1. KNN分类算法:根据距离一个样本最近的k个样本,判断该样本属于那一类;一个样本i与距离样本i最近的k个样本归属于同一类,如果k个样本属于不同的分类,则样本i属于k个中大多数样本所属的那一类
①距离的定义:分为两种
L1:曼哈顿距离
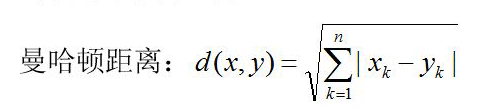
L2:欧氏距离
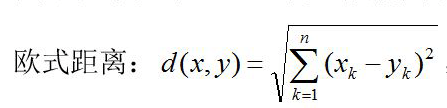

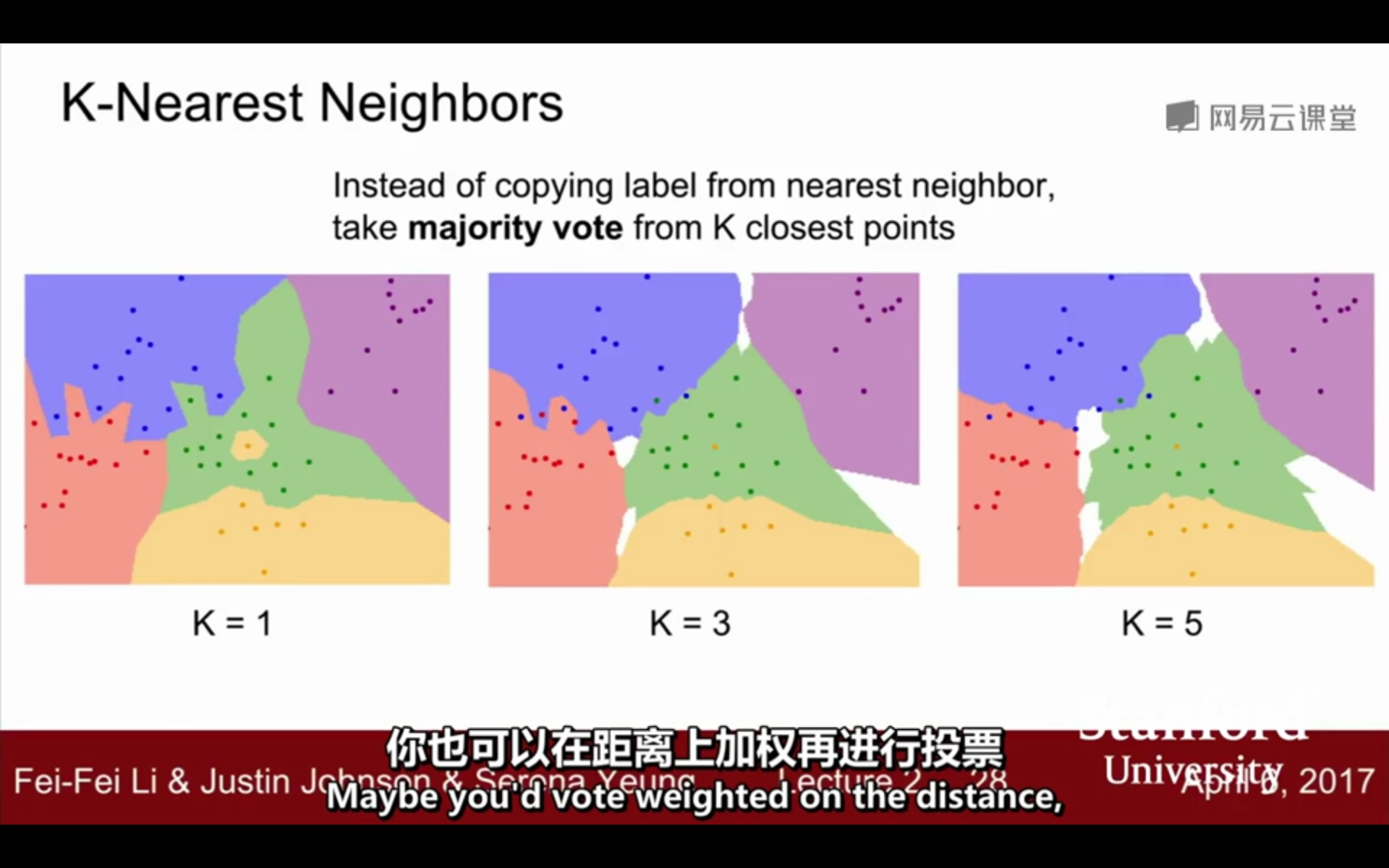
②K:k=1时,退化为最邻近算法;应存在一个k使得算法整体最优
2. 算法过程:
- step.1---初始化距离为最大值
- step.2---计算未知样本和每个训练样本的距离dist
- step.3---得到目前K个最邻近样本中的最大距离maxdist
- step.4---如果dist小于maxdist, 则将训练样本作为K-最近邻样本
- step.5---重复步骤2,3,4,直到未知样本和所有训练样本的距离都算完
- step.6---统计K-最近邻样本中每个类标号出现的次数
- step.7---出现频率最大的类标号最为未知样本的类标号
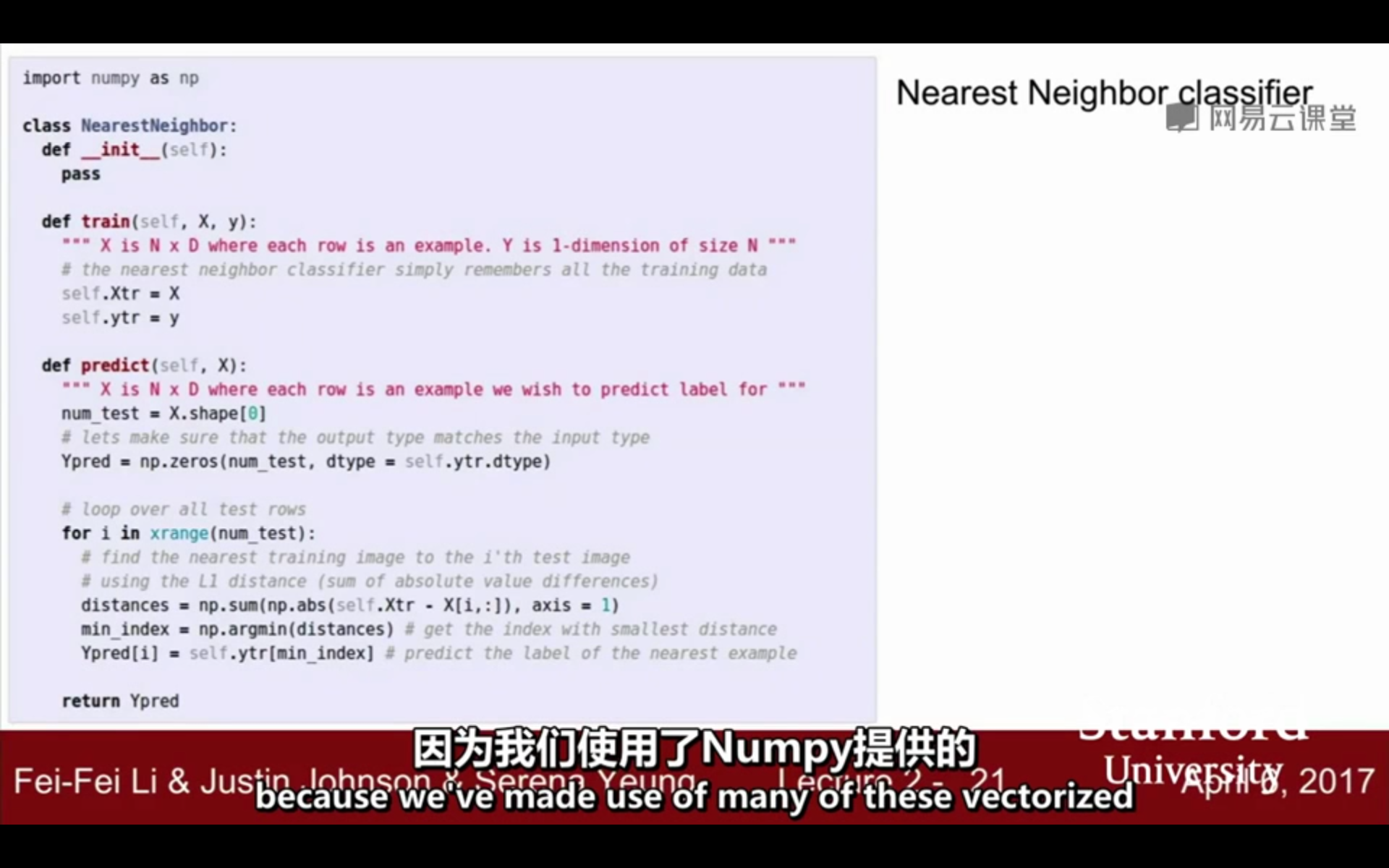
3. 代码: