有如下R(5,4)的打分矩阵:(“-”表示用户没有打分)
其中打分矩阵R(n,m)是n行和m列,n表示user个数,m行表示item个数
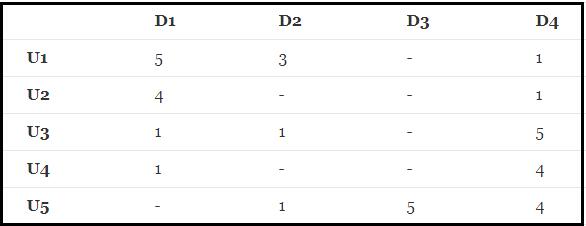
那么,如何根据目前的矩阵R(5,4)如何对未打分的商品进行评分的预测(如何得到分值为0的用户的打分值)?
——矩阵分解的思想可以解决这个问题,其实这种思想可以看作是有监督的机器学习问题(回归问题)。
矩阵R可以近似表示为P与Q的乘积:R(n,m)≈ P(n,K)*Q(K,m)
矩阵分解的过程中,将原始的评分矩阵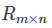 分解成两个矩阵
分解成两个矩阵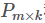 和
和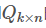 的乘积:
的乘积: 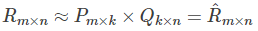
矩阵P(n,K)表示n个user和K个特征之间的关系矩阵,这K个特征是一个中间变量,矩阵Q(K,m)的转置是矩阵Q(m,K),矩阵Q(m,K)表示m个item和K个特征之间的关系矩阵,这里的K值是自己控制的,可以使用交叉验证的方法获得最佳的K值。为了得到近似的R(n,m),必须求出矩阵P和Q,如何求它们呢?
【方法】
1. 首先令![]()
2. 损失函数:使用原始的评分矩阵与重新构建的评分矩阵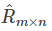 之间的误差的平方作为损失函数,即:
之间的误差的平方作为损失函数,即:
如果R(i,j)已知,则R(i,j)的误差平方和为: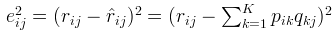
最终,需要求解所有的非“-”项的损失之和的最小值: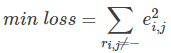
3. 使用梯度下降法获得修正的p和q分量:
- 求解损失函数的负梯度:
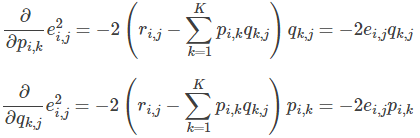
- 根据负梯度的方向更新变量:

4. 不停迭代直到算法最终收敛(直到sum(e^2) <=阈值)
(Plus:为了防止过拟合,增加正则化项)
【加入正则项的损失函数求解】
1. 首先令![]()
2. 通常在求解的过程中,为了能够有较好的泛化能力,会在损失函数中加入正则项,以对参数进行约束,加入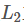 正则的损失函数为:
正则的损失函数为:
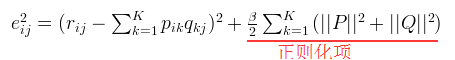
也即:
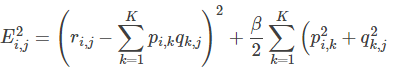
3. 使用梯度下降法获得修正的p和q分量:
- 求解损失函数的负梯度:
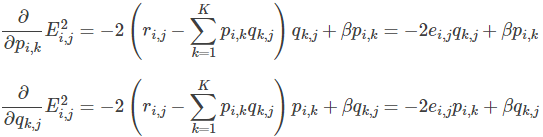
- 根据负梯度的方向更新变量:

4. 不停迭代直到算法最终收敛(直到sum(e^2) <=阈值)
【预测】利用上述的过程,我们可以得到矩阵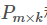 和
和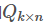 ,这样便可以为用户 i 对商品 j 进行打分:
,这样便可以为用户 i 对商品 j 进行打分:
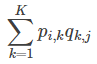
【Python代码实现如下】(基于Python 3.X ;使用正则项)
1 # !/usr/bin/env python 2 # encoding: utf-8 3 __author__ = 'Scarlett' 4 #矩阵分解在打分预估系统中得到了成熟的发展和应用 5 # from pylab import * 6 import matplotlib.pyplot as plt 7 from math import pow 8 import numpy 9 10 11 def matrix_factorization(R,P,Q,K,steps=5000,alpha=0.0002,beta=0.02): 12 Q=Q.T # .T操作表示矩阵的转置 13 result=[] 14 for step in range(steps): 15 for i in range(len(R)): 16 for j in range(len(R[i])): 17 if R[i][j]>0: 18 eij=R[i][j]-numpy.dot(P[i,:],Q[:,j]) # .dot(P,Q) 表示矩阵内积 19 for k in range(K): 20 P[i][k]=P[i][k]+alpha*(2*eij*Q[k][j]-beta*P[i][k]) 21 Q[k][j]=Q[k][j]+alpha*(2*eij*P[i][k]-beta*Q[k][j]) 22 eR=numpy.dot(P,Q) 23 e=0 24 for i in range(len(R)): 25 for j in range(len(R[i])): 26 if R[i][j]>0: 27 e=e+pow(R[i][j]-numpy.dot(P[i,:],Q[:,j]),2) 28 for k in range(K): 29 e=e+(beta/2)*(pow(P[i][k],2)+pow(Q[k][j],2)) 30 result.append(e) 31 if e<0.001: 32 break 33 return P,Q.T,result 34 35 if __name__ == '__main__': 36 R=[ 37 [5,3,0,1], 38 [4,0,0,1], 39 [1,1,0,5], 40 [1,0,0,4], 41 [0,1,5,4] 42 ] 43 44 R=numpy.array(R) 45 46 N=len(R) 47 M=len(R[0]) 48 K=2 49 50 P=numpy.random.rand(N,K) #随机生成一个 N行 K列的矩阵 51 Q=numpy.random.rand(M,K) #随机生成一个 M行 K列的矩阵 52 53 nP,nQ,result=matrix_factorization(R,P,Q,K) 54 print("原始的评分矩阵R为: ",R) 55 R_MF=numpy.dot(nP,nQ.T) 56 print("经过MF算法填充0处评分值后的评分矩阵R_MF为: ",R_MF) 57 58 #-------------损失函数的收敛曲线图--------------- 59 60 n=len(result) 61 x=range(n) 62 plt.plot(x,result,color='r',linewidth=3) 63 plt.title("Convergence curve") 64 plt.xlabel("generation") 65 plt.ylabel("loss") 66 plt.show()
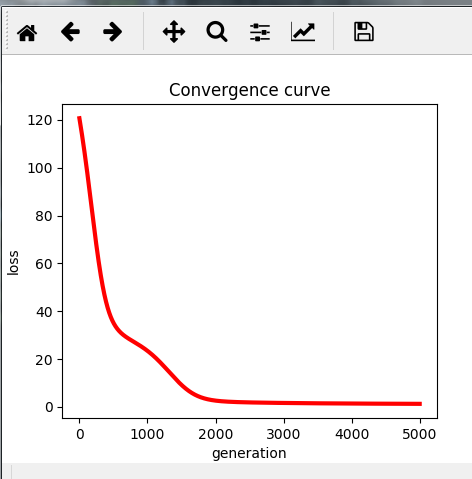
运行结果如下:


损失函数的收敛曲线图:
【代码的GitHub地址】
https://github.com/shenxiaolinZERO/CoolRSer/blob/master/CoolRSer/MatrixFactorization.py
【Reference】
1、 Matrix Factorization: A Simple Tutorial and Implementation in Python