim构造word2vec模型
jieba分词,每一行都进行分词,如下是使用结巴分词对维基百科的txt文档进行分词,然后将分词结果进行存储。
import jieba import jieba.analyse import jieba.posseg as pseg import codecs,sys def cut_words(sentence): #print sentence return " ".join(jieba.cut(sentence)).encode('utf-8') f=codecs.open('wiki.zh.jian.text','r',encoding="utf8")##需要读入的文件名 target = codecs.open("zh.jian.wiki.seg-1.3ggg.txt", 'w',encoding="utf8")##需要写入的文件名 print ('open files') line_num=1 line = f.readline() while line: print('---- processing ', line_num, ' article----------------') line_seg = " ".join(jieba.cut(line)) target.writelines(line_seg) line_num = line_num + 1 line = f.readline() f.close() target.close() exit()
分词之后就是建模工作,建模工作就是用gensim包进行一个建模工作。
import logging import os.path import sys import multiprocessing from gensim.corpora import WikiCorpus from gensim.models import Word2Vec from gensim.models.word2vec import LineSentence if __name__ == '__main__': ##sys.argv实际上是一个列表,第一个表示程序本身,后边的为程序的参数 program = os.path.basename(sys.argv[0]) logger = logging.getLogger(program) logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s') logging.root.setLevel(level=logging.INFO) logger.info("running %s" % ' '.join(sys.argv)) # check and process input arguments if len(sys.argv) < 4: print (globals()['__doc__'] % locals()) sys.exit(1) inp, outp1, outp2 = sys.argv[1:4]##第二个参数为分好词的txt,第三那个参数是模型保存地址,第四个参数是词向量 ##建模过程挺长的,如果使用的是1g左右的数据,建模过程大概要1个小时左右 ##指定Word2Vec的参数, model = Word2Vec(LineSentence(inp), size=400, window=5, min_count=5, workers=multiprocessing.cpu_count()) model.save(outp1) model.model.wv.save_word2vec_format(outp2, binary=False) #python word2vec_model.py zh.jian.wiki.seg.txt wiki.zh.text.model wiki.zh.text.vector #opencc -i wiki_texts.txt -o test.txt -c t2s.json

测试模型相似度结果
然后我们用我们徐莲好的模型进行测试,输出['苹果','数学','学术','白痴','篮球']词最相近的几个词。
代码如下:
from gensim.models import Word2Vec en_wiki_word2vec_model = Word2Vec.load('wiki.zh.text.model') testwords = ['苹果','数学','学术','白痴','篮球'] for i in range(5): res = en_wiki_word2vec_model.most_similar(testwords[i])##计算这几个词最相近的几个词,默认是前十个词 print (testwords[i]) print (res)
