1、Kafka背景
* LinkedIn开发,2011年成为Apache的一个开源项目
* 2012年,成为Apache的一个顶级项目
* 基于java和Scala编写, 基于发布-订阅模型的消息系统(离线-在线消费都支持)
* 分布式、高性能(o(1)的磁盘数据结构完成消息持久化,OS:预读后写;磁盘顺序访问>内存随机访问),具有容错性(数据以Partion形式保存在磁盘、并在集群内复制)
* kafka需要构建在zookeeper之上,当前已经能够和storm,spark集成,构成flume-kafka-storm/spark常见流式数据分析
2、什么是消息系统(消息缓冲队列)
消息系统,不同应用程序间的数据媒介;(消息缓冲+投递,data pipeline)
也就是说,应用程序只负责发出,收取数据,而不用再关心消息的传递
消息队列的工作模式两种:1)点对点queuing 2)发布-订阅(publish-subscribe)
* 点对点消息系统
1)多个消费者
2)特定消息,最多只能被1个消费者消费
3)消息一旦被消费,则从消息队列中移出(没有持久化)
* 发布-订阅消息系统
1)发布者针对topic发布消息(topic是逻辑概念,对消息类型的划分)
2)消费者,订阅1个或多个topic
3) 同一消息,可以被多个消费者消费
3、Kafka基本概念
kafka集群,对外提供4种角色(4类API)
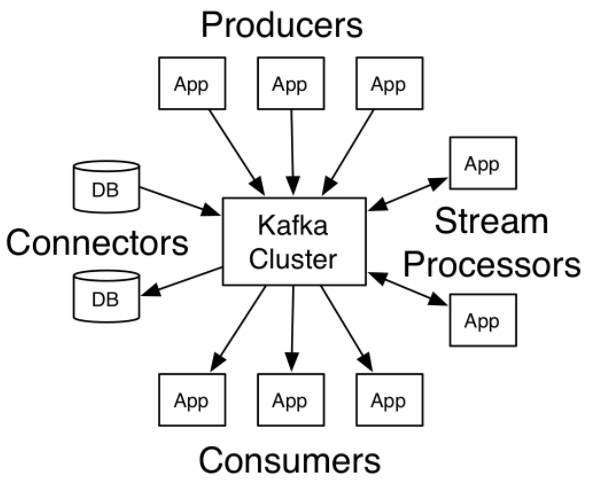
1)producer: Topic的生产者
2)Consumer: Topic的订阅者
3)Connector: Topic的生产者或订阅者,通过该角色对接已有的DB系统
4)Stream Processer: 订阅1个或多个Topic, 对信息处理后,发布1个或多个Topic(消息处理)
Kafka系统基本概念
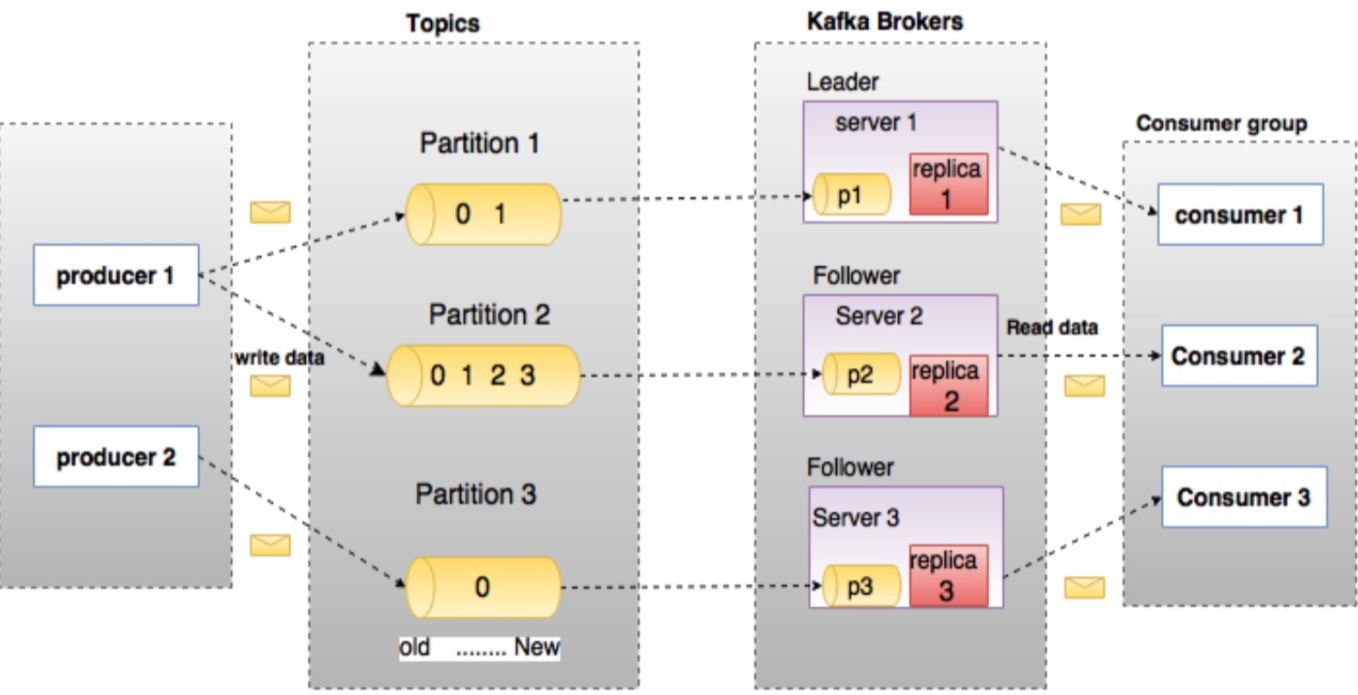
1)Topic、Partition
Topic 逻辑概念,生产者发布消息时指定的一个feed名称(发布哪一个Topic)
Partition Topic在Kafka集群上的物理实现(一定程度的保证有序,一定程度的负载均衡)
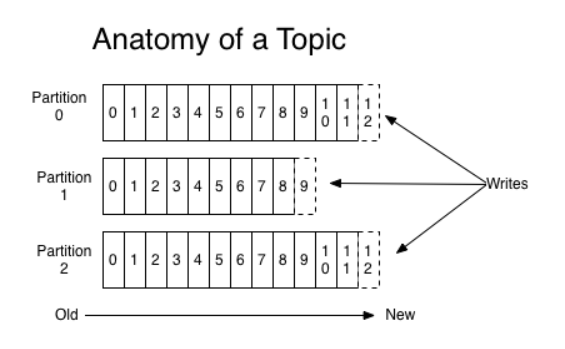
1个Topic有1个或多个Partition组成,消息以顺序不可变的方式进入Partition
Partition中的每个消息,都一个唯一的序列id,称为offset,无论是否被消费,消息都会被保留一段可配置的时间
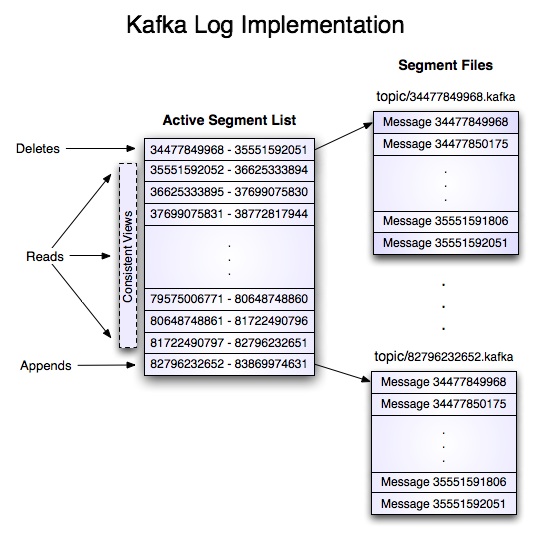
1个partition (物理上对应1个文件夹),将由多个大小相同的segment文件组成,目的在于分段后的快速查找‘
2)Broker、Kafka集群
Broker,Kafka集群中的每台机器,就是1个Broker, 通过BrokerID标识区分
每个Broker上包含每个Tpoic的0个或多个Partition
Partition、Broker、Leader、follower、Partition Replication分区副本
* 1个Topic可能会有1个或N个Partition
* 每个Partition都会落地到某一个Broker上(磁盘上的1个文件夹下多个segment文件)
* 每个Partition还会在其他Broker上,进行备份
* 每个主Partitio所在的Server, 称为Leader(broker); 该Partiton的副本所在的其他Server,称为Follower
* Leader对外提供该Partiton的读写服务,Follower可以理解为1个消费者,拉取leader机器上的主partition数据,并更新自己的数据进行持久化
* 当某个Topic的某个Partition的Leader节点故障,通过zookeeper从1个ISR列表中选取1个Follower,变为Leader
* 每个Broker,都有机会成为某个Topic下某个Partition的Leader,这样做到load balance
Broker如何承载同一Topic的多个Partition
Kafka的理念是尽量将Partition在broker上均匀分布,避免出现热点
1)1个Topic有N个Partition,集群中有N个broker = 每个Broker承载1个Partition
2) 1个Topic有N个partition, 集群中有N+M个broker = 前N个Broker每个承载1个Partition
3) 1个Topic有N个Partition, 集群中有M个broker (M<N) = Partition在M个Broker上均匀分配,每个Broker可能会承载1个或多个partition(不推荐,热点问题)
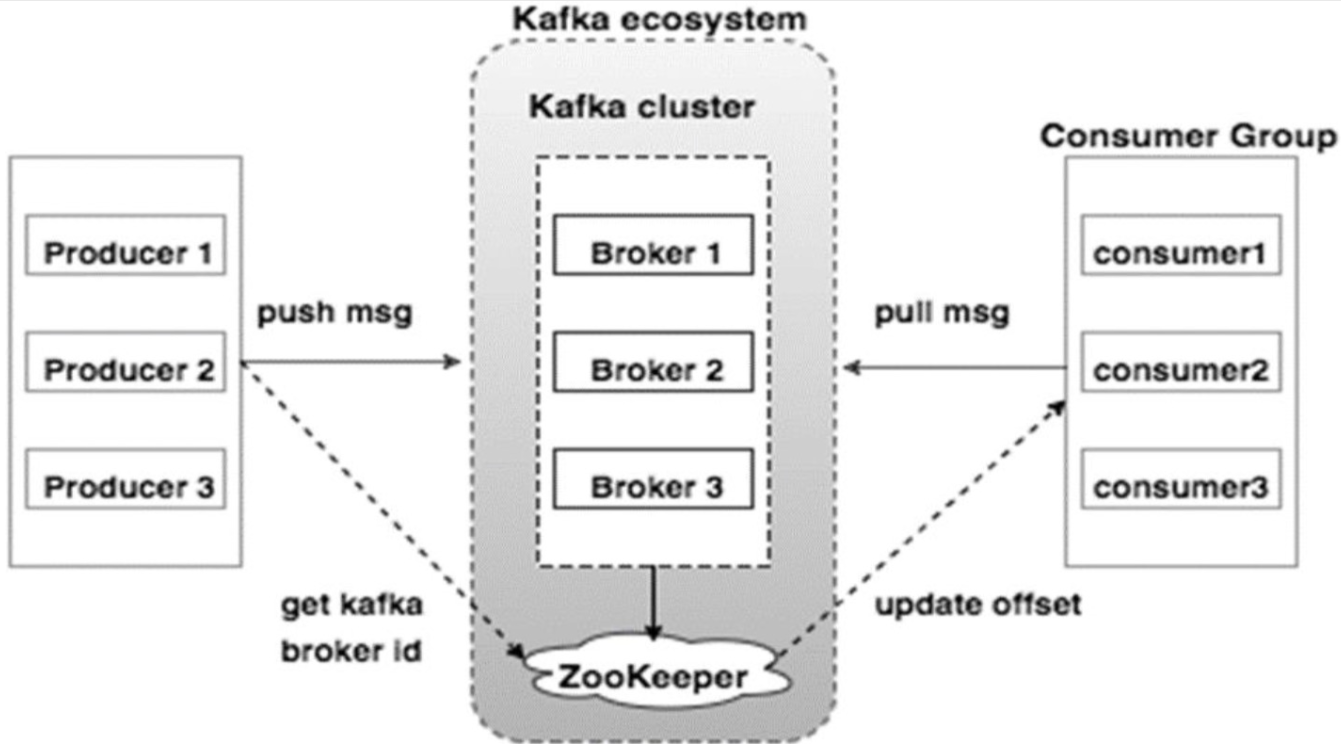
Broker
kafka broker无状态,由zookeeper来维护集群信息
某一个broker, 是否能够成为某个Topic下的某个Partition的Leader,由zookeeper选举实现
单个broker能处理 数十万/秒 的读写请求,即便保存了TB级别的数据也不影响处理性能
Producer
向1个或多个Topic中发布消息
Producer负责确定每条消息,应该发布给哪一个Broker, 也可以指定发送给该Topic下的哪一个Partition (round robin/基于key的hash)
Producer发布的消息,会被追加到某个Partition的最后1个segment文件的最后
Producer发布消息时,可以不等待来自broker的确认,以broker可以处理的速度发送消息
Consumer
订阅1个或多个Topic, 通过pull方式从broker拉取订阅的数据
Consumer需要自己记录读取到了partition中的哪个offset (消息序列号),并最终向zookeeper中写入这个信息
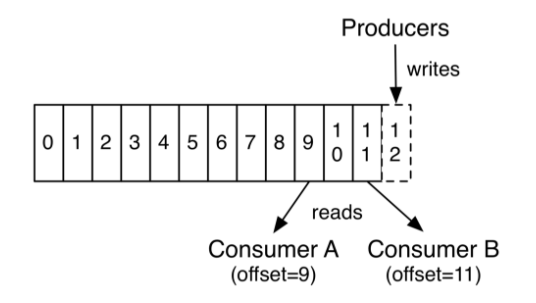
ConsumerGroup
每个ConsumerGroup由1个或多个Consumer组成
Topic下的消息发送给ConsumerGroup后,在ConsumerGroup内部决定每条消息应该由哪个Consumer来处理
同一条消息,不会发送给同一Group下的两个或多个Consumer
1个Partition同一时刻,只能服务于1个Group中的1个Consumer (同组的Consumer不能同时读写同一个partition)
重点: 同组的Consumer,每人分担一部分Partion的消息处理,没有两个人处理同一个Partition的情况

3)kafka的消息发布-订阅流程
消息发布:
1、Producer同步或异步(batching)的向Topic发送消息(指定发往该Topic下的某一个partition所在的Leader broker,并发出)
2、Broker,根据配置,将该Topic的消息存储到指定的partition上
kafka会保证partition的负载均衡(Topic的消息会分散在各个partition上)
消息订阅:
1、Consumer订阅1个或多个Topic
2、Kafka向Consumer提供该Topic的当前offset (多个partition的当前offset), 并将offset保存在zookeeper中
3、Consumer定期请求Topic(100ms)的新消息
4、kafka收到新消息,就将消息发送给Consumer
5、Consumer收到消息,并进行处理
6、Consumer向Kafka发送offset ack(说明自己已经处理完offset前的所有信息)
7、Kafka收到offset ack后,在zookeeper中更新该Consumer的offset (该Consumer已经处理到了哪里)
8、Consume可以随时回退,跳转到某个Topic的期望offset,并读取所有后续消息
4)Consumer Group下的消息发布
具有相同group id的多个Consumer被认为是1个组,Consumer Group出现后的消息发布:
1、生产者定期向Topic发送消息
2、Broker根据配置,将Topic中的消息,存储到指定的PartITon上
3、单个Consumer, 以名为Group-1的Group ID订阅Topic
4、Kafka将Consumer加入Consumer Group, 并启动共享模式(确定该Consumer消费Topic下的哪几个Partition)
5、新消息发送给该Consumer Group中负责相应Partition的Consumer (每个Consumer消费的partition没有重叠)
6、当加入同一Consumer Group的Consumer个数 > Topic的Partition个数
新加入的Consumer不会受到任何消息(前面的Consumer已经分担完了该Topic下的所有partition),直到已经存在的Consumer取消订阅
5)zookeeper的角色
1、 Kafka在Zookeeper中存储基本元数据,例如:Topic,broker,消费者偏移(队列读取器)等信息
2、 由于Zookeeper本身也是集群架构,因此zookeeper故障不会影响Kafka集群的状态
3、zookeeper的故障,不会影响Kafka的集群状态, 也也是kafka零停机时间的原因
4、 broker中谁是某个partition的Leader,也通过zookeeper的选举机制完成
Kafka Design要点
关于数据拷贝
1、零用户空间拷贝 (通过OS加速数据拷贝)
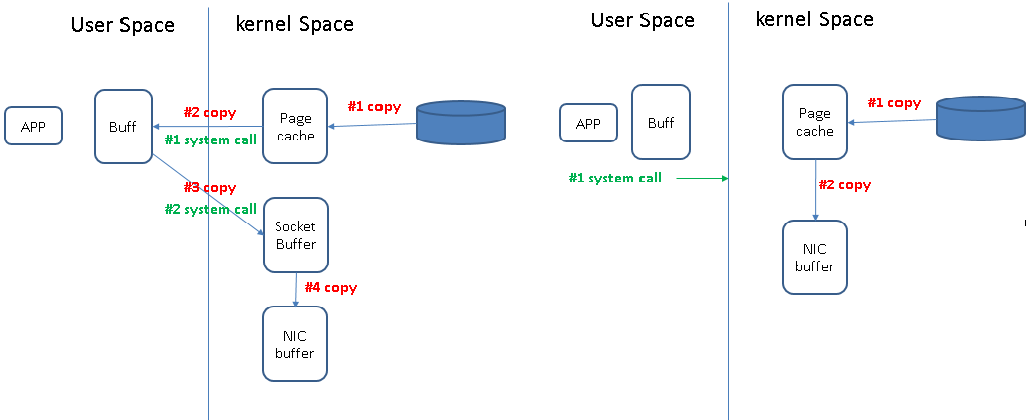
参考:Efficient data transfer through zero copy
2、端到端批量压缩(从占用网络带宽角度优化)
核心思路:对每条消息进行压缩(Client) -> 对多条消息进行压缩(Kafka)
依据: 消息之间会存在一定的冗余性(同类消息间,冗余性更高)
Kafka的做法:
1)Client将一批消息组织在一起进行压缩, 并发送压缩后的消息
2)消息头中会有1个compression-attributes字节,表示是否压缩,采用哪种压缩等
3)compression-attributes字节之前会有1个magic字节,1表示该消息为压缩消息

4)消息以压缩的形式,写入partition并保留
5)消息以压缩的形式,发送给Consumer
6)Consumer解压缩,得到一批消息
7)支持的压缩协议:GZIP, LZ4, Snappy
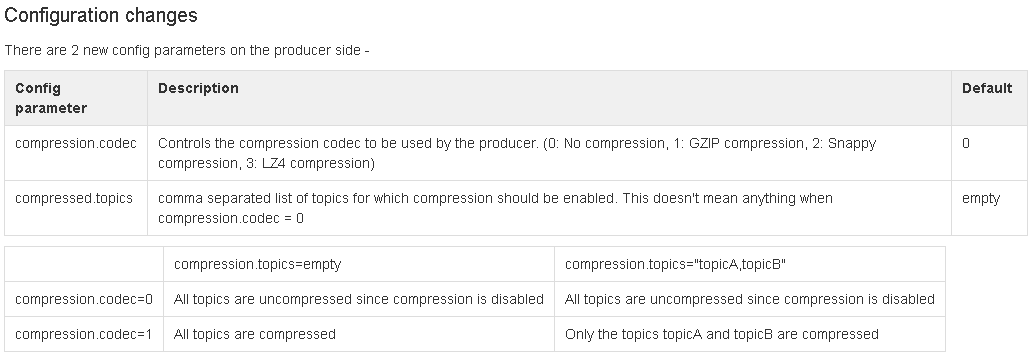
端到端批量压缩出现后,Producer端配置的变化
3、Producer相关的design
1)Producer在发送消息前,会发送meat-data request; Broker会应答该请求,说明当前哪些broker alive, broker是哪个Topic下哪个Partition的Leader节点
2) producer将消息以Topic的形式,直接发送给该Partition的Leader节点(broker),中间没有任何的路由层(Client控制消息发送给哪一个Partition)
Producer端的负载均衡
3)Producer控制消息发往哪一个Partition有两种方式:
* 随机负载均衡
* Partition方法(kafka以API形式,将该接口开放给Client, Client覆写partition functiontion即可): Client可以指定消息中的某个字段,userid等为key; 然后基于key做hash, 得到该消息应该发往哪一个Partition
Producer异步发送模式 (批量发送,batching)
* Producer能够以异步(批量 batching) 的方式发送消息
* 通过Producer端的配置项来开启batching发送(2个参数:最多积累的消息数 64k,最大积累时间 10ms)
4、Consumer相关的design
push & pull
在这点上kafka采用了和传统message system相同的设计
1) Producer主动push消息到kafka
2) Consumer主动Pull消息到本地
3)那么当kafka中没有消息的时候,Consumer不断的去Pull,是不是有点太徒劳?
4)为了避免没有消息时的无效pull, Consumer提供了一些可配置参数,让Consumer可以处于一个long poll的阻塞状态,直到有新的消息到来(消息累计到给定的字节)
offline data load 离线系统使用kafka
1)Kafka将消息持久化保存一段可配置时间
2)HDFS,Data warehouse类似的离线系统,就同样可以从kafka中获取数据
3)HDFS为例,可以将每个Topic下的每个partition, 交给1个map任务,批量获取数据并进行reduce处理
4)最大限度的做到并行
5、消息传输设计 message delivery semantics
一般来说,消息投递有3种设计:
1)At most once - 消息最多投递1次,问题:消息丢失后,不会重新投递
2)At least once - 消息不会丢失,可能会重新投递
3)Exactly once -
消息投递,本质上可以拆分为两个问题:
1)如何保证producer发布的消息,顺利被broker保存;
2)如何保证broker发出的消息,顺利被Consumer接收;
Producer消息发布的保证:
1)0.11.0.0版本的kafka及以前,Producer没有收到消息被提交到broker的response, 只能重发,会出现相同消息重复写入的问题
2)0.11.0.0之后版本的kafka, Producer被赋予了ID,信息被赋予了offset, kafka内部机制来保证producer重发的信息不会重复写入
3)0.11.0.0之后版本的kafka, Producer向多个Topic下的partition发布消息,有了transaction-like的保证机制(要么全部成功,要么全部不写入)
4)Producer此时有了更多的自主性,通过参数acks可以配置自己是否需要在接收到broker的ack后才发送下一条消息
acks = 0 不需要接收来自broker的“消息已提交”的确认信息
acks = 1 leader将消息写入本地log后就向Producer发送“消息已提交”的确认信息
acks = all leader等待所有follower (其实是等待所有in-sync状态的ISR中的节点) 将消息复制到本地log后才向producer发送“消息已提交”的确认信息
6、Replication
Partition在Kafka集群中的复制
1)partition是复制的基本单位
2)每个partition有1个leader节点,以及0个或多个follower节点
3)replication factor参数,包括leader以及follower节点个数
4)partition的leader节点,对外提供消息读写服务
5)follower节点,将作为leader节点上partition的Consumer存在(主动拉取消息)
Kafka集群定义某个broker是否还live的两个条件 (in sync节点)
1)broker要和zookeeper保持心跳
2)作为follower的broker, 不能和leader上partition的消息相差太多(not fall too far bebind)
3)Leader节点,将维护一个in sync节点集合(ISR),并且动态维护,并记录到zookeeper中
在ISR中的follower broker, 才有资格参与leader失效后的新leader选举
f+1, 允许最大失效节点数f
4)通过replica.lag.time.max.ms 参数来决定follower节点是否已经落后太多
5)committed消息的严格定义:所有in sync节点都已经将该消息,添加到了本地的备份partition中
6)只要还有1个in sync节点存在,消息就不会丢弃
7、unclean leader election: what if they all die?
当某个partition的leader节点及follower节点都故障,leader节点如何选择?
一般来说,有两个选择
1)等待ISR中的1个节点恢复,并将该节点选择为leader
2) 选择第一个恢复的节点作为leader, 该节点可能并不在ISR中
默认情况下,kafka使用第二种策略,但可以通过配置unclean.leader.election.enable选项为disable来禁止