消息队列的作用:解耦,削峰,异步,顺序性(在一定程度上保证)。
解偶
快递员可以选择自己的时间,把快递放到柜子里,不需要关心小明是否在家。
小明也不需要一直等待给快递员开门,两个人解耦了。
异步
快递员把快递放到柜子里发个信息就可以去送下一件,不需同步等待结果。
削峰
到了双十一,小明一天要到100个快递,由于小明一天只能消化10个快递,剩下的就放在了柜子里,等10天后才拿完。
Kafka架构总览

kafka如何支撑多线程消费?
设置一个组,这个组消费某个主题的消息,组内设置和分区数一样多的消费者,每个消费者消费一个分区。分区数决定了同组消费者个数的上限。如果你的分区数是N,那么最好线程数也保持为N,这样通常能够达到最大的吞吐量。超过N的配置只是浪费系统资源,因为多出的线程不会被分配到任何分区。
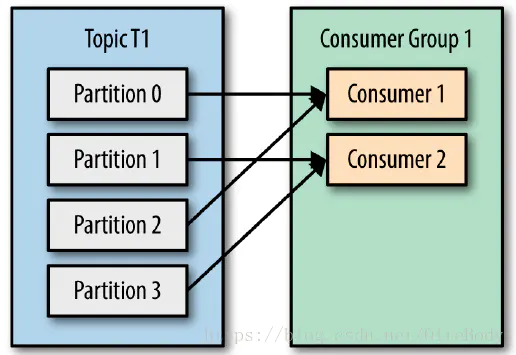
kafka 会不会出现不按顺序消费的情况?
乱序场景一
因为一个topic可以有多个partition,kafka只能保证partition内部有序,partition数量=同一个消费者组中消费者数量时,可能需要顺序的数据分布到了不同的partition,导致处理时乱序
解决方案
1、可以设置topic 有且只有一个partition。
2、同一topic下,再分为各需要顺序消费的业务小类,每个小类消息指定到同一个partition。
乱序场景二
对于同一业务进入了一个消费者组之后,用了多线程来处理消息,会导致消息的乱序
解决方案
消费者内部保持与线程等量的内存队列,相同的业务数据,放到同一个内存队列中,然后线程从对应的内存队列中取出并操作。
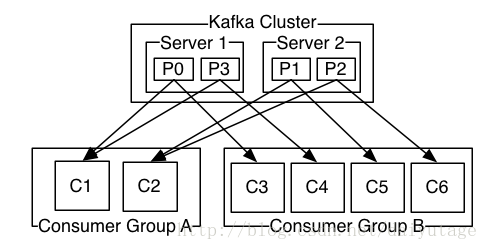
组并发:一个组可以并发消费多个分区。
分区负载均衡:一个分区可以被多个组消费。
组内分工明确:组内消费者只能消费不同的分区。
一个消息对一个组,只会发一次。
broker到消费者采用pull模式:
push模式的目标是尽可能快地传递消息,这样很容易造成消费者来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式可以根据consumer的消费能力以适当的速率消费消息。
pull模式缺点在于,如果broker没有数据,消费者会轮询,忙等待数据直到数据到达,为了避免这种情况,我们允许消费者在pull请求时候使用“long poll”进行阻塞,直到数据到达 。
一个组对每条休息只能消费一次,
Leader和Follower分区

producer 只能往 leader 分区上写数据,消费也只能从leader分区上读,followers 只按顺序从 leader 上复制日志。
3.2 幂等性发送
为实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。对于每个PID,该Producer发送消息的每个<Topic, Partition>都对应一个单调递增的Sequence Number。同样,Broker端也会为每个<PID, Topic, Partition>维护一个序号,并且每Commit一条消息时将其对应序号递增。对于接收的每条消息,如果其序号比Broker维护的序号大1,则Broker会接受它,否则将其丢弃。
如果消息序号比Broker维护的序号差值比一大,说明中间有数据尚未写入,即乱序,此时Broker拒绝该消息,Producer抛出InvalidSequenceNumber
如果消息序号小于等于Broker维护的序号,说明该消息已被保存,即为重复消息,Broker直接丢弃该消息,Producer抛出DuplicateSequenceNumber
Sender发送失败后会重试,这样可以保证每个消息都被发送到broker。
3.3 生产者
生产者发送消息的三种方式:
1. producer.send(record);//Fire-and-forget异步发送,不管发送结果。 2. RecordMetadata result = producer.send(record).get(); //同步发送。 3. producer.send(record,new MyProducerCallBack());//带回调的异步发送 一定需要处理callback的成功或失败逻辑: private static class MyProducerCallBack implements Callback{ @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { if(null != e){ e.printStackTrace(); return; } System.out.println("时间戳,主题,分区,位移: " + recordMetadata.timestamp() + ", " + recordMetadata.topic() + "," + recordMetadata.partition() + " " + recordMetadata.offset()); } }
如果ProducerRecord中指定了Partition,则Partitioner不做任何事情;否则,Partitioner根据消息的key得到一个Partition。这是生产者就知道向哪个Topic下的哪个Partition发送这条消息。

3.4 kafka消费如何保证顺序性
一个 topic,一个 partition,一个 consumer,内部单线程消费,这样的状态数据消费是有序的。但由于单线程吞吐量太低,在数据庞大的实际场景很少采用。
1、生产者在写的时候,可以指定一个 key,比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。(需要保证顺序的几条消息,发送到同一个分区。局部有序)
2、消费者从 partition 中取出来数据的时候,也一定是有顺序的。
3、但是消费者里可能会有多个线程来并发来处理消息。因为如果消费者是单线程消费数据,那么这个吞吐量太低了。而多个线程并发的话,顺序可能就乱掉了。
4、写N个queue,将具有相同key的数据都存储在同一个queue,然后对于N个线程,每个线程分别消费一个queue即可。
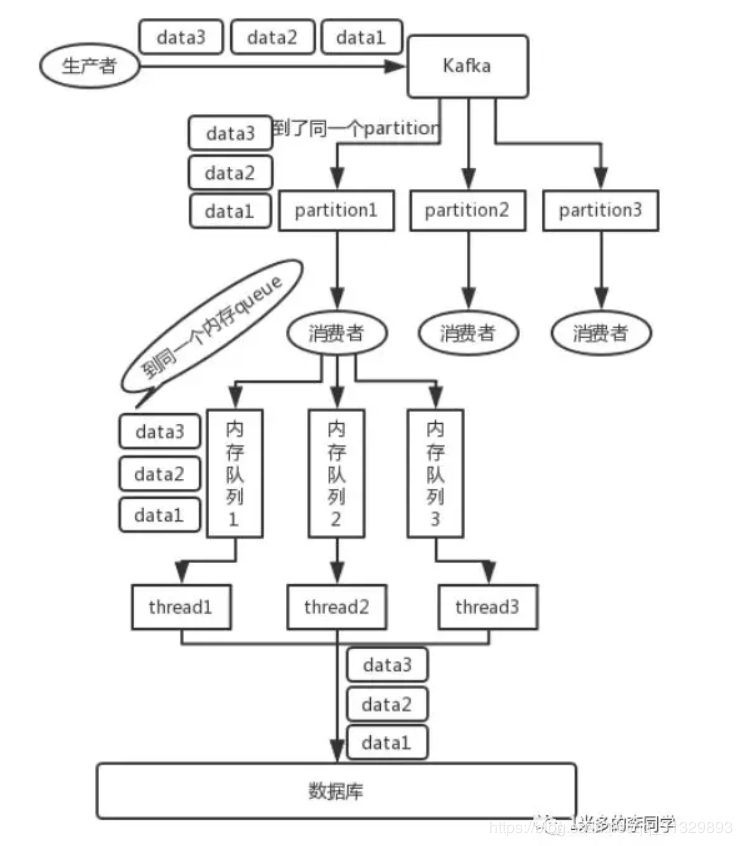
producer发送消息时具体到topic的哪一个partition分区,提供了三种方式
1)指定分区
2)不指定分区,有指定key 则根据key的hash值与分区数进行运算后确定发送到哪个partition分区
3)不指定分区,不指定key,则轮询各分区发送