一、Hadoop压缩配置
修改Hadoop集群具有Snappy压缩方式: 查看hadoop支持的压缩方式 [kris@hadoop101 datas]$ hadoop checknative 将编译好的支持Snappy压缩的hadoop-2.7.2.tar.gz包导入到hadoop101的/opt/software中 1.解压hadoop-2.7.2.tar.gz到当前路径 [kris@hadoop101 software]$ tar -zxvf hadoop-2.7.2.tar.gz 2.进入到/opt/software/hadoop-2.7.2/lib/native路径可以看到支持Snappy压缩的动态链接库 [kris@hadoop101 native]$ pwd /opt/software/hadoop-2.7.2/lib/native [kris@hadoop101 native]$ ll 总用量 5188 -rw-r--r--. 1 kris kris 1210260 9月 1 2017 libhadoop.a -rw-r--r--. 1 kris kris 1487268 9月 1 2017 libhadooppipes.a lrwxrwxrwx. 1 kris kris 18 2月 18 11:51 libhadoop.so -> libhadoop.so.1.0.0 -rwxr-xr-x. 1 kris kris 716316 9月 1 2017 libhadoop.so.1.0.0 -rw-r--r--. 1 kris kris 582048 9月 1 2017 libhadooputils.a -rw-r--r--. 1 kris kris 364860 9月 1 2017 libhdfs.a lrwxrwxrwx. 1 kris kris 16 2月 18 11:51 libhdfs.so -> libhdfs.so.0.0.0 -rwxr-xr-x. 1 kris kris 229113 9月 1 2017 libhdfs.so.0.0.0 -rw-r--r--. 1 kris kris 472950 9月 1 2017 libsnappy.a -rwxr-xr-x. 1 kris kris 955 9月 1 2017 libsnappy.la lrwxrwxrwx. 1 kris kris 18 2月 18 11:51 libsnappy.so -> libsnappy.so.1.3.0 lrwxrwxrwx. 1 kris kris 18 2月 18 11:51 libsnappy.so.1 -> libsnappy.so.1.3.0 -rwxr-xr-x. 1 kris kris 228177 9月 1 2017 libsnappy.so.1.3.0 3.拷贝/opt/software/hadoop-2.7.2/lib/native里面的所有内容到开发集群的/opt/module/hadoop-2.7.2/lib/native路径上 [kris@hadoop101 native]$ cp ../native/* /opt/module/hadoop-2.7.2/lib/native/ cp -r native/ /opt/module/hadoop-2.7.2/lib/ 4.分发集群 [kris@hadoop101 lib]$ xsync native/
重新启动hadoop集群和hive
开启Map输出阶段压缩 hive (default)> set hive.exec.compress.intermediate=true; 开启hive中间传输数据压缩功能 hive (default)> set mapreduce.map.output.compress=true; 开启mapreduce中map输出压缩功能 hive (default)> set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec; 设置mapreduce中map输出数据的压缩方式 执行查询语句 hive (default)> select count(ename) name from emp; 开启Reduce输出阶段压缩 hive (default)> set hive.exec.compress.output=true; 开启hive最终输出数据压缩功能 hive (default)> set mapreduce.output.fileoutputformat.compress=true; 开启mapreduce最终输出数据压缩 hive (default)> set mapreduce.output.fileoutputformat.codec=org.apache.hadoop.io.compress.SnappyCodec; 设置mapreduce最终数据输出压缩方式 hive (default)> set mapreduce.output.fileoutputformat.type=BLOCK; 设置mapreduce最终数据输出压缩为块压缩 测试一下输出结果是否是压缩文件 hive (default)> 0: jdbc:hive2://hadoop101:10000> insert overwrite local directory '/opt/module/datas/distributed-result' select * from emp distribute by deptno sort by empno desc;
二、文件存储格式
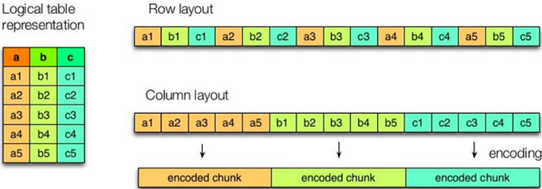
左边为逻辑表,右边第一个为行式存储,第二个为列式存储。
行存储的特点:查询满足条件的一整行数据的时,只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
列存储的特点:
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;
ORC和PARQUET是基于列式存储的。
TextFile格式默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
每个Orc文件由1个或多个stripe组成,每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer;
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
hive (default)> create table log_text(track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string) > row format delimited fields terminated by ' ' > stored as textfile; OK Time taken: 0.685 seconds hive (default)> load data local inpath '/opt/module/datas/log.data' into table log_text; Loading data to table default.log_text Table default.log_text stats: [numFiles=1, totalSize=19014993] OK Time taken: 1.12 seconds hive (default)> dfs -du -h /user/hive/warehouse/log_text; 18.1 M /user/hive/warehouse/log_text/log.data hive (default)> create table log_orc( > track_time string, url string, session_id string, referer string, ip string, end_user_id string, ciry_id string) > row format delimited fields terminated by '/t' > stored as orc; OK Time taken: 0.087 seconds hive (default)> insert into table log_orc select * from log_text; hive (default)> dfs -du -h /user/hive/warehouse/log_orc; 2.8 M /user/hive/warehouse/log_orc/000000_0 hive (default)> create table log_parquet( > track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string) > row format delimited fields terminated by '/t' > stored as parquet; OK Time taken: 1.004 seconds hive (default)> insert into table log_parquet select * from log_text; //insert overwrite table log_parquet select * from log_text; hive (default)> dfs -du -h /user/hive/warehouse/log_parquet; 13.1 M /user/hive/warehouse/log_parquet/000000_0 0: jdbc:hive2://hadoop101:10000> select count(*) from log_text; +---------+--+ | _c0 | +---------+--+ | 100000 | +---------+--+ 1 row selected (18.222 seconds) 0: jdbc:hive2://hadoop101:10000> select count(*) from log_orc; 1 row selected (17.129 seconds) 0: jdbc:hive2://hadoop101:10000> select count(*) from log_parquet; 1 row selected (18.133 seconds) ive (default)> create table log_orc_none( > track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string) > row format delimited fields terminated by ' ' > stored as orc tblproperties ("org.compress"="NONE"); hive (default)> insert overwrite table log_orc_none select * from log_text; hive (default)> dfs -du -h /user/hive/warehouse/log_orc_none; 2.8 M /user/hive/warehouse/log_orc_none/000000_0 hive (default)> create table log_orc_snappy( > track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string) > row format delimited fields terminated by ' ' > stored as orc tblproperties ("orc.compress"="SNAPPY"); OK Time taken: 0.145 seconds hive (default)> insert overwrite table log_orc_snappy select * from log_text; hive (default)> dfs -du -h /user/hive/warehouse/log_orc_snappy; 3.8 M /user/hive/warehouse/log_orc_snappy/000000_0 默认创建的ORC存储方式,导入数据后的大小为:2.8 M /user/hive/warehouse/log_orc/000000 比Snappy压缩的还小。原因是orc存储文件默认采用ZLIB压缩,ZLIB采用的是deflate压缩算法。比snappy压缩的小。 存储方式和压缩总结 在实际的项目开发当中,hive表的数据存储格式一般选择:orc或parquet。压缩方式一般选择snappy,lzo。