1. Go语言编译器
- 编译器优化
- 内联函数
很多Go语言的语法特性都离不开编译时与运行时的共同作用。例如开发go import 、 go fmt 、go lint 等扫描源码的工具。
2. Go语言编译器的阶段
three- phase Compiler

IR:Intermediate Representation 编译器的中间阶段
- 识别冗余代码
- 识别内存逃逸
Go 语言编译器一般缩写为小写gc (go compiler),需要区别GC(垃圾回收)进行区分
GO 语言编译器执行流程

3.词法解析
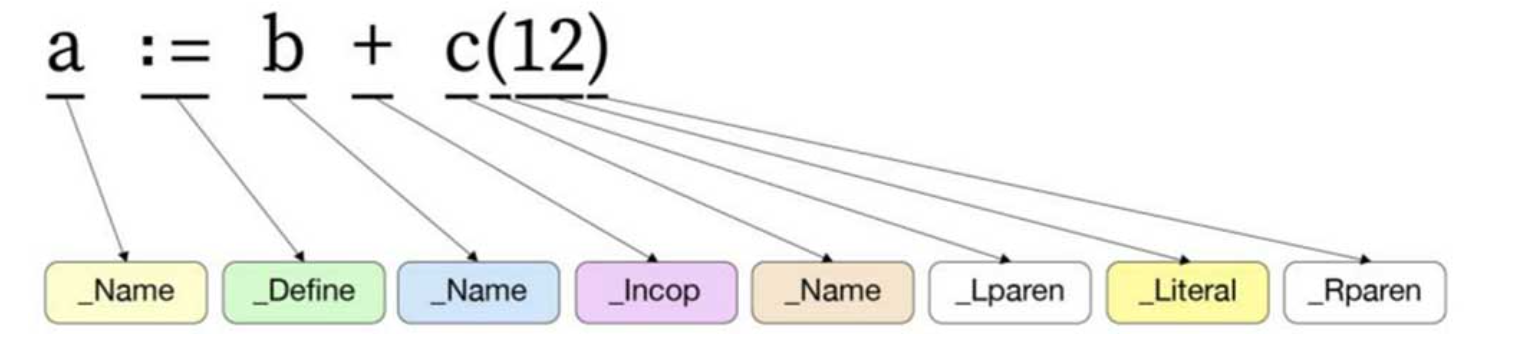
在词法解析阶段,Go语言编译器会扫描输入的Go源文件,并将其符号(token)化。
4.语法解析
Go语言采用了标准的自上而下的递归下降(Top-Down Recursive-Descent)算法,以简单高效的方式完成无须回溯的语法扫描,核心算法位于syntax/nodes.go及syntax/parser.go中。
Golang 的语法分析主要流程由 cmd/compile/internal/gc/noder.go 文件完成,这一步是在词法分析之后,会将 Go 源文件转成 AST
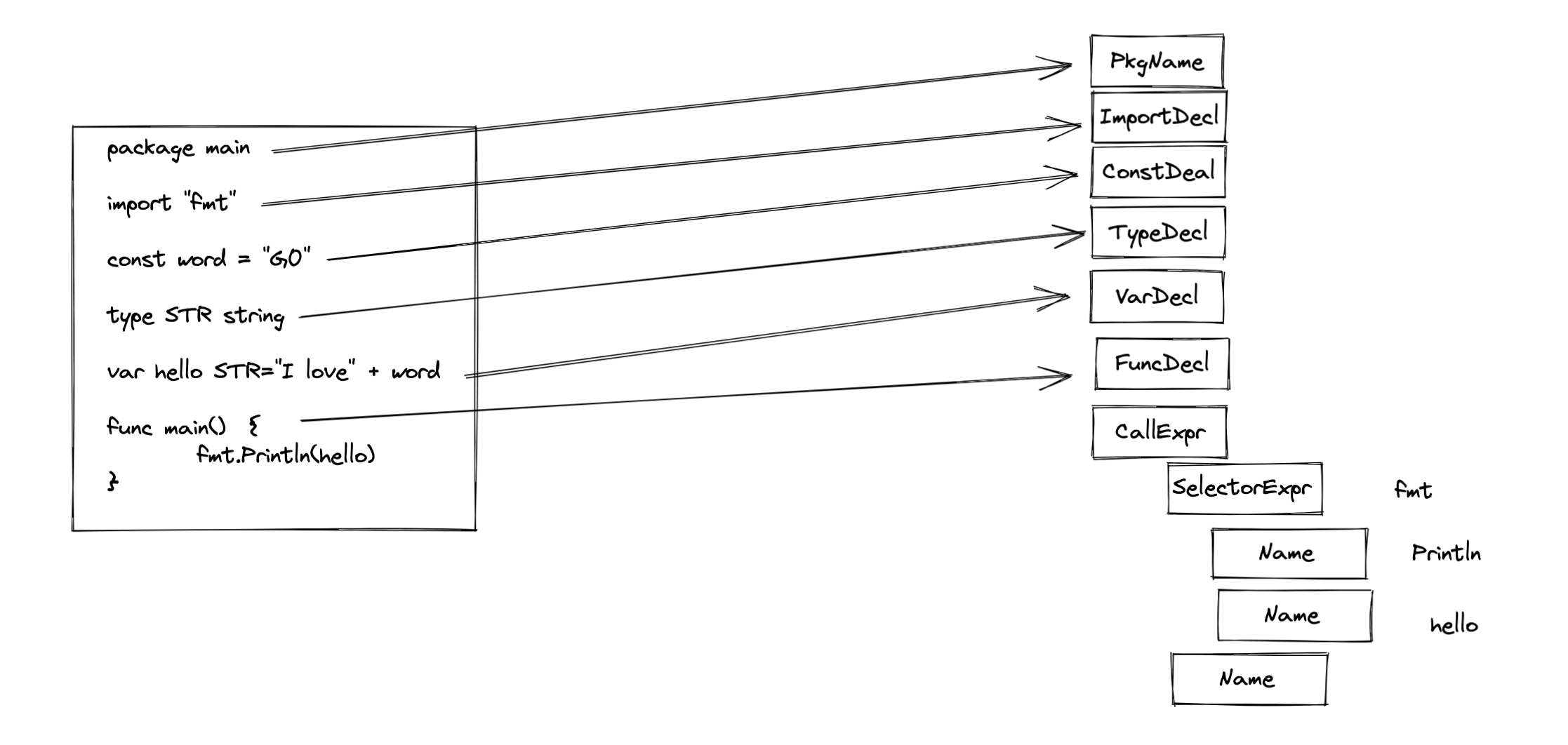
5.抽象语法树构建
如图一,编译器前端必须构建程序的中间表示形式,已便在编译器中间阶段和后端使用。抽象语法树(Abstract Syntax Tree,AST)是一种常见的树状结构的中间态。
Golang 的语法分析主要流程由 cmd/compile/internal/gc/noder.go 文件完成,这一步是在词法分析之后,会将 Go 源文件转成 AST。
// Node 表示AST中的结点,是一个基础结构,用于将整个源代码串起来
type Node struct {
// Tree structure.
// Generic recursive walks should follow these fields.
Left *Node // Left/Right字段可用于保存赋值语句的左值与右值等
Right *Node
Ninit Nodes // Ninit可用于保存if/for等语句的初始化语句
Nbody Nodes // Nbody可用于保存函数体
List Nodes // List可保存函数调用参数,map, slice等结构初始化值
Rlist Nodes // Rlist可保存多重赋值的右值列表
// most nodes
Type *types.Type // 类型
Orig *Node // original form, for printing, and tracking copies of ONAMEs
// func
Func *Func // 若Node表示函数,则Func指定函数的定义
// ONAME, OTYPE, OPACK, OLABEL, some OLITERAL
Name *Name
Sym *types.Sym // various
E interface{} // Opt or Val, see methods below
// Various. Usually an offset into a struct. For example:
// - ONAME nodes that refer to local variables use it to identify their stack frame position.
// - ODOT, ODOTPTR, and ORESULT use it to indicate offset relative to their base address.
// - OSTRUCTKEY uses it to store the named field's offset.
// - Named OLITERALs use it to store their ambient iota value.
// - OINLMARK stores an index into the inlTree data structure.
// - OCLOSURE uses it to store ambient iota value, if any.
// Possibly still more uses. If you find any, document them.
Xoffset int64
Pos src.XPos
flags bitset32
Esc uint16 // EscXXX
Op Op // Node的类型,Op 值决定其他字段值
aux uint8 // 可用于保存内置函数make,len等的枚举值
}
decls 函数将源文件中的所有声明语句转换为Node数组。
func (p *noder) decls(decls []syntax.Decl) (l []*Node) {
var cs constState
for _, decl := range decls {
p.setlineno(decl)
switch decl := decl.(type) {
case *syntax.ImportDecl:
p.importDecl(decl)
case *syntax.VarDecl:
l = append(l, p.varDecl(decl)...)
case *syntax.ConstDecl:
l = append(l, p.constDecl(decl, &cs)...)
case *syntax.TypeDecl:
l = append(l, p.typeDecl(decl))
case *syntax.FuncDecl:
l = append(l, p.funcDecl(decl))
default:
panic("unhandled Decl")
}
}
return
}
每个节点都包含了当前节点属性的Op字段,定义在gc/syntax.go中,以O开头。与词法解析阶段中的token相同的是,Op字段也是一个整数。不同的是,每个Op字段都包含了语义信息。
const (
OXXX Op = iota
// names
ONAME // var or func name
// Unnamed arg or return value: f(int, string) (int, error) { etc }
// Also used for a qualified package identifier that hasn't been resolved yet.
ONONAME
OTYPE // type name
OPACK // import
OLITERAL // literal
// expressions
OADD // Left + Right
OSUB // Left - Right
OOR // Left | Right
OXOR // Left ^ Right
OADDSTR // +{List} (string addition, list elements are strings)
OADDR // &Left
OANDAND // Left && Right
........
}
6.类型检查
完成抽象语法树的初步构建后,就进入类型检查阶段遍历节点树并决定节点的类型。
- 检查结构体字段是否是大写可导出的?
- 数组字面量的访问是否超过了其长度?
- 数组的索引是否是正整树?
类型检查的核心逻辑位于gc/typecheck.go中。
7.变量捕获
类型检查阶段完成后,Go语言编译器将对抽象语法树进行分析及重构,从而完成一系列优化。变量捕获主要是针对闭包场景而言的,由于闭包函数中可能引用闭包外的变量,因此变量捕获需要明确在闭包中通过值引用或地址引用的方式来捕获变量。
package main
import "fmt"
func main() {
a:=1
b:=2
go func() {
fmt.Println("==============>")
fmt.Println(a,b)
fmt.Println("==============>")
}()
a=99
}

闭包变量捕获的核心逻辑位于gc/closure.go 的capturevars函数中。
8.函数内联
函数内联指将较小的函数直接组合进调用者的函数。优势在于减少函数调用带来的开销。
// go:noinline 注解的作用就是禁止进行函数内联。函数内联的核心位于gc/inl.gc中。当函数内不有for、range、go、select等语句,该函数不会被内联。递归函数时,也不会发生内联。
package main
import "testing"
//go:noinline
func maxNoinline(a,b int) int {
if a>b {
return a
}
return b
}
var Results int
func BenchmarkMaxNoinline(b *testing.B) {
var r int
for i:=0;i<b.N;i++ {
r = max(-1,i)
}
Results =r
}
go bulid -gcflags="-l" main.go // 也会禁止内联
go tool compile -l main.go
go tool compile -m=2 main.go // 可以打印函数的内联调试信息
9.逃逸分析
逃逸分析是Go语言中重要的优化阶段,用于标识变量内存应该被分配在栈区还是堆区。
GO语言的变量是分配在堆上还栈上。分配时,遵循以下原则:
- 原则1: 指向栈上对象的指针不能被存储到堆中
- 原则2: 指向栈上对象的指针不能超过该栈对象的生命周期
Go语言通过对抽象语法树的静态数据流分析(static data-fow analysis)来实现逃逸分析,这种方式构建了带权重的有向图。
go tool compile -m=2 main.go //可打印逃逸分析信息
逃逸例子:由于a为全局的变量指针,在escape中a=&b,导致a变量超过了b变量的生命周期,则ab都会被分配到堆上。
var a *int
func escape(){
b:=1
a=&b
}
Go 语言采用Bellman Ford 算法遍历查找有向图中权重小于0的节点,核心位于gc/escape.go。
10.闭包重写
闭包变量的捕获作用于是通过指针引用还是值引用的方式传递外部变量。gc/closure.go
11.遍历函数
gc/walk.go
- 在该阶段会识别出声明但是未被使用的变量
- 将某些具体操作转换成具体函数
- 将for...range 转换成更简单的for 循环
12.SSA 生成
将抽象语法树转换为SSA Static Single Assignment静态单赋值。
在SSA生成阶段,每个变量在声明之前否需要被定义,并且每个变量只会被复制一次。
常量传播 Constant Propagation、无效代码清除、消除冗余、强度降低
生成ssa 文件
GOSSAFUNC=main GOS=linux GOARCH=amd64 go tool compile main.go
13.机器码生成-汇编器
在SSA阶段,编译器先执行与特定指令集无关的优化,再执行与特定指令集有关的优化,并最终生成与特定指令集有关的指令和寄存器分配方式。
go tool compile -S main.go
14.机器码生成-链接
链接就是将程序与外部程序组合在一起的过程。分为静态链接和动态链接。
- 静态链接:将程序中使用的所有程序复制到最后的可执行文件中
- 动态链接:在最后的可执行文件中存储动态链接库的位置,并在运行时调用
15.ELF文件解析
ELF(Executable and Linkable Format)是类UNIX操作系统下最常见的可执行且可链接的文件格式。
readelf -h main