
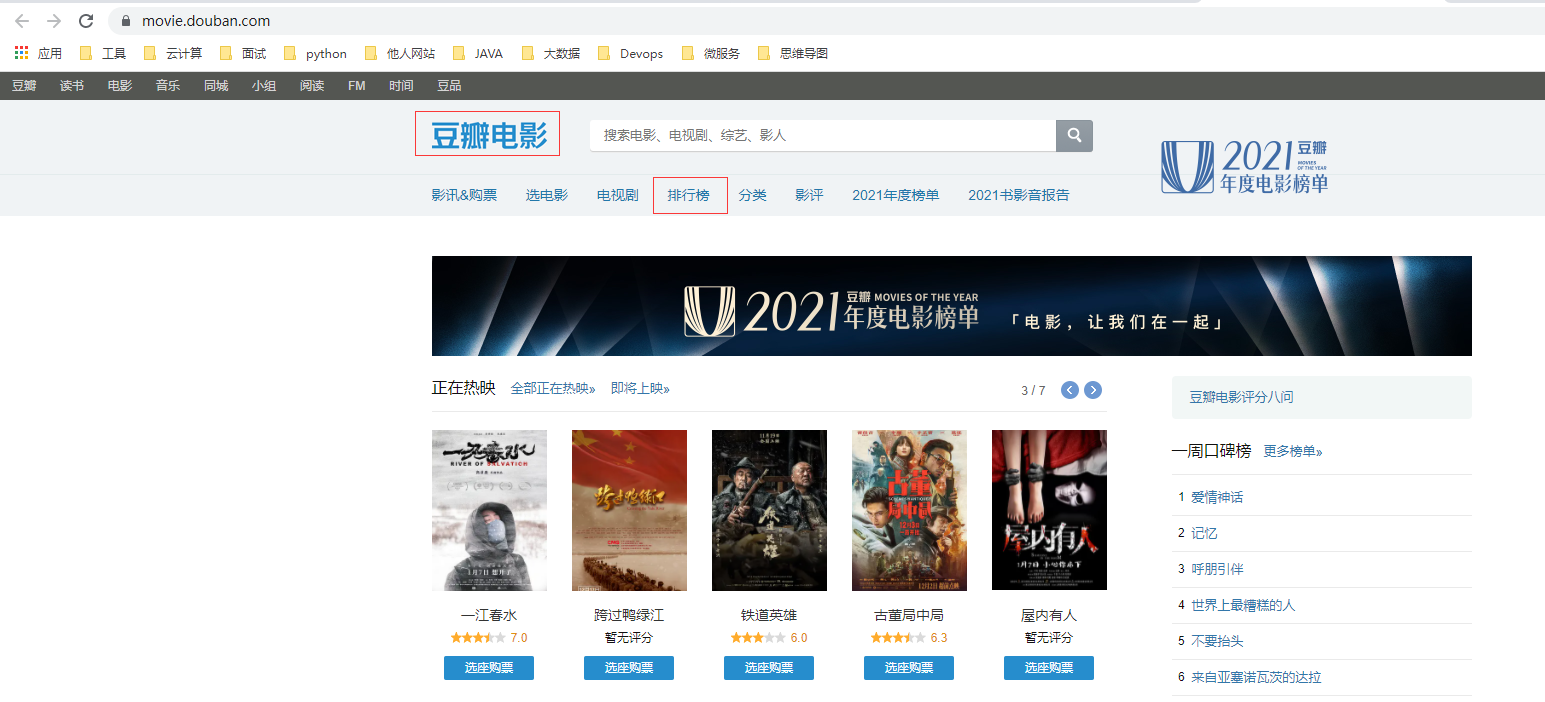
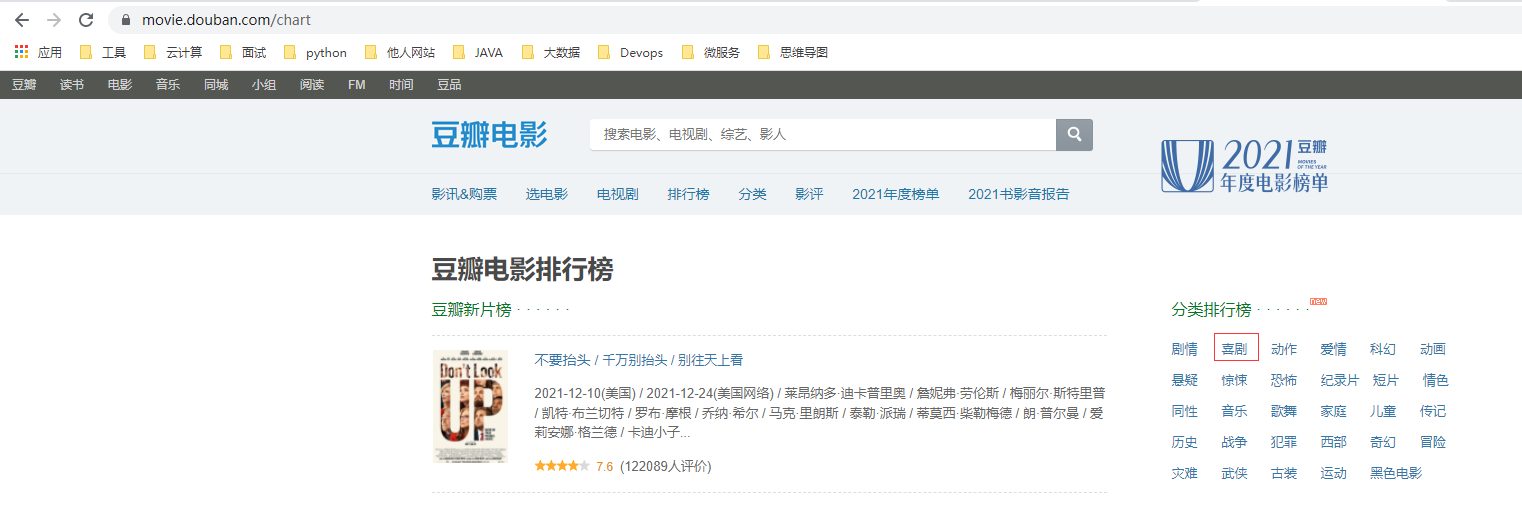
这里可以看到豆瓣对喜剧片的排行。按下键盘的 F12。

对于爬虫来说主要用到前四个选项。
Elements 显示的是脚本执行之后的效果,是实时的状态。个人也可以对其进行改动,获得想要的显示效果。

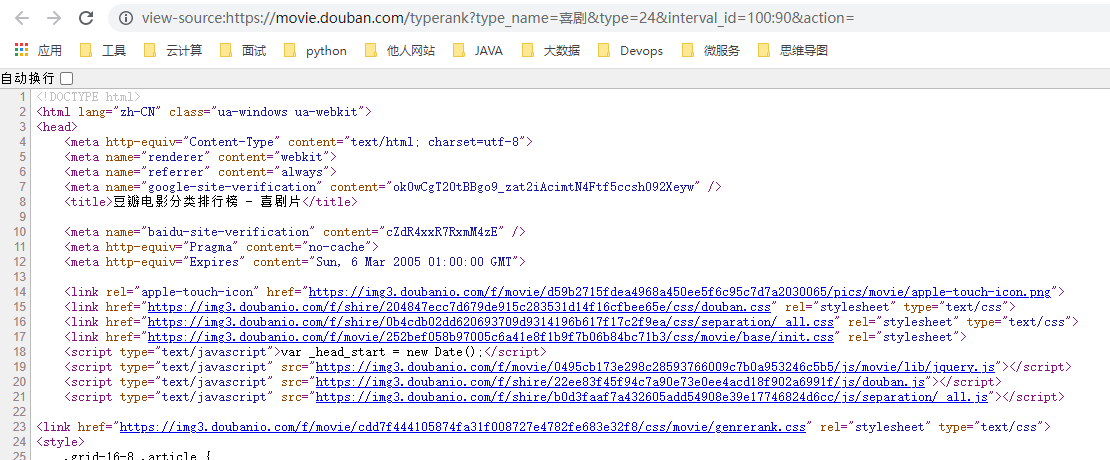
右键可以查看网页源代码。这里显示的是 js 脚本执行前的代码,原始的东西。所以网页源代码显示的是和 Elements 有区别的,我们的 Python 能拿到的就是网页源代码。
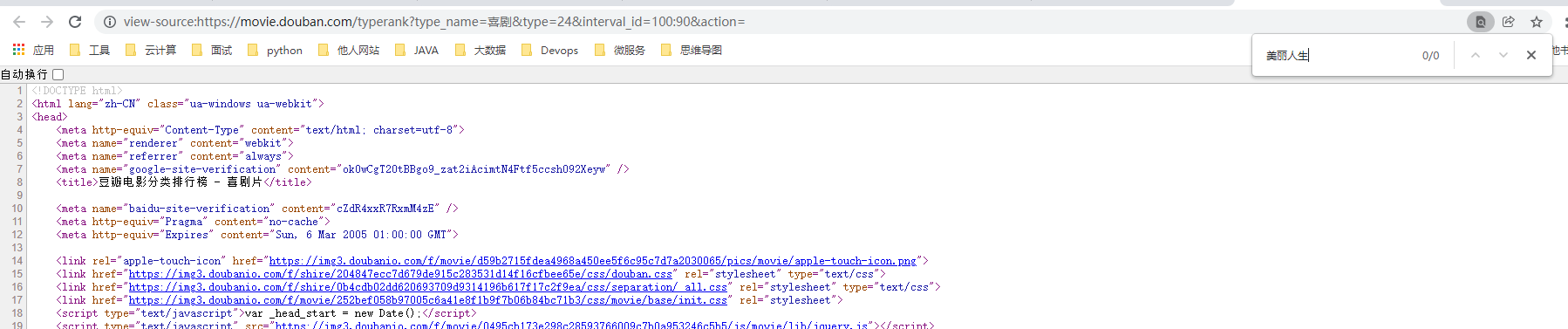
我们在网页源代码里面搜索美丽人生电影的话是搜不到的,那么一定是因为在代码里面有一些脚本重新发送了一些请求来拿到美丽人生的数据。那么这个加载过程在哪里查看呢?在 Network 里。这是一个抓包工具,这里能展示出来页面加载过程中加载的所有网络资源(没数据刷新一下)。
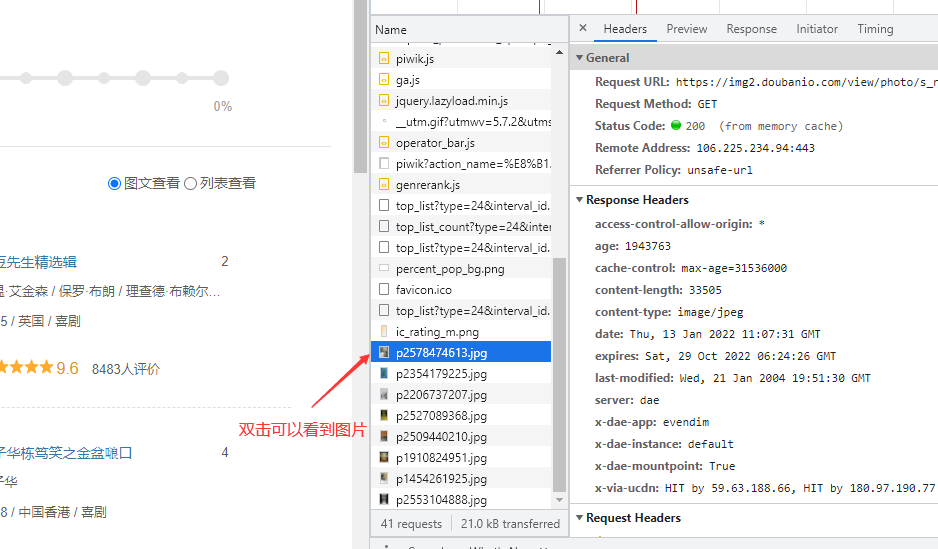
点击 XHR

找找看哪个数据比较多


所以第一次请求豆瓣服务器的时候只有页面源代码,然后在页面源代码里面有一些脚本请求了真正资源的 URL,所以有些时候其实经历了两次请求。但并不是每次都这样,有的时候你想要的东西在页面源代码里有,请求一次就够了。
——————————————————————————————————————————————————————————————————————————
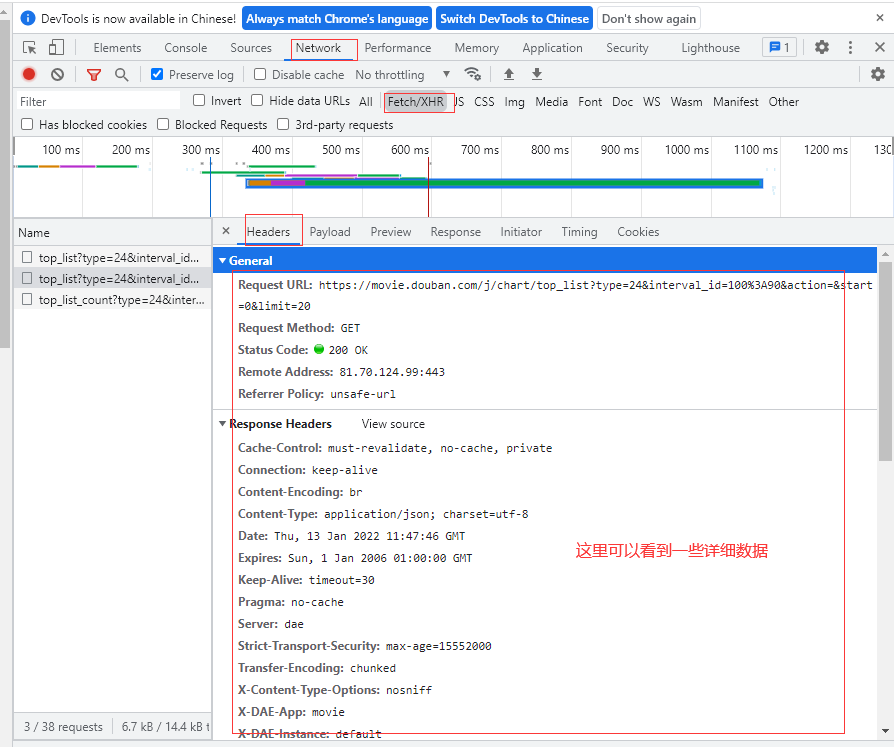

source 可以看到网页加载具体的资源,还可以进行代码调试。

console 里涉及一些 js 的调试,逆向之类的会用到。