|
上面的是配置说明,下面的是配置过程:环境背景是两个数据库同步到异地的两个数据库: A-C、B-D。一共用了5台主机,192.168.64.132~134、139、140。zk部署在192.168.64.132~134。 134部署3个实例,132、133各部署一个实例;实例类型为observer。node节点也是在192.168.64.132~134上各配置1个。134配置2个canal实例和manager。192.168.64.132~133 、 192.168.64.139~140分别各部署一个MySQL实例。同步规则:139->132、140->133其他的配置这里不说,在manager上配置的时候,简单说明一下。这里的服务器内部环境配置跳过。 manager配置:
操作步骤:
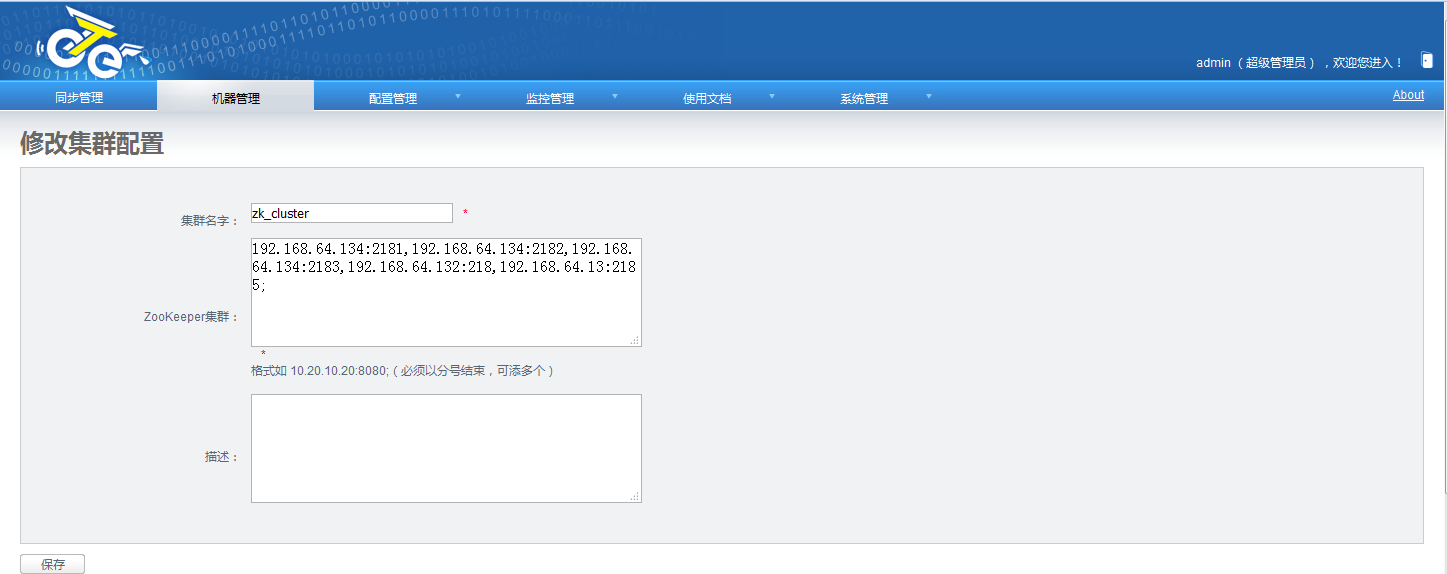
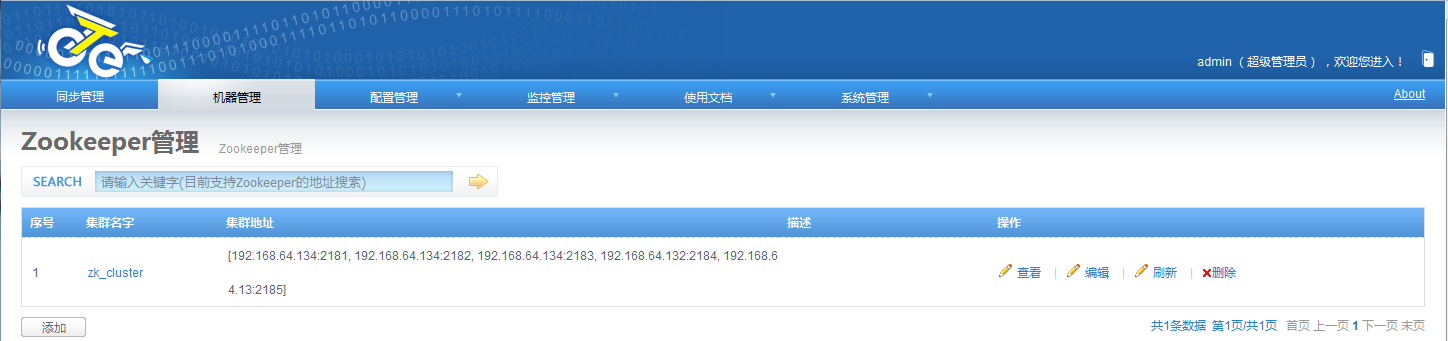
1.添加zk群集
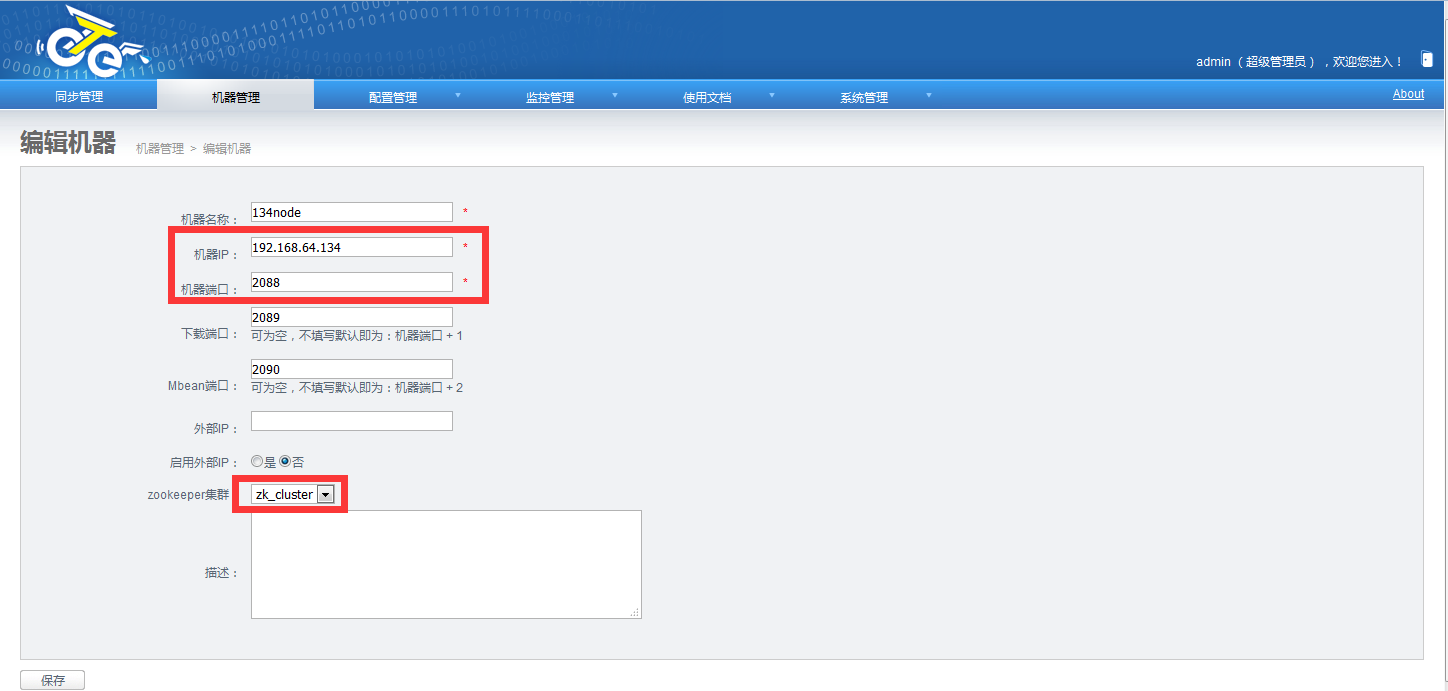
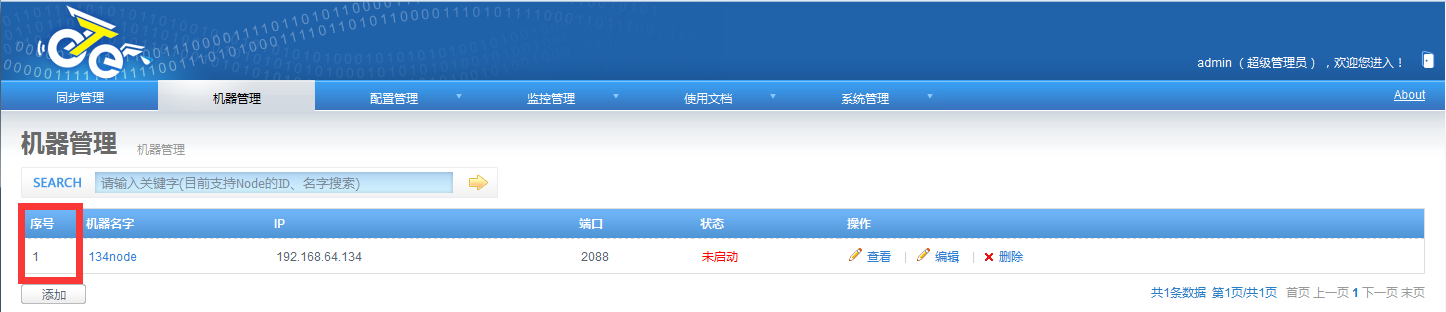
2.添加node
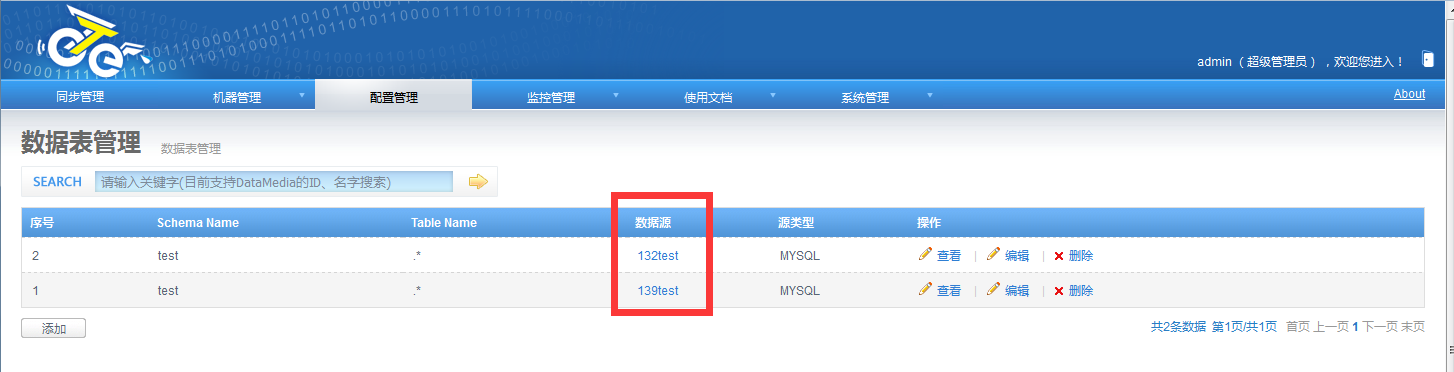
3.添加数据库:
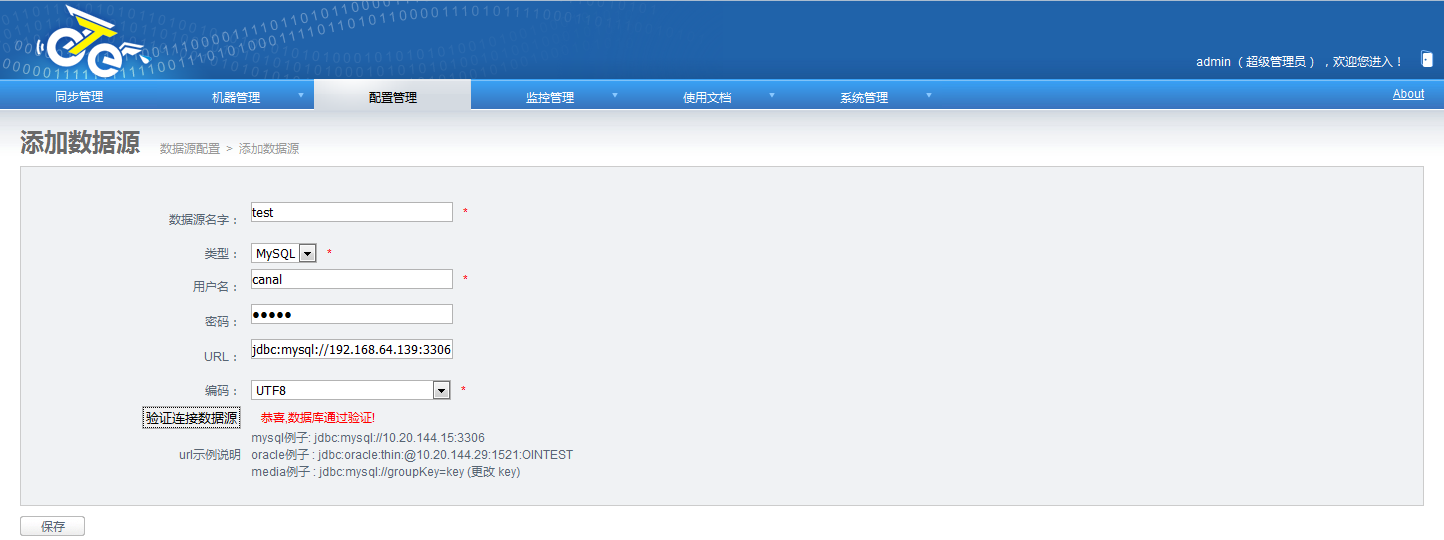
a. 源库 jdbc:mysql://192.168.64.139:3306
b.目标 jdbc:mysql://192.168.64.132:3306
4.添加同步表信息:
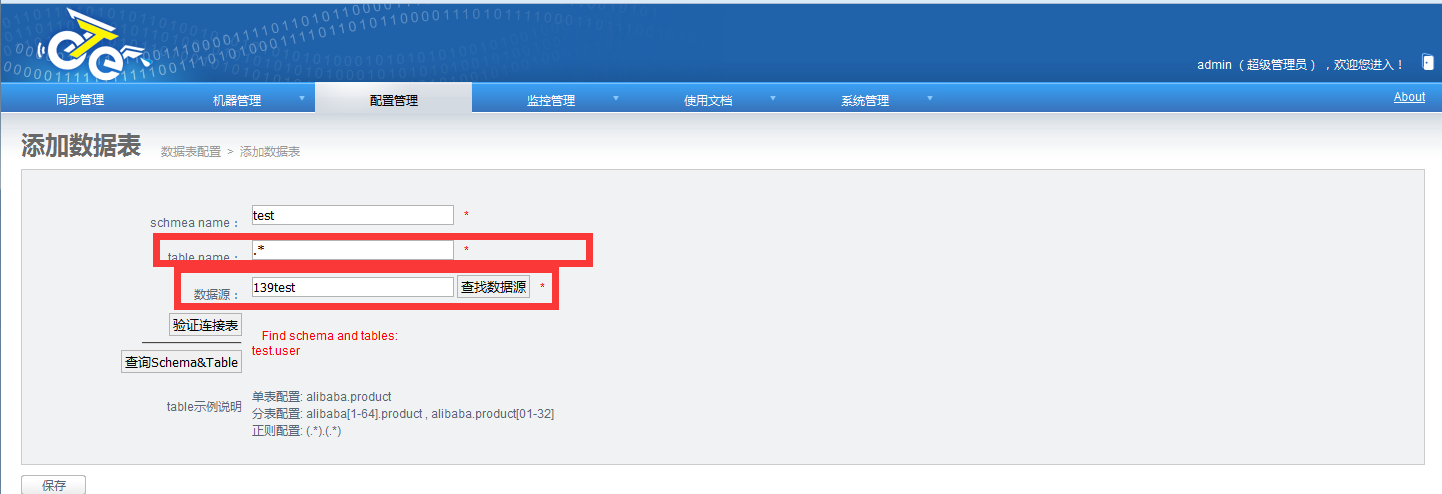
a.源数据表 .*
b.目标数据表 .*
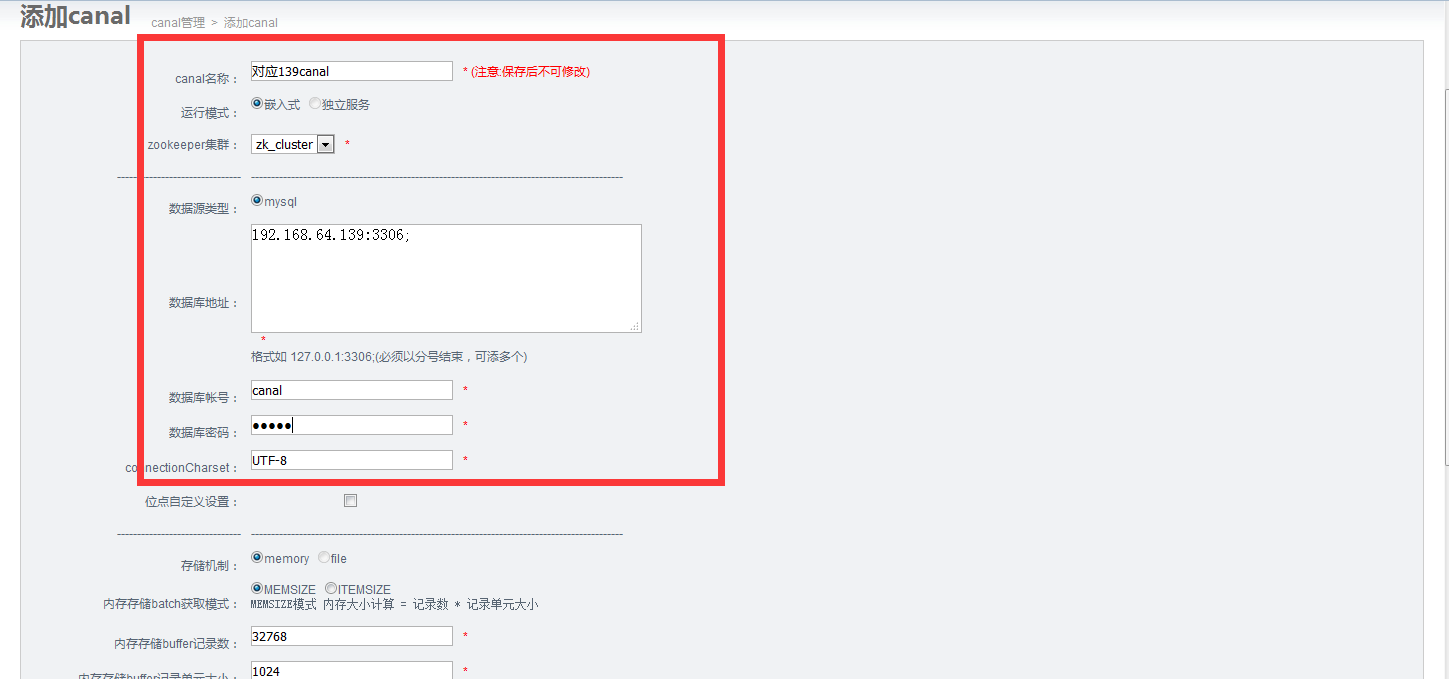
5.添加canal:
a.提供数据库IP信息
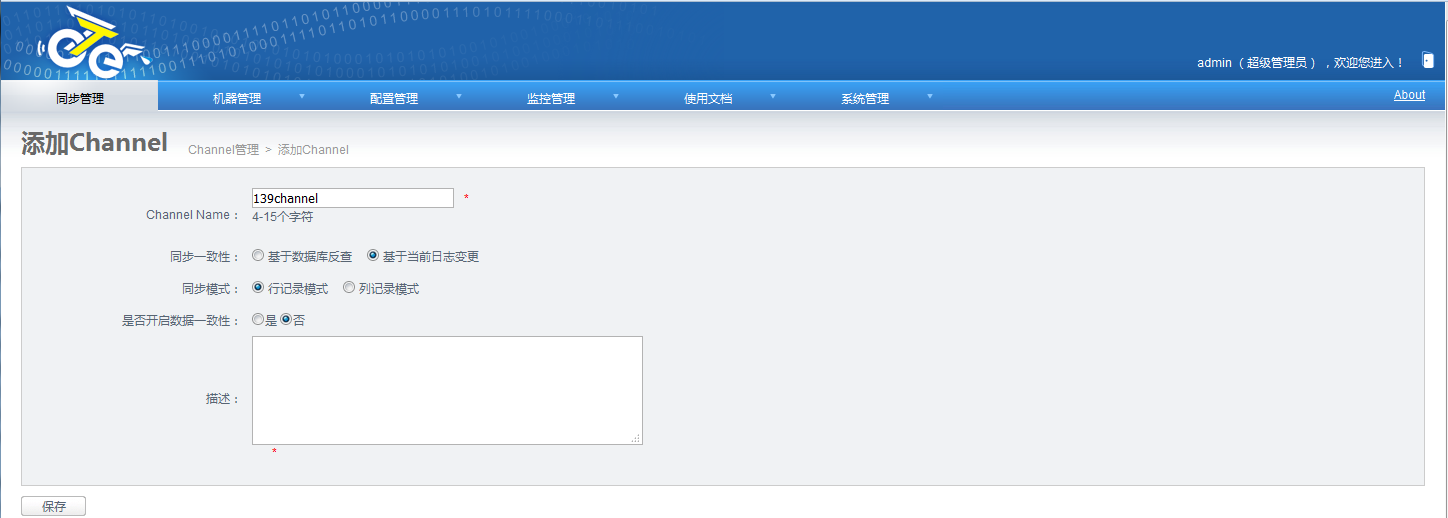
6.添加channel:
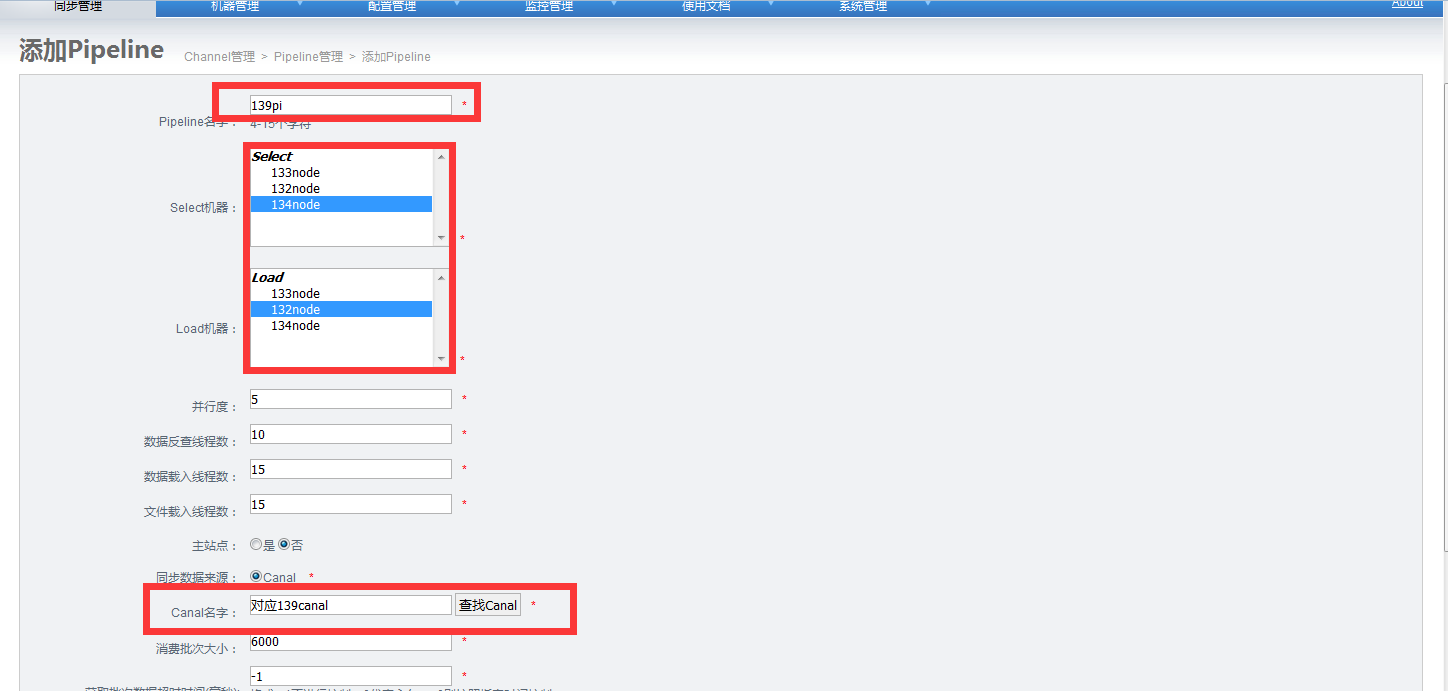
7.添加pipeline:
a.选择node节点
b.选择canal
8.添加同步映射规则
a.定义源表和目标表的同步关系
9.启动
10.测试数据
|
|
添加zk群集:机器管理->添加zookeeper管理: 群集列表以逗号分隔,冒号结束
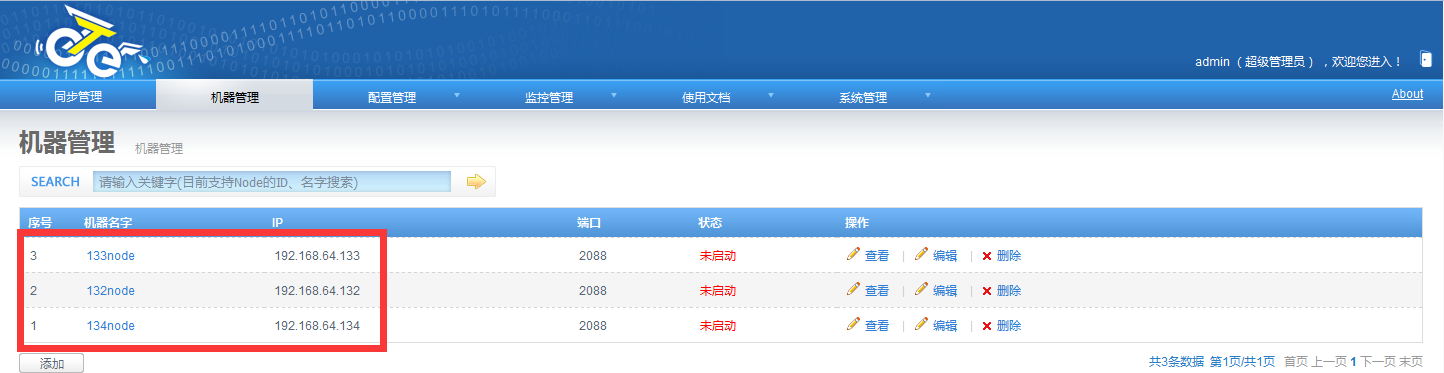
添加node节点:机器管理->添加node管理: 机器端口建议为2088 红色方框中的需要就是我们上面所说的nid标识 我们把nid添加到服务器的node里面吧,启动一下node
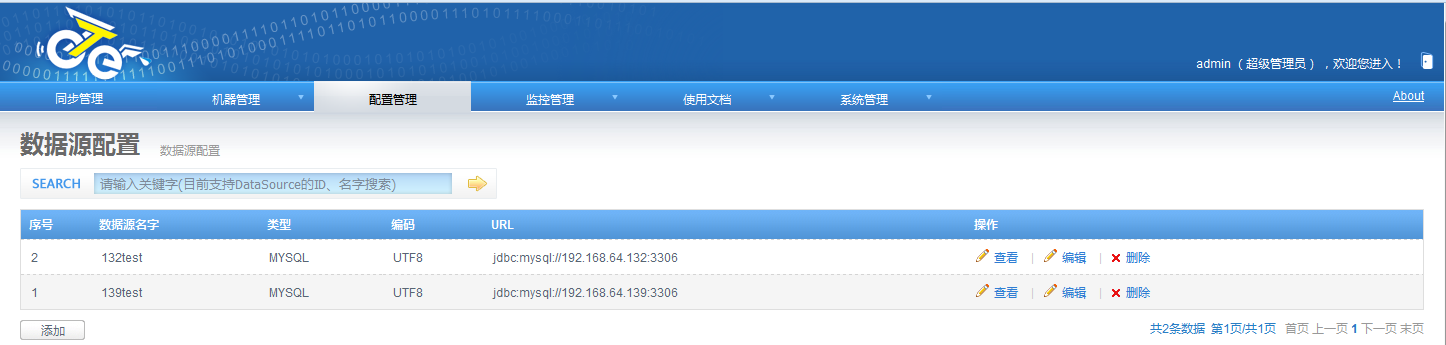
添加数据库:这里使用默认的test库。源和目标库都要有相应的库:
字符集:
[client]
default-character-set=utf8
[mysqld]
character-set-server=utf8
表:
CREATE TABLE `user` (
`id` int(11) NOT NULL auto_increment COMMENT '用户ID',
`name` varchar(50) NOT NULL default '' COMMENT '名称',
`sex` int(1) NOT NULL default '0' COMMENT '0为男,1为女',
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
配置数据表: 无论是目标还是源,都要有一样的库表存在
添加canal:
这里是在一个服务器配置两个canal实例:需要考虑到id、port冲突:
 添加channel:
 添加pipelin:
 添加同步映像规则:
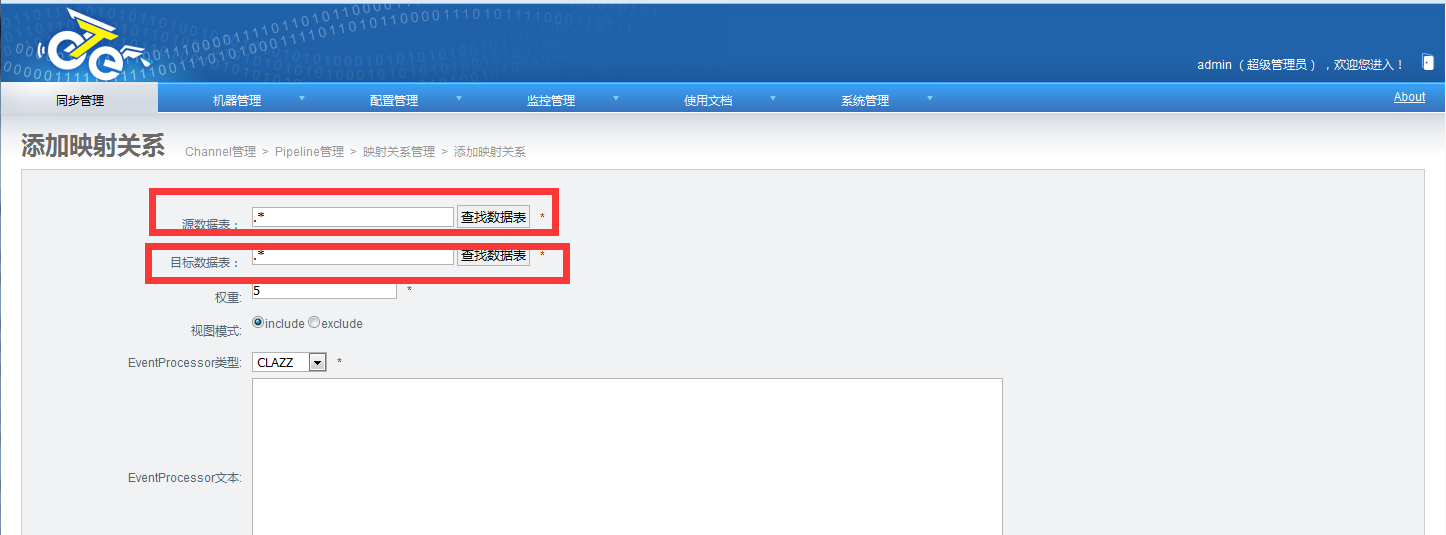 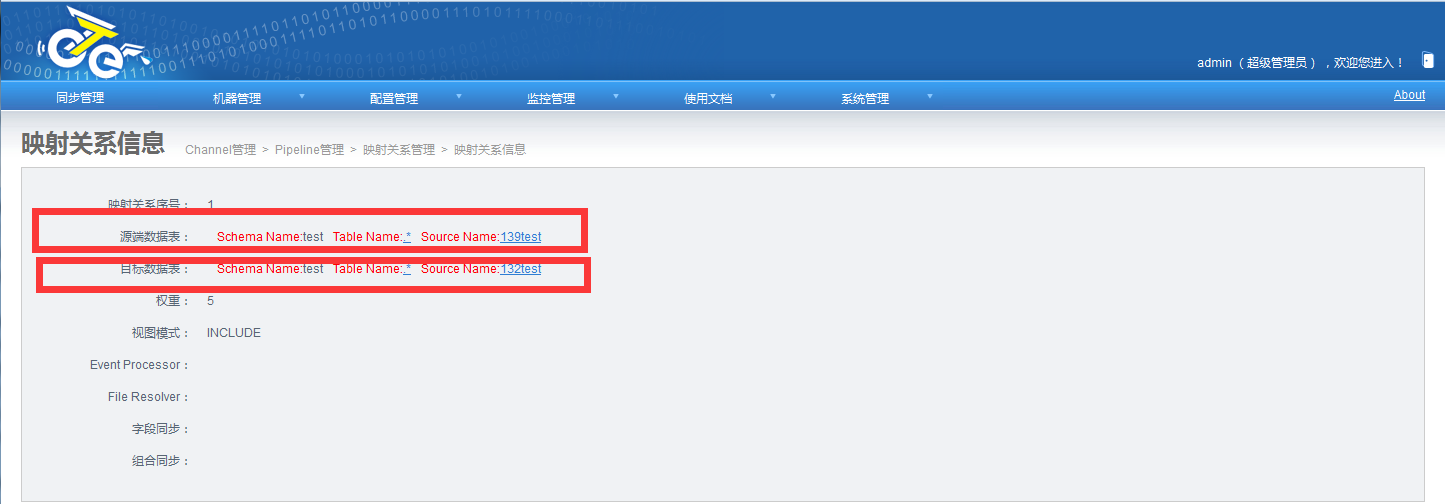 开启同步:
测试数据:
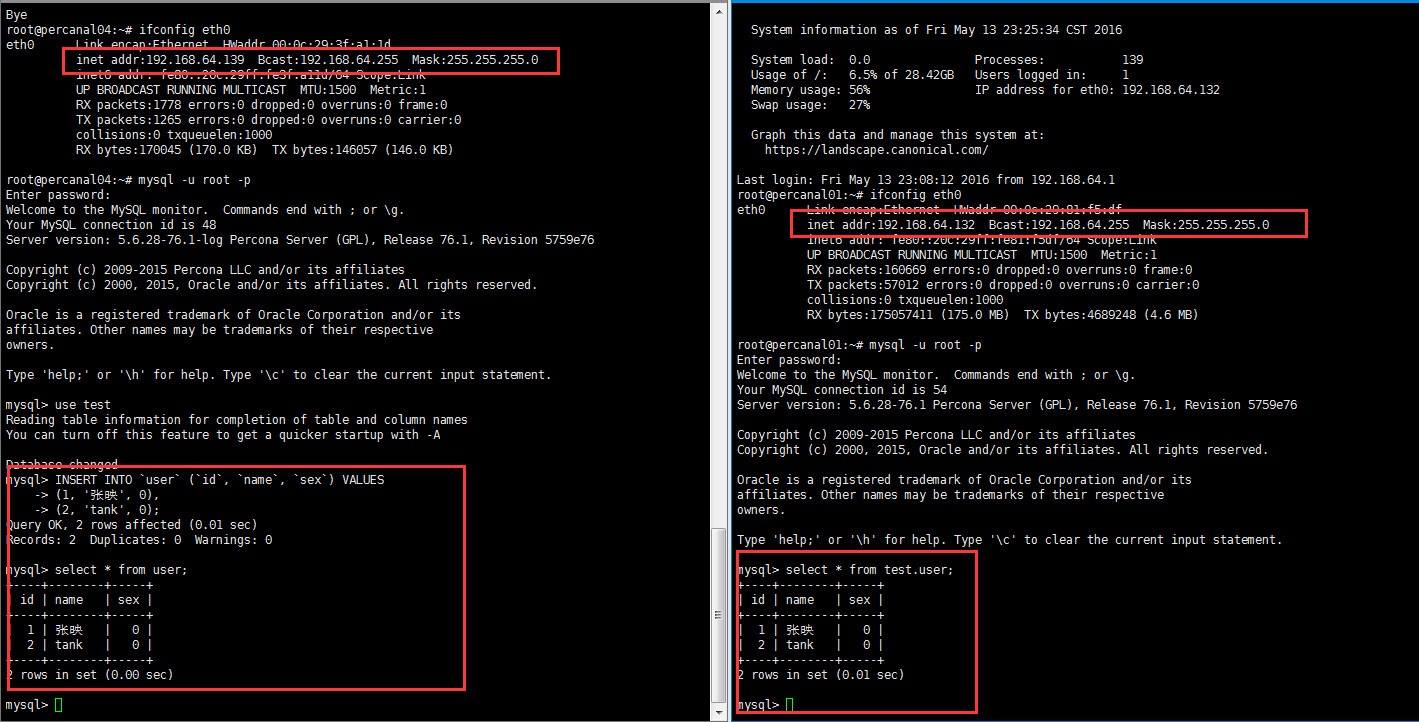 多个实例和单个实例都是一样的,在这个环境中;两个源库,用的是两个canal模拟slave。不同的库关联相对应的canal、node,即可。这里我们又想到,上面的实例只是单个库--->单个库。
若是多个库呢?如何破?其实都是一样的,我们可以在同一个channal--> Pipeline-->映射表;添加映射表即可。也可以做一个库表对应一个channal--> Pipeline-->映射表。方法有很多。
|